昨天用了蠢方法搜尋並取回每檔個股的每日收盤資訊及對應的移動平均指標,結果打了大量的 API ,相當沒有效率,今天就來談談如何優化。
查找官方文件,發現一個可以支援在一個 API 呼叫,執行多筆搜尋的方法:msearch。直接用範例來看看:
GET /_msearch
{"index" : "history-prices-daily"}
{"size": 1, "query" : {"match" : { "stock_id": "1101" }}, "sort" : [{ "date":{"order" : "desc"}}]}
{"index" : "tech-analysis-sma"}
{"size": 1, "query" : {"match" : { "stock_id": "1101" }}, "sort" : [{ "date":{"order" : "desc"}}]}
從上方的 DSL 可以腦補出我的目的是要查找出在 2 個 Index 中,股號為 1101 的 Document。 結果如下:
Multi Search API 的 Request Body 格式為:
header\n
body\n
header\n
body\n
因此可以透過打一次 API 就取回大量的資料。
老套路啦!一樣嘗試在 Python 用 DSL 實作:
from elasticsearch import Elasticsearch
from elasticsearch_dsl import MultiSearch, Search
es = Elasticsearch(end_point, http_auth=(UserName, Password))
ms_daily = MultiSearch(using=es)
for stock_id in stock_id_list:
ms_daily = ms_daily.add(Search(index='history-prices-daily').\
query("match", stock_id=stock_id).\
source(includes=['stock_id', 'date', 'close', 'volume']).\
sort({"date": {"order": "desc"}}))
responses_daily = ms_daily.execute()
doc_fields_daily = {}
for response in responses_daily:
source_data = response["hits"]["hits"][0]["_source"]
for key in source_data:
try:
doc_fields_daily[key] = np.append(doc_fields_daily[key], source_data[key])
except KeyError:
doc_fields_daily[key] = np.array([source_data[key]])
elastic_df_daily = pd.DataFrame(doc_fields_daily)
print(elastic_df_daily)
上面的搜尋中,我透過 source filtering 取回部份的 Document 欄位。結果如下圖: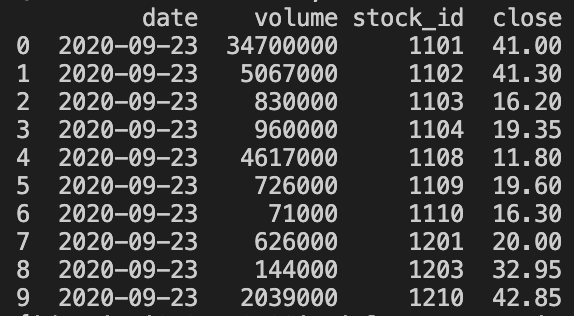
透過 Multi Search ,整體的搜尋效率大幅的提高! 今天持續小步推進,明天加油。

