接續上一篇關於專案參加角色與pipeline的介紹,這一篇繼續談論每一區塊需要的服務以及如何依照使用情境的順序將各服務串接。
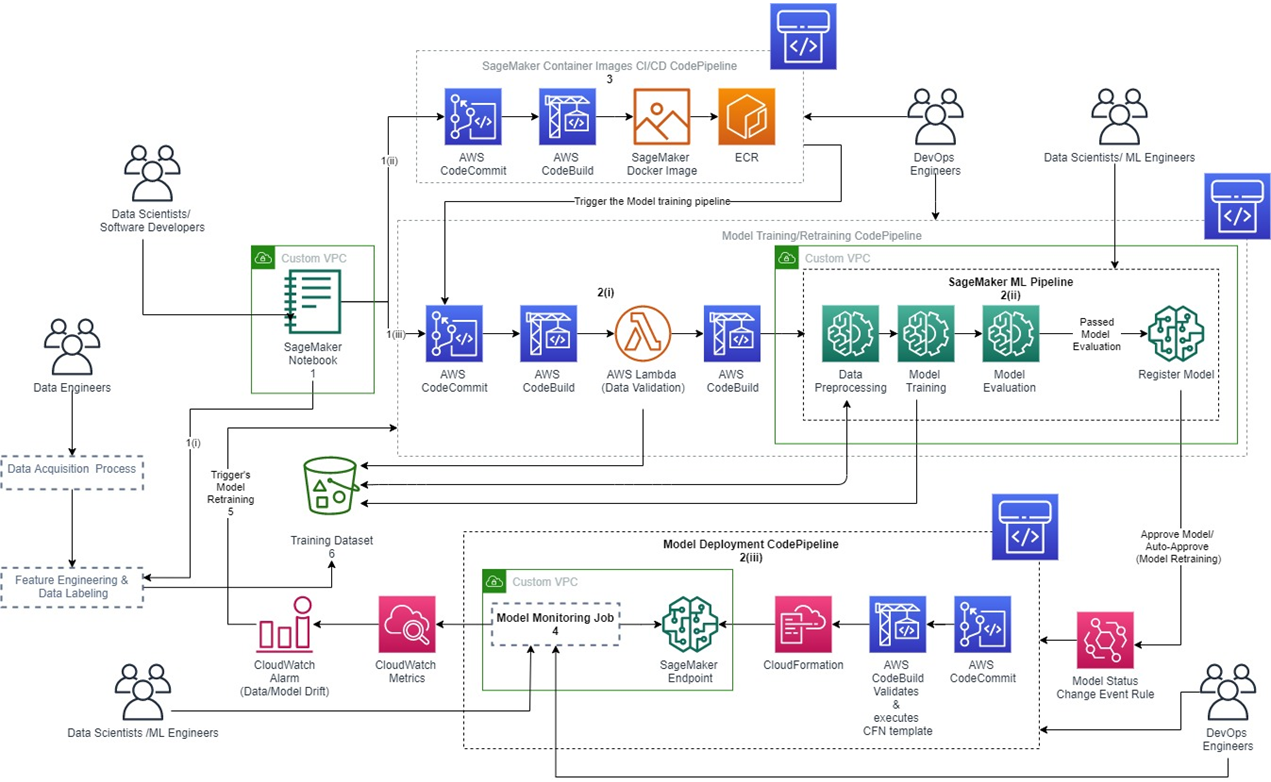
*圖片來源:使用 MLOps 在 AWS 上馴服機器學習:參考架構
在架構圖當中,除了pipeline之外,也可以看到幾個不同顏色的方格,代表不同性質的AWS服務,舉例來說:
(1)綠色的方塊,與資料儲存、模型開發相關,相關的服務有SageMaker、S3。其中Amazon SageMaker屬於專門為 ML 所搭建的服務,其包含一系列廣泛的功能,協助資料科學家和開發人員快速準備、建置、培訓和部署高品質的機器學習 (ML) 模型。而Amazon S3則是Amazon Simple Storage Service的縮寫,用來做物件儲存服務,可放置不同類型的物件,並能夠在上面做備份、還原、版本控制等等。
(2)藍色的區塊則是屬於基礎架構的服務,架設CI/CD pipeline,相關的服務有CodeCommit跟CodeBuild。其中AWS CodeCommit,屬於私有託管的Git儲存服務,用於存儲、跟踪和版本更改 ML 代碼的版本控制系統,與其他AWS服務的高整合,而有更快速的開發週期。AWS CodeBuild可以用來建立持續整合與部屬的服務,管理、發佈到多個不同的開發環境。
(3)橘色的ECR跟SageMaker Docker image則是用來讓你能夠使用預設image,然後可以根據建置好的image推送到ECR。Amazon ECR是Amazon Elastic Container Registry的縮寫,為大家所開發的Docker image提供託管服務,能夠在上面存放、管理、共享及部署容器映像(docker image)。
(4)粉紅色的方塊,與系統監測、通知有關,也有部署架構的配置,相關的服務有CloudWatch、CloudFormation。Amazon CloudWatch是AWS上面集結所有服務的日誌的地方,可以透過cloudwatch觀測系統現況、透過日誌、指標和事件的形式來收集監控和運作資料。AWS CloudFormation,透過將服務的部屬配置放在同一個檔案,讓開發人員輕鬆建立相關 AWS 和第三方資源服務集合集合,達成基礎設施即代碼 (IaC, infrastructure as code)的服務。將專案所需的資源可以透過程式碼配置以及版本控制。
