
在程式裡第二個常出現的就是字串處理啦
| 連接運算子 | 說明 | 用法 |
|---|---|---|
. |
連接 | x . y |
.= |
連接並賦值 | x .= y |
在 PHP 中字串是用 . 連接,如果用 + 會變成數字相加
echo 3 . "2.5", "\n"; // 32.5
echo 3 + "2.5", "\n"; // 5.5
| 比較運算子 | 說明 | 用法 |
|---|---|---|
== |
相等(值) | x == y |
!= |
不相等(值) | x != y |
=== |
相等(型別 and 值) | x === y |
!== |
不相等(型別 or 值) | x !== y |
< |
小於 | x < y |
> |
大於 | x > y |
>= |
大於 or 等於 | x >= y |
<= |
小於 or 等於 | x <= y |
<> |
大於 or 小於 | x <> y |
<=> |
小於返回 -1, 等於返回 0, 大於返回 1 | x <=> y |
除了檢查字串相等,其他的雖然也不會出錯,但應該很少會用到
大於小於會從第一個字開始往後比較
var_dump("a" == "b"); // bool(false)
var_dump("a" != "b"); // bool(true)
var_dump("a" === "b"); // bool(false)
var_dump("a" !== "b"); // bool(true)
var_dump("ac" < "b"); // bool(true)
var_dump("a" > "b"); // bool(false)
var_dump("a" >= "a"); // bool(true)
var_dump("a" <= "b"); // bool(true)
var_dump("a" <=> "b"); // int(-1)
單引號字串不處理「跳脫字元」與「變數解析」,只有兩種情況反斜線 \ 有作用,分別是 \' 和 \\
echo '\'', "\n"; // '
echo '\\', "\n"; // \
echo '\n', "\n"; // \n
echo '$value', "\n"; // $value
| 序列 | 說明 |
|---|---|
\n |
Enter (LF) |
\r |
Return (CR) |
\t |
TAB |
\\ |
\ |
\$ |
$ |
\" |
" |
跳脫字元最常用的就是換行 \n 了吧,另外在雙引號字串中要打 " 也會用到
echo "\"\n\$";
// "
// $
全部跳脫字元:https://www.php.net/manual/en/language.types.string.php#language.types.string.syntax.double
變數解析是一個很方便的功能,用字串連接的話,要打一堆 " 和 . 實在很麻煩
$age = 16;
echo "My age is " . $age . ".";
echo "My age is ${age}.";
| 函式 | 說明 | 用法 |
|---|---|---|
echo |
輸出 | echo $a, $b, ... |
trim() |
清除頭尾字元 | trim($str, $a = "\t\n\r\0\x0B") |
strlen() |
長度 | strlen($str) |
strrev() |
反轉 | strrev($str) |
str_replace() |
取代 | str_replace($a, $b, $str) |
str_split() |
等分 | str_split($str, $len = 1) |
explode() |
分割 | explode($a, $str, $limit) |
implode() |
合併成字串 | implode($a, $array) |
strstr() |
以字串位置分割 | strstr($str, $a) |
substr() |
以位置與長度裁切 | substr($str, $start, $len) |
