現在該是時候來看看 Scaled Dot-Product Attention 的運作細節。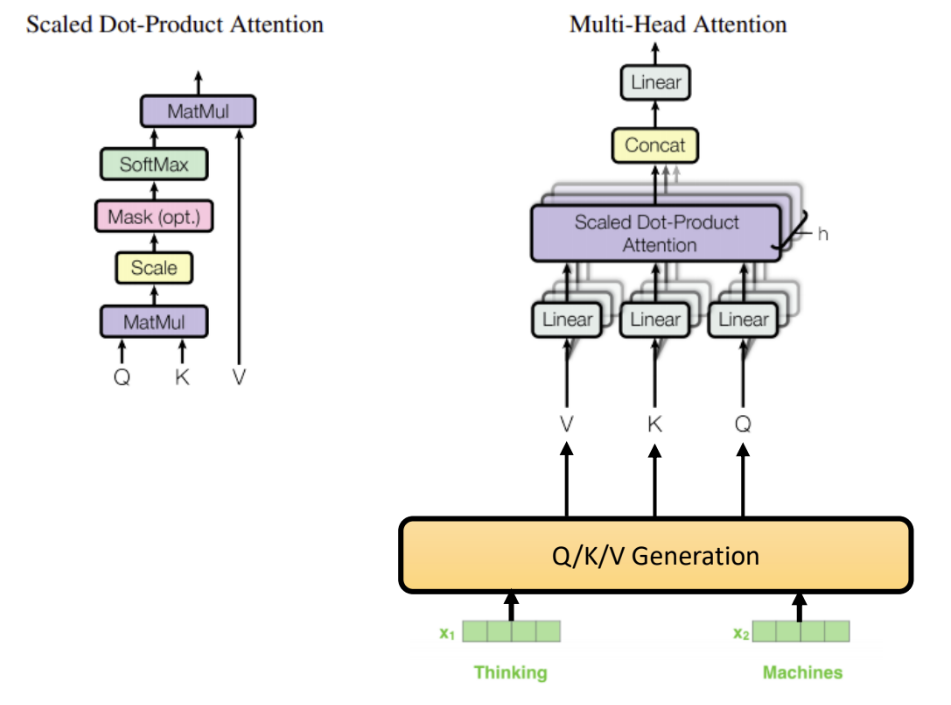
上圖的左上方即是 Scaled Dot-Product Attention 的概略流程 (要注意,在編碼階段不需要執行 Mask 操作),執行時,針對輸入序列中的每一個元素,執行以下的步驟:
第一步 (MatMul):將其 Q 和序列中所有的 K 作內積 (Dot-Product) ,得到一個內積序列 (下圖的 Score )。
第二步 (Scale):將內積序列中的每個數除以「K長度的平方根」,論文中 K 的長度為 64,所以要除以 8(下圖的 Divide by 8)。
第三步 (SoftMax):將序列做 SoftMax 運算(下圖的 SoftMax)。
第四步 (MatMul):將輸入 V 序列中的值,乘上其對應的 SoftMax 結果,得到一個 weighted V 序列(下圖的 Softmax X Value)。
