前3篇回顧
awk - 簡介 Linux 製表好工具
awk-2 Regex搭配淺談
awk-3 運算符與函數
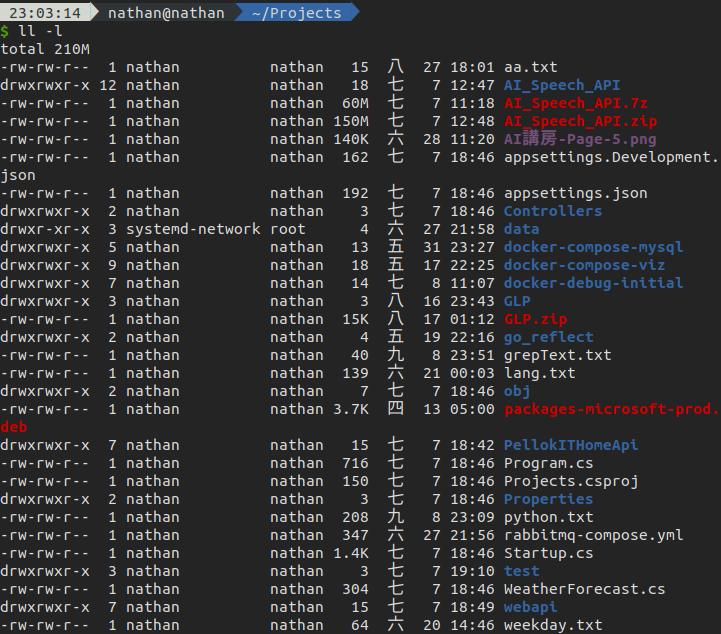
ls -l看到當前目錄下所有檔案跟大小, 檔案大小在第5個欄位# BEGIN區塊宣告size變數
# COMMAND區括做累加
# END區塊做輸出
ls -l | awk 'BEGIN{size=0}{size+=$5} END{print "size:" size}'
> size:219312120
# 計算成MB
ls -l | awk 'BEGIN{size=0}{size+=$5} END{print "size:" size/1024/1024 "M"}'
> size:209.152M
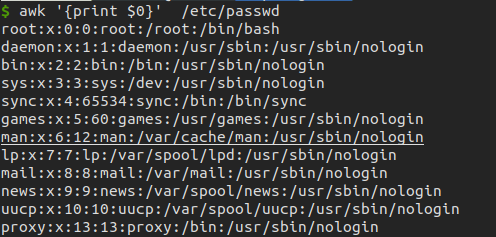
# for in loop
awk -F ':' 'BEGIN{count=0}{if ($3 > 100) name[count++]=$1} END{for (idx in name) print idx, name[idx] }' /etc/passwd
> 3 messagebus
> 10 usbmux
> 27 systemd-coredump
> 8 tcpdump
> 6 tss
# for condition loop
awk -F ':' 'BEGIN{count=0}{if ($3 > 100) name[count++]=$1} END{for (idx=0; idx<count;idx++) print idx, name[idx] }' /etc/passwd
> 0 nobody
> 1 systemd-resolve
> 2 systemd-timesync
> 3 messagebus
> 4 syslog

[ ]也有個空格, 所以其實在$6netstat -anp | awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (idx in sum) print idx, sum[idx]}'
> LISTEN 12
> CONNECTED 1121
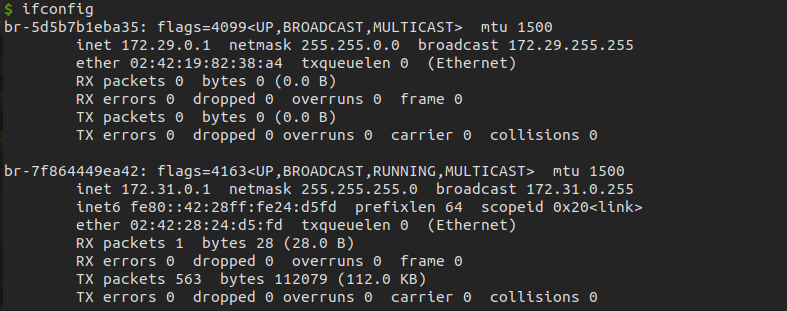
ifconfig | awk '{print $2}' | grep -Eo "([0-9]{1,3}[\.]){3}[0-9]{1,3}"
> 172.29.0.1
> 172.31.0.1
> 127.0.0.1
會發現這裡有127.0.0.1, 但這ip, 每台電腦必有, 沒參考價值, 因此找個方法忽略它
把```lo```開頭的行給忽略就好
```RS```是awk的內建變數, 用來指定行的分隔符號, 預設是```\n```換行符號, 遇到\n為一行
這裡把RS設置為空字串, 表示要遇到一行空字串才做換行輸出; 可以看上圖, 2個網卡中間會個空行
這樣子就能把多行資料, 一直當成同一行讀取, 直到RS指定的行分隔符號
ifconfig | awk 'BEGIN{RS=""}!/lo/{print $6}' | grep -Eo "([0-9]{1,3}[\.]){3}[0-9]{1,3}"
> 172.29.0.1
> 172.31.0.1
# 準備假資料
cat > bb.txt <<EOF
heredoc> UID=1
heredoc> UID=2
heredoc> UID=4
heredoc> UID=3
heredoc> UID=2
heredoc> UID=3
heredoc> EOF
awk -F "=" '!arr[$2]++ {print}' bb.txt
> UID=1
> UID=2
> UID=4
> UID=3
awk是個簡單的動態程式語言, 可以處理複雜的文字處理,
若只是查找其實前篇的grep足以, 但awk能把資料做轉換然後輸出.
但awk執行效率不是很好,
所以還是比較多人選擇用Python、Perl進行大型文件的處理.
但若是內容沒幾MB, awk就是把精緻的小刀, 很方便使用, 其他語言要寫好幾行, awk可能只需要一行.
提供一篇文章, 快速地把awk給說明演示一次
Awk in 20 Minutes

