在昨天我們講完如何預估Azure使用成本後,今天我們來談談Azure的SLAs
(Service Level Agreements),當我們日後想在Azure上提供Saas服務,我們必須知道Azure
SLA的相關定義/類型/級別及複合SLA如何計算

Azure SLA為Microsoft在官方文件定義遵循全面的操作策略,標準和慣例向客戶提供
高質量的產品和服務的承諾的說明,並說明Azure產品和服務各別的SLA及Azure服務
或產品未能達到管理SLA規範的要求,將會發生什麼情況。
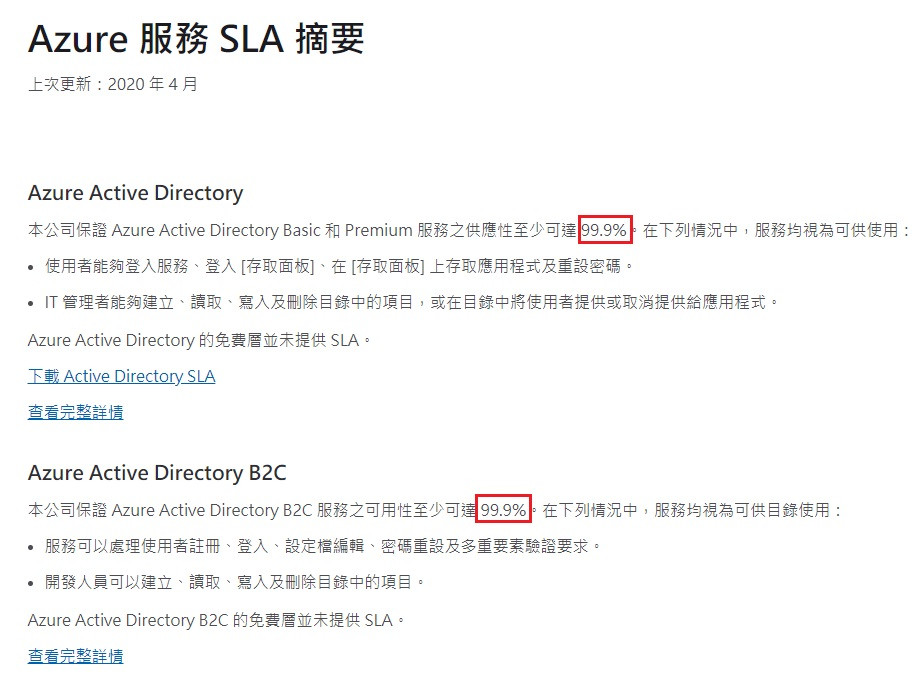
對於每個相應的Azure產品或服務,典型的SLA特定的性能目標承諾範圍從99.9%
(3個9)到99.99%(4個9)。這些目標可以應用於諸如運行時間或服務響應時間
之類的性能標準。
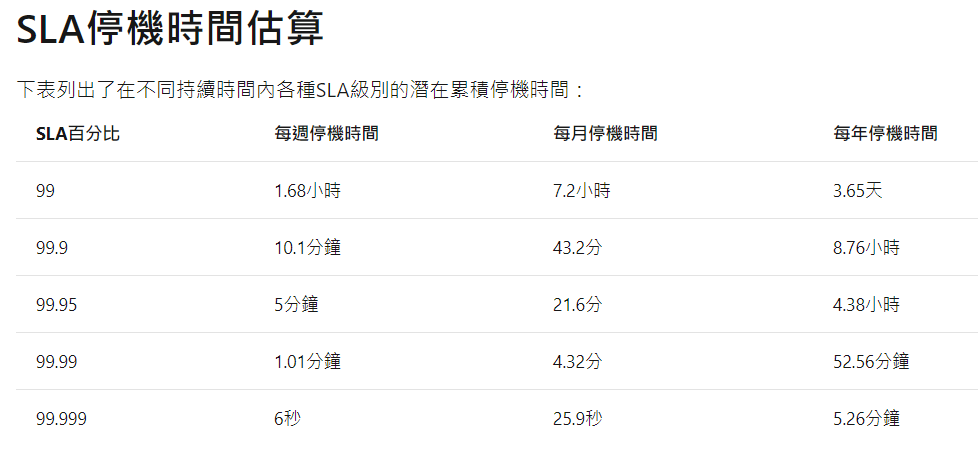
Service Credits為Microsoft如何在Azure產品或服務無法履行其管理SLA規範的
情況下做出的回應,針對服務未達到SLA標準,微軟會補償Service Credits,如下表

