接著昨天的資料處理繼續說明,今天來看看類別資料轉換、資料降維、資料切割、交叉驗證以及不不均衡的對應方法。
OS:資料預處理真的很重要啊啊!!
由於機器學習無法了解每個類別所代表的意思,必須將輸入的資料轉換成為數值,因此我們必須將類別變數轉換成數值。常用的有 LabelEncoder 和 OneHotEncoder。

將類別資料轉換成數值順序,將該欄類別映射到整數,不會新增欄位。像是衣服的size有分,假設某一份資料有 S、M、L、XL,依照 LabelEncoder 可以分成 0、1、2、3。而此時衣服大小有程度上的差異時,就會比較適合使用 LabelEncoder,讓機器學習該欄位(因子)的大小關係。
from sklearn.preprocessing import LabelEncoder
# LabelEncoder
labelencoder = LabelEncoder()
train['Sex'] = labelencoder.fit_transform(train['Sex'])
train.head()

或是 pandas
train['Sex'].astype('category').cat.codes
然而,將類別轉換成數值形式會有大小之分。如果該欄位沒有程度上的差異(例如性別),可能就比較不適合 LabelEncoder,會改用 OneHotEncoder。
OneHotEncoder (更常聽到 One-Hot Encoding(獨熱編碼)),描述將一個欄位有 N 種狀態,改為 N 種欄位。需要注意的是,如果該欄位的 N 過大,往往會造成維度災難(一下子會變超多欄位要預測),這時候可以再搭配降維(PCA)的操作,讓資料維度進行縮減避免特徵空間過於龐大。因此要是 OneHotEncoder 的類別數目不太多,可以建議優先考慮之。
然而,有些演算法不需要,像是 tree based (像是 Random Forest 等等) 類型的演算法,不太需要使用 One-Hot Encoding,使用它會增加樹的深度。
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder()
onehot = onehotencoder.fit_transform(train[['Sex']]).toarray()
pd.DataFrame(onehot)

或是 pandas
data_dum = pd.get_dummies(train['Sex'])
pd.DataFrame(data_dum)
比較偷懶的方式,對每個欄位使用 LabelEncoder。做機器學習做初步的嘗試時,可以不進行任何資料特徵處理丟到機器學習,先得到第一次(或數次)的模型評估評估成效當作基準(baseline),有了 baseline 就可以超過它為目標,做其他不同嘗試。(一個先找到低標的概念,之後94超越它)
# 用迴圈的方式來做更快
for _ , col in enumerate(train.columns.tolist()):
if train[col].dtype == 'object':
train[col] = train[col].astype('category').cat.codes
通常降維我們會採用 「主成分分析」(Principal Component Analysis, PCA),是一種特徵擷取(Feature Extraction)的方法。該方法希望將高維度的資料減少,但又不會影響資料原本的特性。其用意就是將複雜的問題簡單化,萃取資料的精華再給機器學習演算法。
n_components 可選擇降到多少維度
from sklearn.decomposition import PCA
X = train.drop(['Survived'], axis=1)
X = PCA(n_components=2).fit_transform(X)
拿到資料的時候,我們應該會有 training data ,testing data 不一定會有(因為有可能是未來的資料)。而在進行監督式的機器學習,我們通常會將 training data 進行資料切割,為了讓模型在學模仿未來的環境。讓模型去學習訓練集的資料,讓模型去對驗證集的答案,藉此讓我們了解在沒看過的資料下的表現。
通常拿到一包資料可以分類 trainin data 和 testing data (testing data 不會當作訓練資料)

from sklearn.model_selection import train_test_split
X = train.drop(['Survived'], axis=1)
# 看是否需要降維
# X = PCA(n_components=2).fit_transform(X)
y = train.Survived
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
這裡提醒一下,testing data 是測試集,是不可以拿去進行資料切割(如果你拿了,那演算法會看到答案等於作弊XD)。X_train, y_train 這邊是指訓練集;X_test, y_test 則是驗證集
在資料進行預測之前,通常會將資料分割。但是我們很可能會遇到極端的狀況是,我們剛好切出來的驗證集資料跟訓練集很有相關,為了避免這種狀況發生,我們可以進行交叉驗證。所謂的交叉驗證是將訓練資料進行多次不同的切割,輪流當驗證集,最後計算的時候取平均,比較能了解資料在不同情況下的成效。

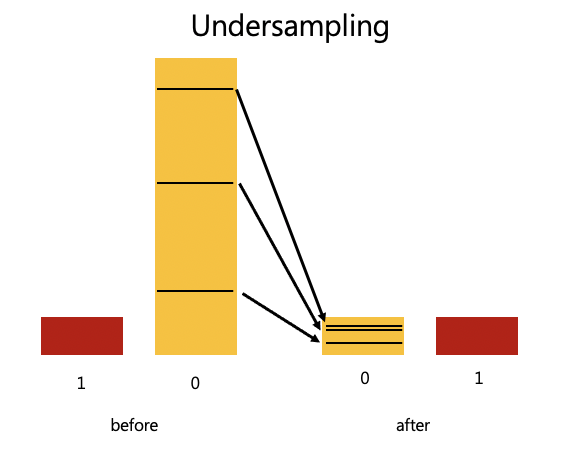
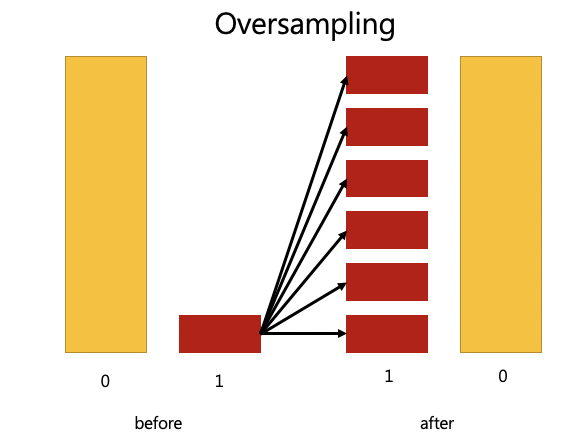
在現實生活中,往往可能會遇到資料極度不均衡的現象
通常我們想要預測的 y 都非常稀少(跟日本的製作壓縮機一樣),因此機器學習可能都會猜 0 ,導致模型正確率超高啊
但卻一點用都沒有的模型(我們就是要知道違約的那個人是誰啊,結果你都猜都交易正常)
在資料探索的時候,如果我們發現資料有這種現象的話,我們不能只用 準確率當作唯一標準,可以拿上一節說的 F1 score
但還有呢? 可以讓機器學得更好嗎?當然有!
面對不均衡資料,我們也有解決之道,可以用 Resampiing,讓多的變少,少的變多
over-sampling: 讓 1 的資料倍增
under-sampling: 讓 0 的資料縮小