在經歷了幾篇的MLOps基礎概念之後,想在後面的文章帶大家看看幾個案例。透過案例來學習,會對專案在技術上的架構全貌更清楚。今天選的案例是這篇:Taming Machine Learning on AWS with MLOps: A Reference Architecture,文章內容談論如何在AWS上透過SageMaker跟CodePipeline駕馭MLOps。包含專案的技術跟商業目標以及透過架構來示範有哪些主要服務,可以怎麼串接這些服務。
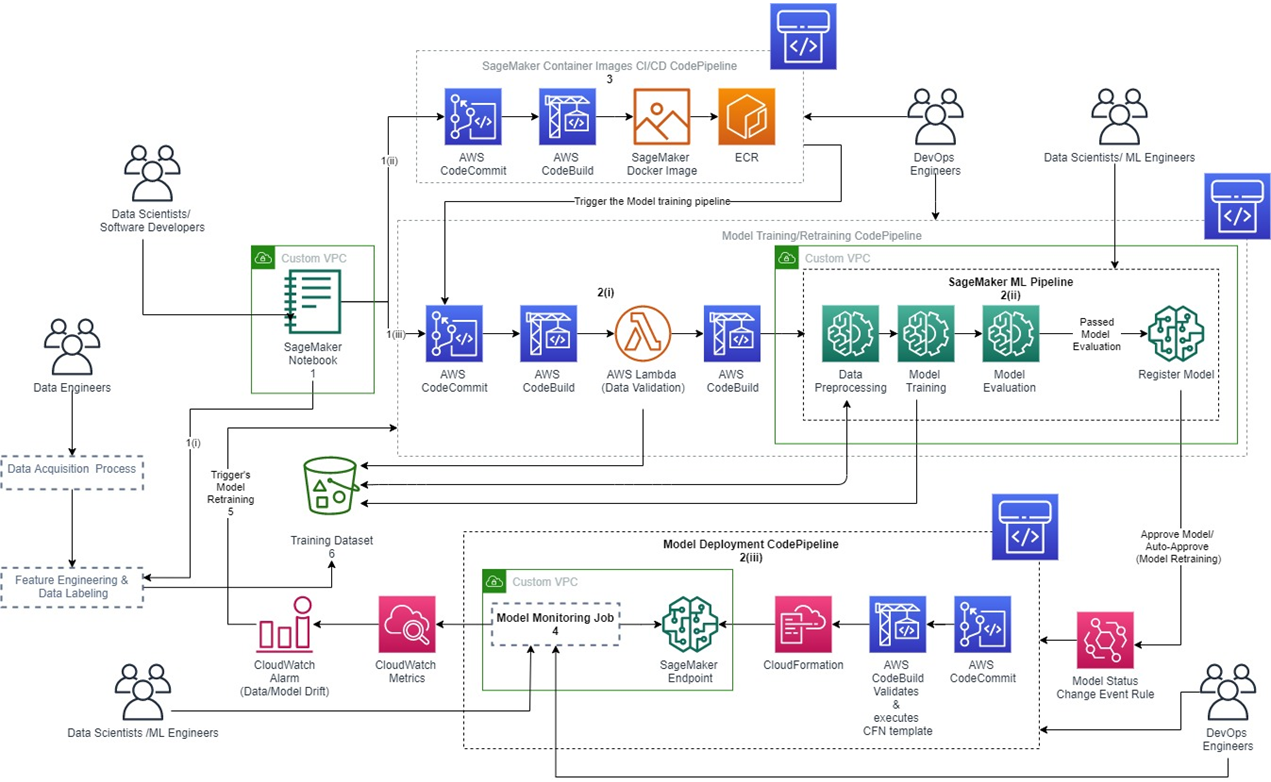
如果單從架構圖來看,可能會遇到的問題像是:不知道可以從哪裡開始看、什麼樣的架構是好的或不好的架構、以及還有沒有哪些沒有寫在架構圖上的東西。在看案例的時候,我會拆分幾個面向:(1)專案是否具有產業特殊性(2)會需要哪些人一起完成(3)有哪些Pipeline(4)每一區塊需要的服務(5)如何依照使用情境的順序將各服務串接(6)各方面的可擴張性。本文章會談論到的,主要包含(2)、(3),下一篇則包含(4)、(5)。
簡單提一下這些不同角色的名稱和他們在專案裡面做的事情。這個案例是屬於各個產業都通用的,所以就沒有領域專家在其中。
(1)資料工程師(data engineer):公司裡面協助資料科學家、商業分析師取得、清理專案的資料的角色,也會依照資料讀取方的需求,協助整理資料的特徵,以便於更快速地進行到建模或者建立報表的階段。
(2)資料科學家(data scientist):每個公司對於資料科學家的職務範圍都不大相同,有時候包含很廣的職務範圍,從拿資料、整理資料、訓練模型等等都有。在這一個案例當中,我們簡單的把職務內容縮減為:訓練模型、在乎模型準度的角色。
(3)ML工程師(ml engineers):與資料科學家有蠻大部分的重疊,將其定義為:訓練模型、在乎模型準度的角色。
(4)軟體工程師(software developers):在這邊的角色是協助資料科學家能夠更友善的與pipeline以及docker互動。這個工作內容有時候也是讓DevOps同事協助了。因此在ML專案中,大部分並不會特定再去雇用一個軟體工程師。
(5)DevOps工程師(devops engineers):負責照顧專案從建置到部署的生產管線建置。
機器學習的專案,主要分為,收集資料、資料處理、建立模型、模型註冊、模型部署。收到使用者回饋之後,再回到資料處理、建立模型的循環,產生新的版本的模型服務。從架構圖來看,主要會看到三個Pipeline。
(1)Model training/retraining Pipeline:包含驗證資料、資料前處理、訓練以及驗證模型。若通過驗證則進行到註冊模型的步驟。透過這個pipeline可以記錄:數據的來源、訓練資料集的位置以及實驗中產生的數據以及模型輸出。
(2)Model deployment Pipeline:模型的部署包含了如果得到發佈模型的授權,就部署到服務端點(endpoint)上,以及模型監測。
(3)SageMaker Container Image CI/CD build Pipeline:這個Pipeline屬於比較進階的情境,資料科學家們需具備把自己的訓練程式碼包成在容器環境內可以執行的能力。由於SageMaker提供建立好的Docker Image讓資料科學家可以客製化使用其各項功能,所以才會有這個Pipeline。方便提升實驗的重現性。如果不是使用SageMaker的開發者,也依舊可以維護自己使用的平台、框架支援的docker環境,在不同平台上面重現實驗。
除了這三個pipeline之外,還有一些執行細節,像是:
(a)模型註冊:用於版本控制,紀錄訓練結果的模型註冊。(b)資料集版本控制:使用Amazon S3 的版本控制實現的資料集版本控制。(c)流程追蹤:ML 工作流程步驟使用Amazon SageMaker Lineage Tracking實現的可審計性、可見性和再現性。(d)角色管理:使用AWS Identity and Access Management (IAM) ,實施角色授權,確保只有經過授權才能訪問。
明天繼續針對每一區塊需要的服務和如何依照使用情境的順序將各服務串接的部分介紹。