復合SLA為將不同服務產品之間的SLA組合在一起時,生成的SLA被稱為Composite
SLA。最終的複合SLA可以提供更高或更低的正常運行時間值,具體取決於您的應用程式
體系結構。

上面範例中如果其中一項服務失敗,則整個應用程式將失敗。通常每個服務的各個概率
值是獨立的。但是以上的應用程式的複合SLA值為相乘,這意味著組合值低於各個SLA值
出現故障的可能性更高,因為依賴多個服務的應用程式有更多潛在的故障點。
99.95 percent × 99.99 percent = approx 99.94 percent
相反,若可以通過建立獨立的備援路徑來改進複合SLA。例如,如果SQL數據庫不可用,
則可以將transactions放入Queue中,以便後續處理。
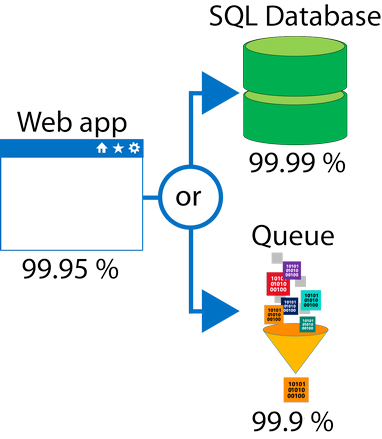
使用上圖所示的設計,即使無法連接到數據庫,該應用程序仍然可用,但是,如果SQL
數據庫和Queu同時失敗,則失敗。如果同時發生故障的預期時間百分比為
Database *OR* Queue = 1.0 − (0.0001 × 0.001) = 99.99999 percent
因此,總的複合SLA為:
Web app *AND* (Database *OR* Queue) = 99.95 percent × 99.99999
percent = ~ 99.95 percent
但是,使用這種方法需要權衡取捨,例如,應用程序邏輯更加複雜,你需要為
Queue付費,並且可能需要考慮數據一致性問題。

應用程式SLA為Azure用戶可以使用SLA評估Azure解決方案如何滿足其業務
需求以及客戶和用戶的需求。通過建立自己的SLA,可以設置性能目標以適合特定
的Azure應用程式。建立應用程序SLA時,請注意以下事項:
1.Identify workloads:工作負載是在業務邏輯和數據存儲需求方面
在邏輯上與其他任務分離的獨特功能或任務。每個工作負載對可用性,
可伸縮性,數據一致性和災難恢復都有不同的要求。為確保應用程序體系結構
滿足業務需求,請為每個工作負載定義目標SLA。除了應用程序依賴性之外,
還要考慮滿足可用性要求的成本和復雜性。
2Plan for usage patterns:使用模式在需求中也起作用。識別關鍵和
非關鍵時期的需求差異。例如,報稅申請在申請截止日期之前不會失敗。為了
確保正常運行,請在一個區域發生故障時跨多個區域計劃冗餘。相反,為了
最大程度地減少非關鍵時期的成本,您可以在單個區域中運行應用程序。
3.Establish availability metrics:平均恢復時間(MTTR)和
平均故障間隔時間(MTBF)。MTTR是故障後恢復組件所需的平均時間。
MTBF是組件可以合理預期的兩次停機之間的持續時間。使用這些措施來
確定在何處添加冗餘並確定客戶的服務水平協議(SLA)。
4.Establish recovery metrics:-恢復時間目標和恢復點目標
(RPO)。RTO是事件發生後應用程序不可用的最長時間。RPO是災難
期間可接受的最大數據丟失持續時間。要獲得這些值,請進行風險評估
,並確保了解組織中停機和數據丟失的成本和風險。
5.Implement resiliency strategie:彈性是系統從故障中恢復
並繼續運行的能力。實施彈性設計模式,例如隔離關鍵資源,使用補償性
事務以及在可能的情況下執行異步操作。
6.Build availability into design:可用性是系統正常運行和
工作的時間比例。採取步驟以確保應用程序可用性符合您的服務級別協議
。例如,避免單點故障,按服務級別目標分解工作負載,並限制大量用戶。

潛在停機時間的風險在各個SLA級別上都是累積的,這意味著複雜的解決方案
可能面臨更大的可用性挑戰。因此,高可用性對您的要求有多關鍵將決定你
如何處理應用程序SLA的複雜性和成本增加。
手把手計算複合SLA練習:
Day18教學講義:
https://docs.microsoft.com/zh-tw/learn/modules/explore-azure-service-level-agreements/