strpos() |
查找字串首次出現位置 | strpos($str, $a) |
mb_strpos() |
查找字串首次出現位置(UTF-8) | mb_strpos($str, $a) |
stripos() |
查找字串首次出現位置(不區分大小寫) | stripos($str, $a) |
mb_stripos() |
查找字串首次出現位置(不區分大小寫)(UTF-8) | mb_stripos($str, $a) |
strrpos() |
查找字串最後出現位置 | strrpos($str, $a) |
mb_strrpos() |
查找字串最後出現位置(UTF-8) | mb_strrpos($str, $a) |
strripos() |
查找字串最後出現位置(不區分大小寫) | strripos($str, $a) |
mb_strripos() |
查找字串最後出現位置(不區分大小寫)(UTF-8) | mb_strripos($str, $a) |
PHP 最為人詬病的地方就是一大堆差不多的函式,其實有很大一部分是有規則的
mb_ UTF-8 模式(需啟用 mbstring)i 不區分大小寫r 從尾巴開始找所有字串函式:
最常見的函式應該就這兩個吧:
還有這個好用的網站:
最後是符號的說明:
| 表示式 | 說明 |
|---|---|
\ |
避開特殊符號 |
\n |
Enter |
\r |
Return |
\t |
TAB |
\s |
空白 [\f\n\r\t\v ] |
\S |
非空白 [^\f\n\r\t\v ] |
\d |
數字 [0-9] |
\D |
非數字 [^0-9] |
\w |
數字、字母或底線 [0-9A-Za-z_] |
\W |
非數字、字母和底線 [^0-9A-Za-z_] |
. |
除了換行以外的任意字元 [^\r\n] |
[m-n] |
m ~ n 其中一個 |
[^m-n] |
不能是 m ~ n 其中一個 |
[xyz] |
x 或 y 或 z |
[^xyz] |
非(x 和 y 和 z) |
^ |
字串開頭 |
$ |
字串結尾 |
* |
0 次或很多次 |
+ |
1 次或很多次 |
? |
0 次或 1 次 |
{n} |
n 次 |
{n,} |
n 次到無限次 |
{n,m} |
n ~ m 次 |
| `(X | Y)` |
| `(?:X | Y)` |
| `(?>X | Y)` |
(?<=Y)X |
X 前面必須是 Y |
(?<!Y)X |
X 前面不行是 Y |
X(?=Y) |
X 後面必須是 Y |
X(?!Y) |
X 後面不行是 Y |
(?F)X |
X 以修飾符 F 方式匹配 |
(?F:X)Y |
X 以修飾符 F 方式匹配,Y 則否 |
| 修飾符 | 說明 |
|---|---|
i |
不區分大小寫 |
m |
^ 和 $ 匹配行首和行尾 |
s |
. 匹配所有字元,包含 \r \n |
U |
非貪婪模式(盡可能少匹配) |
u |
匹配 UTF-8 字元 |
所有修飾符:https://www.php.net/manual/en/reference.pcre.pattern.modifiers.php
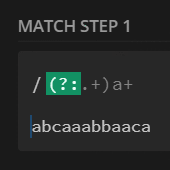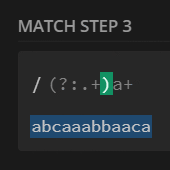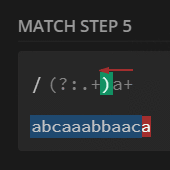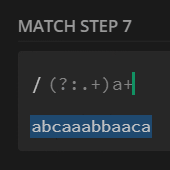
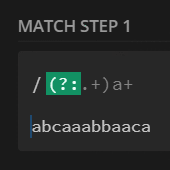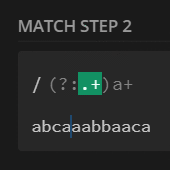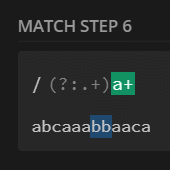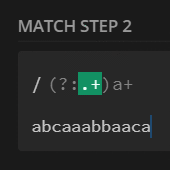
