前文介紹了 Transformer 的構架,現在老頭就從輸入端到輸出端依序的來介紹它的運作細節。行文的順序和論文的順序有些不同,如果讀者要參考原論文的話,必須跳著看,在此就向大家說聲抱歉了!
先來看看編碼器輸入前的資料處理,包括 Input Embedding (Output Embedding) 和 Positional Encoding。(其實解碼器的輸入之前,也需經過相同的處理)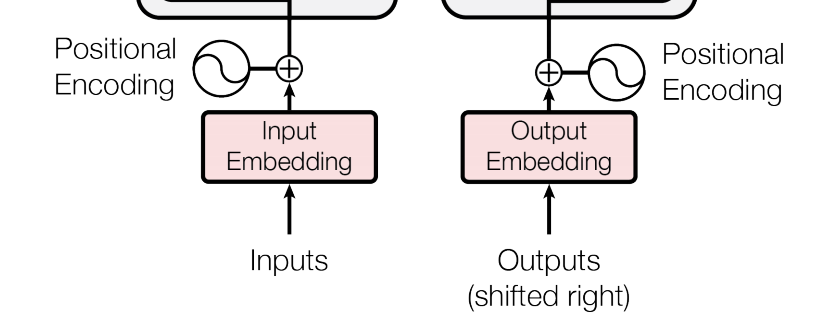
Embedding 是自然語言處理 (NLP) 常用的編碼方式,它將「單字」轉變為向量。Transformer 使用的是 512 位元的 embedding 編碼方式。
前文提到,Attention 機制忽略了輸入序列中每一個元素的位置及元素之間的距離,更容易找出序列中每一個元素的關連性,這是它的優點。然而在實際 NLP 應用中,輸入的序列往往是一個句子,而在說話中,句子內文字的順序有著相當大的語法及語義上的含義,是不能忽略的。
為了彌補 Attention 這一個缺點,Transformer 在設計時,加入了「位置編碼 (Positional Encoding)」機制,輸入序列在經過 embedding 處理後,每一個位置的輸入值,都要加上在那個位置上的位置碼,如此,便可把位置資訊加入輸入序列中。
下圖(註一)假設 embedding 的大小為 4 (實際上是 512),每一個位置編碼的大小必須和 embedding 一致,如此兩者方能相加。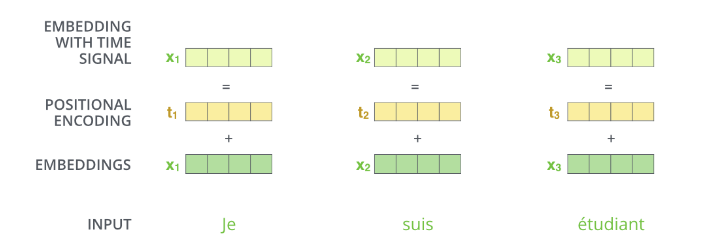
位置編碼產生的方式很多,論文作者採用的是以下的公式: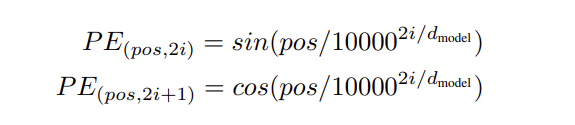
其中:
pos:即位置
2i:編碼內偶數的位元,i ∈ {0, 1, 2, 3, …}
2i + 1:編碼內奇數的位元
dmodel:模型的 embedding 大小
舉個簡單的例子,假設 embedding 大小為 4,位置 1 的位置編碼為:
bit 0 : sin ( 1 / 10000^(0)) = 0.8414
bit 1 : cos( 1 / 10000^(0)) = 0.54
bit 2 : sin ( 1 / 10000^(2/4)) = 0.01
bit 3 : cos( 1 / 10000^(2/4)) = 0.9999
位置編碼的計算相當簡單,但是這種編碼為什麼可以代表位置呢?老頭建議有興趣的 AI 人參考 Amirhossein Kazemnejad 的 Transformer Architecture: The Positional Encoding(註二)部落客發文,其中有很好的解說。
(註一:源自 Jay Alammar 的《The Illustrated Transformer》 )
(註二:Transformer Architecture: The Positional Encoding 之連結 )

