今天將會實作資料結構 stack , 之所以選擇 stack 是因為其製作簡單, 可以讓讀者輕鬆的理解 CAS 在其中扮演的腳色。
node: ( 協助理解下方程式碼 )
class node {
public:
node* next;
int value;
node(int value) {
this->value = value;
next = nullptr;
}
};
core code : (push node and pop node from stack)
void pushNode(int value) {
// 創建節點
node* n = new node(value);
// 把節點的下一個, 設為目前的第一個節點
n->next = head;
// 把新節點設定為第一個節點
head = n;
}
void popNode() {
start:
if (head == nullptr)
goto start; //一定要刪到, 不放棄
// 把第一個節點設定成第一個節點的下一個節點。
head = head->next;
// 注: 此處僅邏輯上刪除, 並沒有刪除其所佔用記憶體。
}
利用以上的資料結構可以發現, 在僅有一條 thread 時會順利運作, 但當有多條 thread 同時操作時會因為 race condition 出現問題。 常見問題如下 :
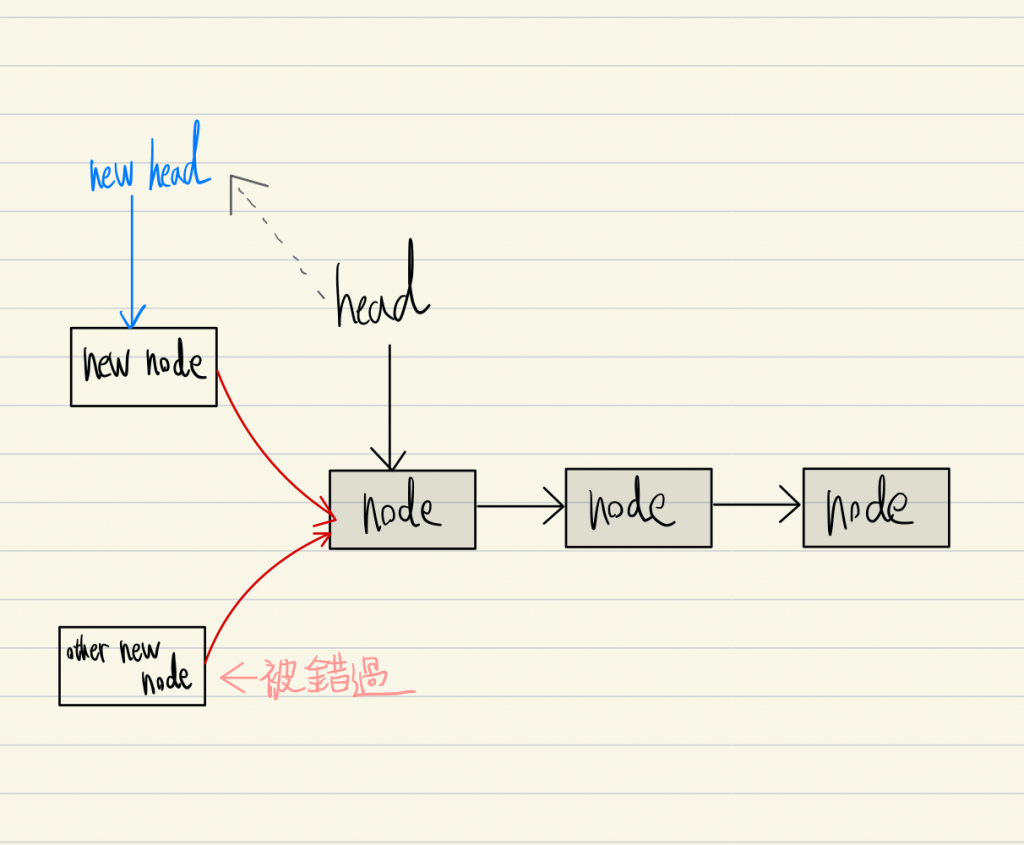
因此我們必須使用阻塞機制來確保, 在 multi-thread 操作時的正確順序。
void pushNode(int value) {
node* n = new node(value);
glock.lock(); // 加 mutex lock
n->next = head;
head = n;
glock.unlock(); // 解 mutex lock
}
void popNode() {
start:
if (head == nullptr)
goto start; //一定要刪到, 不放棄
glock.lock();
head = head->next;
glock.unlock();
}
沒什麼好說的, 直接強迫同時只會有一條 thread run 在 critical section
但會導致我昨天提到的, 阻塞式同步機制的問題 ( 響應時間也會被阻塞, 可能在例外情況 deadlock )。
利用非阻塞式同步機制實作的stack, 且具有 lock-free 的特色。
api 參考
void pushNode(int value) {
node* n = new node(value);
do {
// 設定新節點的下一個節點是目前的第一個節點
n->next = head.load();
} while (!head.compare_exchange_weak(n->next, n));
/*
* 若 head == n -> next 就令 head = n
* 若 head != n , 改令 n -> next = head 然後做下一輪, 做到一樣為止
*/
}
void popNode() {
start:
node* curHead = head.load();
do {
if (curHead == nullptr)
goto start; //一定要刪到, 不放棄
} while (!head.compare_exchange_weak(curHead, curHead->next));
// 如果我們要移除的節點, 現在還是首節點, 那就執行移除。否則重作。
}
回到這張圖的情況, 當一條 thread 在添加節點的過程中, 另一條 thread 就添加了別的節點, 要怎麼不錯過節點呢 ?