在知道每一個pipeline、每一個架構圖中的服務與功用之後,如果不想選擇全託管的服務,也可以自行抽換成其他提供類似功能第三方服務,或者自行架設該服務做取代。
透過security group和自定義VPC設定來確保網路使用的安全性。並將ML專案的服務發佈到私有網路內,並透過部署模板來發佈所需資源。將 Amazon SageMaker 的專案發佈在AWS Service Catalog中。
從系統維護面來說,不管是ML服務或是軟體服務,儘可能的讓這些服務容器化。這樣在AWS、其他公有雲、私有雲或本機的環境,只要是容器可以運作的環境,都可以輕易地重新實現服務。
透過Amazon SageMaker Model Monitor進行模型監控,可以觀察數據漂移、模型漂移、模型預測的偏差和特徵屬性的漂移這幾個指標。
透過容器化以及模型監控,可以協助ML系統完成更高程度的自動化。
在這個專案當中有使用到的ML服務只有提到Amazon SageMaker,不過在所有的AWS AI服務當中,還可以細分為三個不同的層級:
AI 服務:相較於後面兩者,使用AI服務的門檻相對低,如果有符合的情境以及適合的資料,便可以使用預先訓練好的模型。在AI服務由幾個不同的服務所構成,開發者能夠透過 API 呼叫將 ML 功能快速新增到當前的專案當中。舉例像是提供電腦視覺服務的Amazon Rekognition和文字分析服務的Amazon Comprehend。
ML 服務: AWS 提供託管服務和資源(例如Amazon SageMaker),資料科學家可以透過此服務進行各種ML工作的開發,例如標記資料集、構建、訓練、部署和管理訓練好的 ML 模型等等。也可透過ML 服務優化資料科學家的工作體驗,可以專注在使用情境跟交付價值上。
ML 框架和基礎設施:也有開發者使用TensorFlow、PyTorch 和 Apache MXNet 等開源框架在開發模型,這些團隊則屬於第三類型。可以使用深度學習容器(DLC)來構建、訓練和部署 ML 模型。
一個專案的ML服務可以從這三者選其一,也可以依照情境,組合所需要的服務和基礎架設。
對於模型上線之後,什麼時候要再訓練,這邊提供三個方式:
透過上一篇與這一篇的分析,相信大家對於案例的學習有更深一步的學習。接下來也會帶大家看其他的案例參考。

