本文將完成:
dataset來源:Kaggle movies.csv
程式碼 參考來源
pypi官網 rank-BM25 安裝+範例
BM25 algorithm是一種優化的TF/IDF檢索方式,運算公式請自行參閱 wikipaedia說明 我們今天只實作 【程式碼在 GitHub】
import套件
from rank_bm25 import BM25Okapi
import pandas as pd
import os
#--- NLP summarize lib
import sumy
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer as sumyToken
from sumy.summarizers.lsa import LsaSummarizer
#--- wordcloud
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from PIL import Image
載入csv 取欄位 “title” “imdb_plot”
# load from csv
df = pd.read_csv('movies.csv',dtype=object)
movies = df[['title','imdb_plot']]
mtitle = movies['title'].astype(str)
mimdb = movies['imdb_plot'].astype(str)
開始使用BM25
#--- tokenize
tokenized_corpus = [doc.split(" ") for doc in mimdb]
#--- initiate
bm = BM25Okapi(tokenized_corpus)
# query --> 要查詢的 字詞
query = "music "
tokenized_query = query.split(" ")
# 計算 BM25 score (log)
scores = bm.get_scores(tokenized_query)
idx = scores.argmax()
scores.argmax() 代表'分數最大'的元素之index ,我們可以使用此index來找出 mtitle[idx] mimdb[idx]文字內容。我們先使用keyword "music"查詢看看:
最佳配對(BM/best match)是第30則,分數是3.11332... ,電影title Amadeus,影評前60個字是The story begins...
idx: 30
3.1133320601273993
Amadeus
The story begins in 1823 as the elderly Salieri attempts sui
如果把每一則的score都印出來看看...
[0. 1.45850928 0. 0. 0. 0.
0. 1.9614662 0. 0. 0. 0.
0. 0. 0. 0. 0. 2.7574558
1.81637605 0. 0. 1.6851387 0. 0.
0. 0. 0. 0. 0. 1.94504518
3.11333206 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 1.9093863
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. ....略
文字雲wordcloud
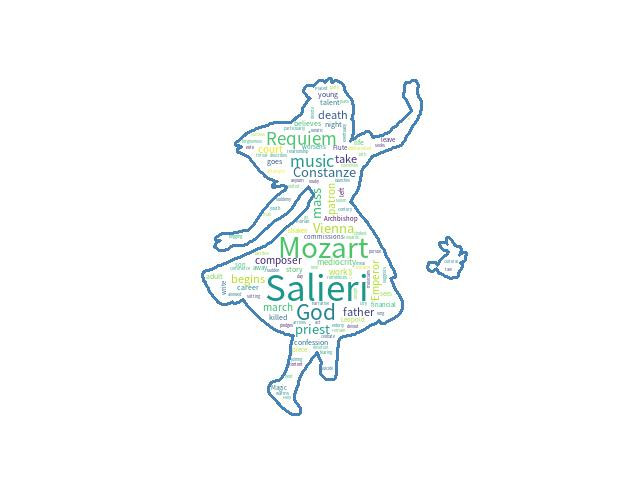
'有圖有真象',Make wordcloud 把該則影評的關鍵字show出來。(使用遮罩alice_mask.png)
cloud.words_ 是一個已經完成排序的 dict,列出前面10個就是了...
-->圖片存檔
#--- make wordcloud
def mkCloud(txt):
mask = np.array(Image.open('alice_mask.png'))
font = 'SourceHanSansTW-Regular.otf'
cloud = WordCloud(background_color='white',mask=mask,font_path=font,
contour_width=3, contour_color='steelblue').generate(txt)
plt.imshow(cloud)
plt.axis("off")
plt.show()
# keywords 已經完成排序的 一個 dict
keywords = cloud.words_
mostly = list(keywords.keys())
print('Top10 keywords: ',mostly[:10])
mostkeys = str(mostly[:10])
pmt = f'Top10 keywords in the text\n{mostkeys}'
print(pmt)
# 將wordcloud 存檔
destFile = 'bmFig.jpg'
cloud.to_file(destFile)
# show image on screen
if os.path.exists(destFile):
img = Image.open(destFile, 'r')
img.show()
top 10 words
Top10 keywords: ['Salieri', 'Mozart', 'God', 'Requiem', 'music', 'priest', 'Vienna', 'Constanze', 'mass', 'begins']
Summarize 三句話,摘要說一下內容
#--- make summary ---
def mkSummText(content):
# Initializing the parser
my_parser = PlaintextParser.from_string(content, sumyToken('english'))
# Creating a summary of 3 sentences
lsa_summarizer = LsaSummarizer()
Extract = lsa_summarizer(my_parser.document,sentences_count=3)
conclusion = []
for sentence in Extract:
#print(sentence)
conclusion.append(str(sentence))
return conclusion
結果,三句話:
>> He believes that God, through Mozart's genius, is cruelly laughing at Salieri's own musical mediocrity.
>> When Salieri learns of Mozart's financial straits, he sees his chance to avenge ...略
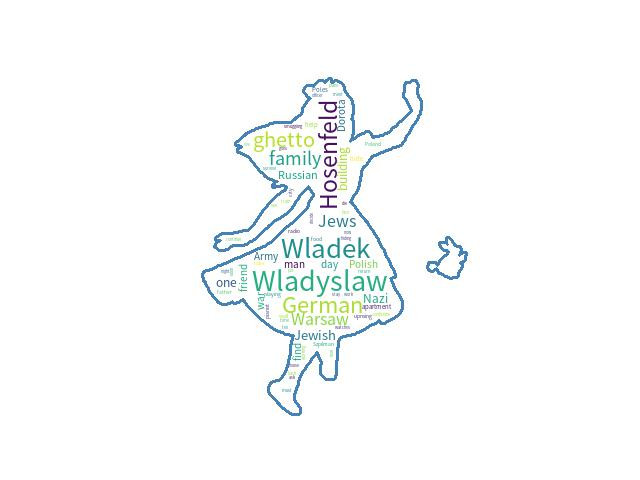
另外改用keyword: 'musician'檢索,結果:
idx: 58
4.300402699706742
The Pianist
"The Pianist" begins in Warsaw, Poland in September, 1939, ...
代碼+csv+ alice_mask.png 在GitHub
 neocaffe
neocaffe

 iThome鐵人賽
iThome鐵人賽