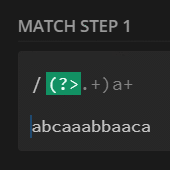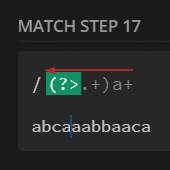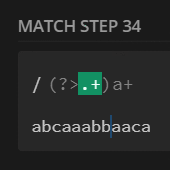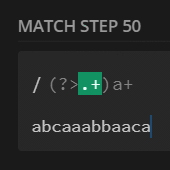
$str = 'abcaaabbacaa';
preg_match_all('/(?:.+)a+/', $str, $m);
print_r($m[0]);
// [0] => abcaaabbacaa
preg_match_all('/(?:.+)a+/U', $str, $m);
print_r($m[0]);
// [0] => abca
// [1] => aa
// [2] => bba
// [3] => ca
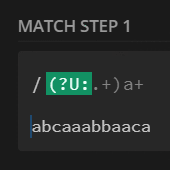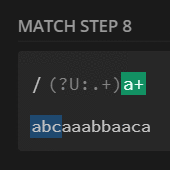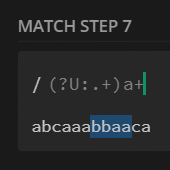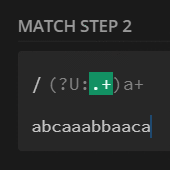
preg_match_all('/(?U:.+)a+/', $str, $m);
print_r($m[0]);
// [0] => abcaaa
// [1] => bba
// [2] => caa
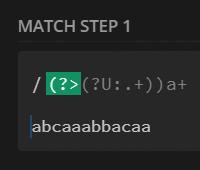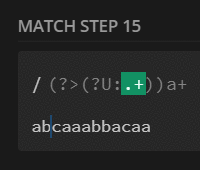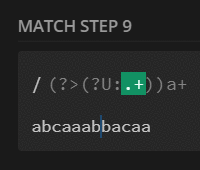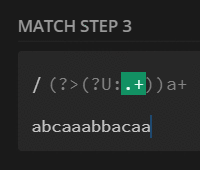
preg_match_all('/(?>(?U:.+))a+/', $str, $m);
print_r($m[0]);
// [0] => caaa
// [1] => ba
// [2] => caa
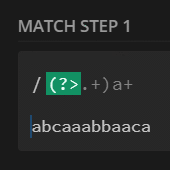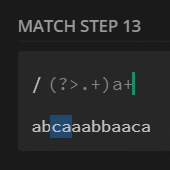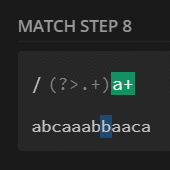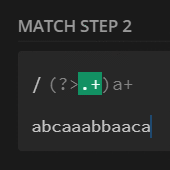
preg_match_all('/(?>.+)a+/', $str, $m);
print_r($m[0]);
// no match
preg_match_all('/(?>.+)a+/U', $str, $m);
print_r($m[0]);
// [0] => ca
// [1] => aa
// [2] => ba
// [3] => ca
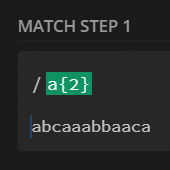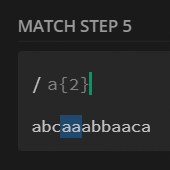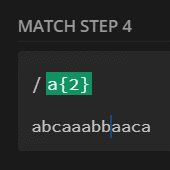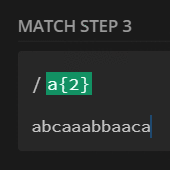
preg_match_all('/a{2}/', $str, $m);
print_r($m[0]);
// [0] => aa
// [1] => aa
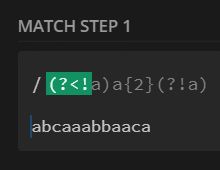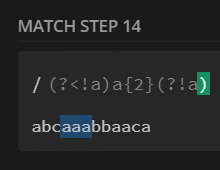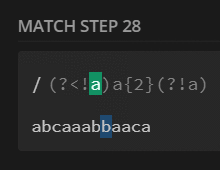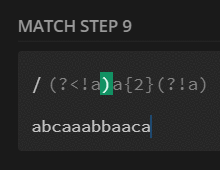
preg_match_all('/(?<!a)a{2}(?!a)/', $str, $m);
print_r($m[0]);
// [0] => aa
 |
 |
|---|---|
/(?:.+)a+/ |
/(?:.+)a+/U |
 |
 |
/(?U:.+)a+/ |
/(?>(?U:.+))a+/ |
 |
 |
/(?>.+)a+/ |
/(?>.+)a+/U |
 |
 |
/a{2}/ |
/(?<!a)a{2}(?!a)/ |