以上程式碼是怎麼做到的~~~
原來當他想要把, head 移動到 new node 時, 會檢查 head 是否還在 new node 的下一個, 如果是, 才會移動 head 指標 (而且 CAS 指令確保了檢查和移動 head 指標是不可中斷的, 所以此情況必然成立)
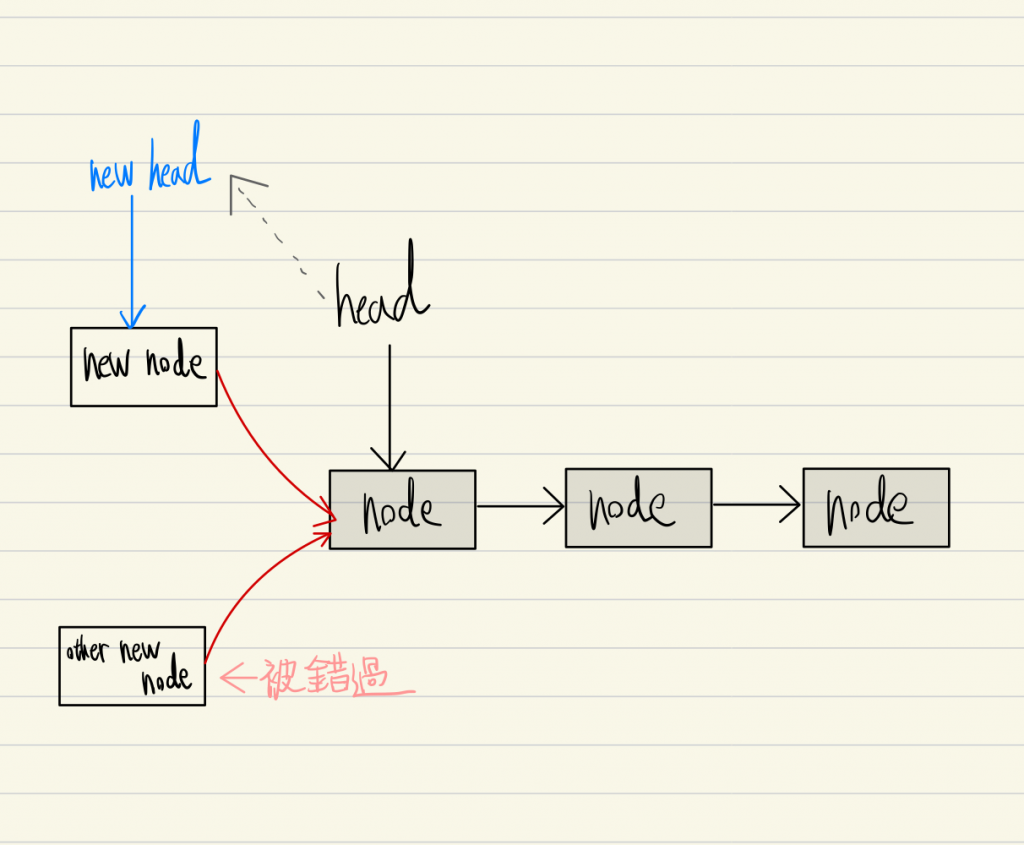
接著我們繼續看 other new node 目前已經被錯過, 要怎麼被加回 stack 中
第一張圖是檢查自己 ( other new node ) 的下一個節點是不是第一個節點 (head) , 發現不是, 所以把自己的下一個節點設為 new node (目前的第一個節點) ,這段檢查與更改的過程也是 CAS 。 之後因為更改失敗進入下一個循環。
第二張圖, other new node 檢查得知下一個節點確實是 head ( 第一個節點 ) , 所以移動 head 指標完成節點的添加。
至於另一種 race condition 比較好理解, 我就不描述了。
可以發現, 在 lock-free stack 我們必須假設到所有可能的 race condition 情況, 之後利用 CAS 設計某種機制來解決這些情況。以我個人的感覺, 在設計演算法時要把可以獨立先做的事情先完成, 最後利用 CAS 把不能接受中斷的事完成。
但事實上在這篇教學裡我並沒有列出所有 race condition 情況, 我只說了
其實 還有
甚至還有
ABA 問題這種 push 過程產生 pop pop push 等狀況。
不過因為這支範例程式的測試沒有很極端, 所以我並沒有考慮所有的 race condition , 但其確實已經解決大多數的 race condition 了, 大家可以試著畫圖模擬各種情況, 再試著用這個 CAS 演算法跑跑看能不能解決。
最後說一下, 我個人覺得像 stack 這類簡單的資料結構要 lock-free 靠自己的大腦還可以, 但更難的我建議直接去抄 paper 比較實在。
基本的 CAS lock-free 說完了, 我明天開始打算帶大家一起讀 .NET 的非同步方法 Task.WhenAll , 讓大家看看框架裡面實踐非同步方法的作法。


 iThome鐵人賽
iThome鐵人賽