今天要介紹一下工作上有使用的到的另一項工具 - Cube.js。
Cube.js 是一個開源的API工具,主要是在做將資料分析後轉換成圖表。
官網的介紹如下:
Cube.js 旨在與無服務器數據倉庫和查詢引擎(如 Google BigQuery 和 AWS Athena)配合使用。多階段查詢方法使其適合處理數万億個數據點。大多數現代 RDBMS 也可以與 Cube.js 一起使用,並且可以進一步調整性能。
使用 Cube.js,您可以在數據之上創建語義 API 層,管理訪問控制、緩存和聚合數據。由於 Cube.js 與可視化無關,您可以使用任何前端庫來構建您自己的自定義 UI。
下表顯示舊有的的資料分析與Cube.js差異,Cube.js 支援無伺服器資料倉庫和大多數現代關係型資料庫管理系統 (RDBMS)。
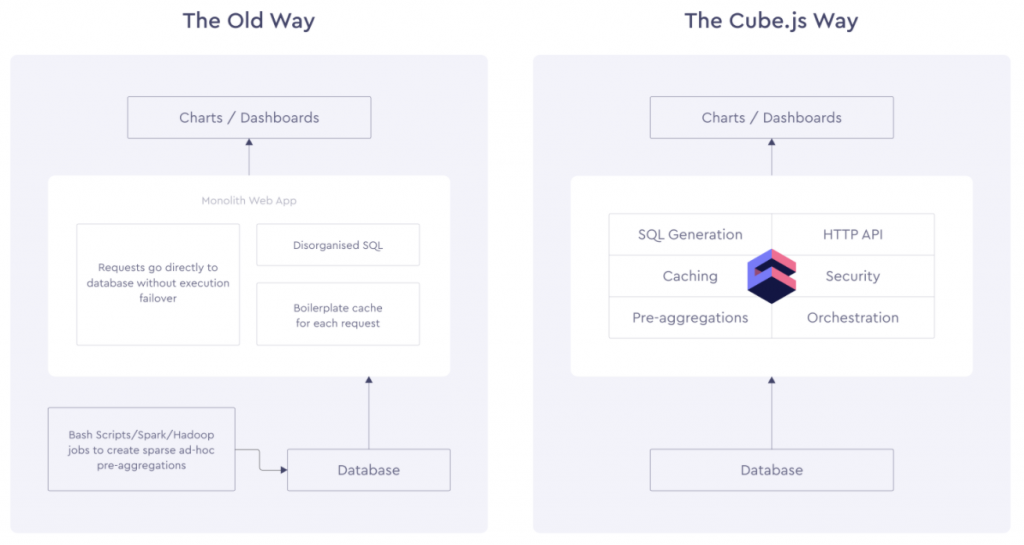
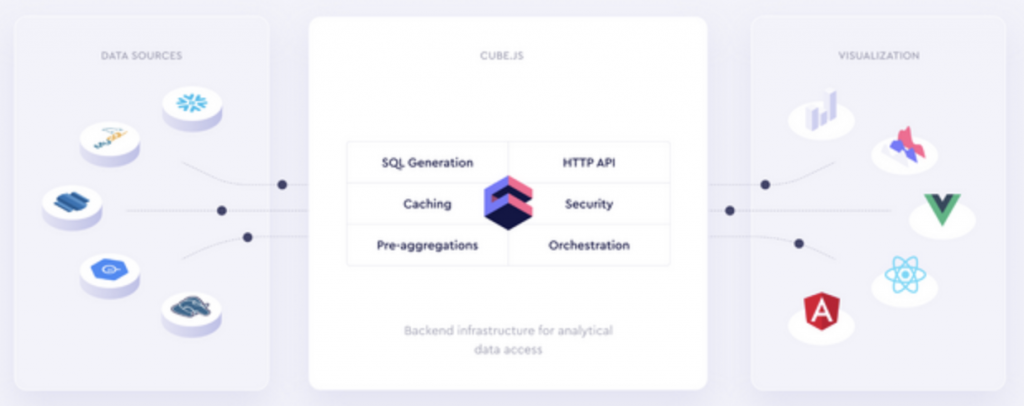
至於為什麼我們會去使用這個工具呢?原因是效能表現。如果儲存的資料日益增大,那麼只有僅僅編寫 SQL查詢指標和維度進行,然後建模,最終也會發生問題的,因為效能可能表現上會差強人意。此時如果使用Cube.js這個工具來架構基礎,那麼就能快速簡便的解決這個問題(官網宣稱)。
優點:
它的抽象層:配置 Cube.js 後,人們說他們不再需要擔心效能優化、資源管理、SQL 專業知識等問題。許多人把 Cube.js 稱為 “黑盒”,因為它的抽象層幫助他們專注於理解資料,而不是實施細節。
易於定製:由於 Cube.js 是視覺化的,它很容易與前端框架整合,建立看起來像使用者自己平臺的解決方案。大多數商業平臺(如 Looker、Tableau 等)需要更多的定製工作來與他們的基礎設施整合。許多使用者說,定製的便利性與抽象層相結合,使他們能夠減少資料分析平臺的開發時間。
社群支援:在開始使用 Cube.js 時,人們通常會從社群成員那裡得到幫助(特別是在我們的Slack),許多人提到社群支援是一個關鍵的入門資源。
以上摘錄至https://www.gushiciku.cn/dl/1fpGT/zh-tw


 iThome鐵人賽
iThome鐵人賽