第五步:將 weighted V 序列所有元素相加,得到輸出的結果(下圖的 Sum)。
下圖(註一)以圖形的方式說明以上的步驟,希望讓大家能更清楚這個流程。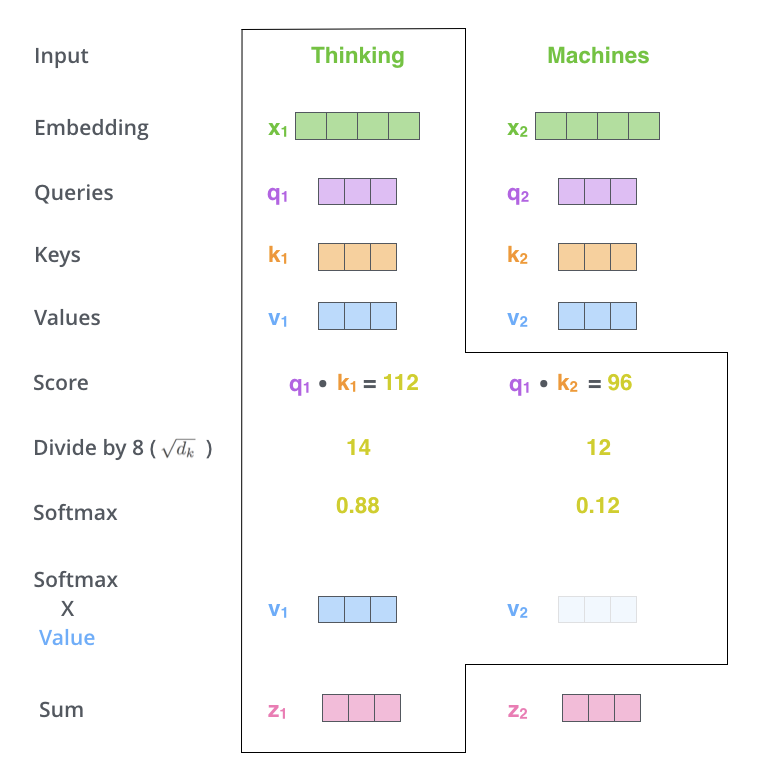
前面提過,Transformer 每一個子層皆包括了 Residual, Add & Normalization 機制,下圖(註一)將論文中的圖形與《The Illustrated Transformer》中的圖並列,讓大家更清楚的 Transformer 的設計。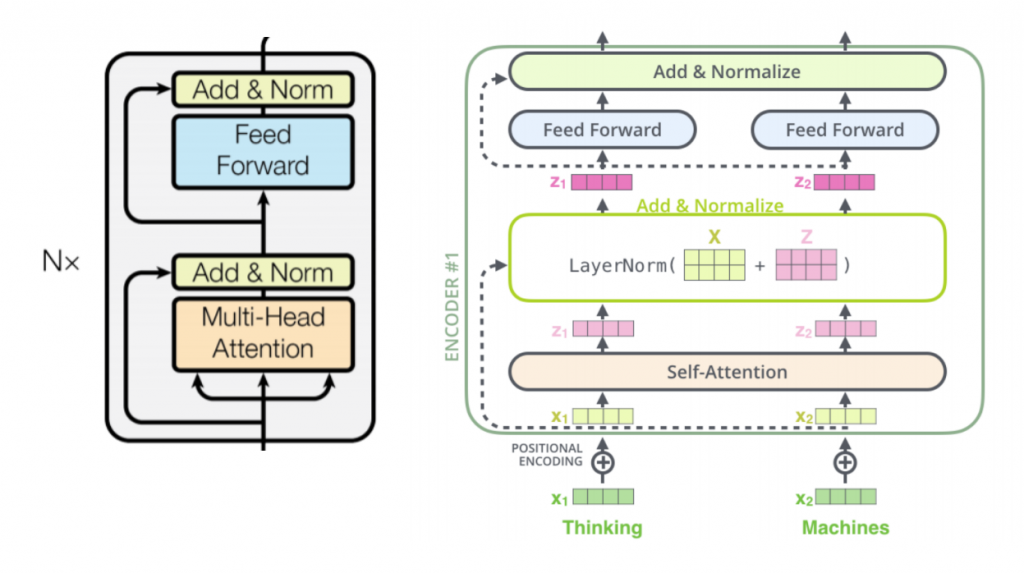
以數學公式來看,Muti-Head Attention 可表示為:
LayerNorm ( X + Z )
對 Layer Normalization 有興趣的 AI 人,可以參考(註二)之論文。
(註一:源自 Jay Alammar 的《The Illustrated Transformer》 )
(註二:Layer Normalization 論文 arXiv 號碼 1607.06450

