說是多重來源,其實也就是本機和 shioaji 而已,我的想法是這樣子的,如果本機有資料的話,就從本機抓取,如果本機沒有的話就連線到 shioaji 抓取,如果是要跑半年線的資料的話,至少可以省下半年的時間,因為我的目標,可能一天要跑 20 支以上的股票,那這樣子省下來的時間就多了。以下是大概的架構。
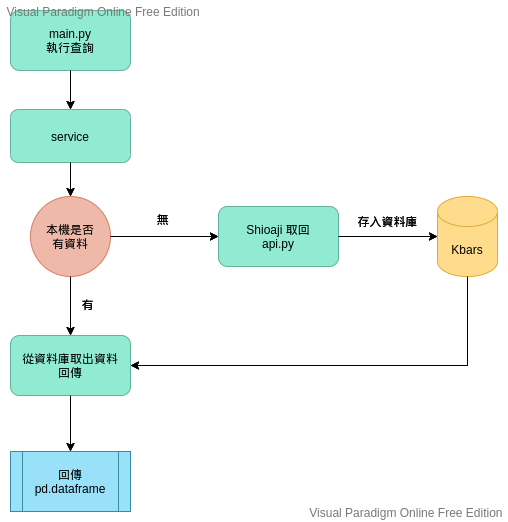
規畫的目錄架構如下:
project
│ main.py
│ service.py
│
└───repository
│ │ databse.py
│ │ models.py
│ │ database.sqlite3 (資料庫檔案)
│ │ api.py (shioaji api)
import shioaji as sj
import pandas as pd
from datetime import datetime
PERSON_ID = "身份證字號"
PASSWD = "密碼"
api = sj.Shioaji()
def getKbarsFromApi(stock_code, start, end):
api.login(person_id=PERSON_ID, passwd=PASSWD)
stock = api.Contracts.Stocks[stock_code]
kbars = api.kbars(stock ,start=start, end=end)
df = __kbarsConvertToDf(kbars)
api.logout()
return df
def __kbarsConvertToDf(kbars):
dts = list(map(lambda x:datetime.utcfromtimestamp(x / 10**9), kbars.ts))
df = pd.DataFrame(
{
"open": pd.Series(kbars.Open),
"high": pd.Series(kbars.High),
"low": pd.Series(kbars.Low),
"close": pd.Series(kbars.Close),
"volume": pd.Series(kbars.Volume),
}
)
df.index = pd.Index(dts)
return df
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
SQLALCHEMY_DATABASE_URL = "sqlite:///repository/database.sqlite3"
engine = create_engine(
SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)
session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
from sqlalchemy import Column, String, DateTime, Integer
from sqlalchemy.sql.sqltypes import Date, Float
from .database import Base
class Kbars(Base):
__tablename__ = 'kbars'
stock_code = Column(String, primary_key=True)
datetime = Column(DateTime(timezone=False), primary_key=True)
open = Column(Float(precision=2))
high = Column(Float(precision=2))
low = Column(Float(precision=2))
close = Column(Float(precision=2))
volume = Column(Integer)
def __init__(self, stock_code, datetime, open, high, low, close, volume):
self.stock_code = stock_code
self.datetime = datetime
self.open = open
self.high = high
self.low = low
self.close = close
self.volume = volume
def __repr__(self):
return "Stock: {} datetime: {} open:{}|high:{}|low:{}|close:{}|vol:{}".format(
self.stock_code, self.datetime, self.open, self.high, self.low, self.close, self.volume)
class OffDays(Base):
__tablename__ = "offDays"
id = Column(Integer, primary_key=True)
date = Column(Date)
def __init__(self, date):
self.date = date
def __repr__(self):
return self.date.strftime("%Y-%m-%d")
from datetime import timedelta, datetime
from sqlalchemy.sql.expression import and_
from repository.api import getKbarsFromApi
from repository.models import Kbars, OffDays
from repository.database import session
from sqlalchemy import func
import pandas as pd
class RangeClass:
'''紀錄要撈取時間範圍的class'''
def __init__(self):
self.start = None
self.end = None
def __repr__(self):
return "{{start: {}, end: {}}}".format(
self.start.strftime("%Y-%m-%d"),
"None" if self.end is None else self.end.strftime("%Y-%m-%d"))
def getKbars(stock_code, start, end):
# 建立 db 連線
db = session()
# 把 db 裡有資料的日期取出來
dbDates = db.query(func.date(Kbars.datetime))\
.filter(and_(func.date(Kbars.datetime) >= start,
func.date(Kbars.datetime) <= end,
Kbars.stock_code == stock_code)).distinct().all()
# 將日期的 string 轉成 date 並存成 list
dbDates = [datetime.strptime(value, "%Y-%m-%d").date() for value, in dbDates]
# 把資料庫裡的 offDays 資料取出
offDays = db.query(OffDays.date).filter(and_(OffDays.date >= start, OffDays.date <= end)).all()
# 存成 list
offDays = [value for value, in offDays]
# 建立日期的 list
dateRange = pd.date_range(start = start, end = end).to_pydatetime().tolist()
# 要從 shioaji 取得的 RangeClass tuple
apiRange = ()
# db 有資料的 RangeClass tuple (可以不用)
dbRange = ()
# api 的 RangeClass
apiRangeObject = RangeClass()
# db 的 RangeClass
dbRangeObject = RangeClass()
# 檢查日期列表,是否在 db 中
for date in dateRange:
if date.date() in dbDates:
# 在 db 裡
if dbRangeObject.start is None:
# 如果 db 的 RangeClass 開始是空的,就設定開始日期
# 因為日期是一個區間,所以只要設一次就可了
dbRangeObject.start = date.date()
if apiRangeObject.start is not None:
# 如果 api 的 RangeClass 開始不是空的, 就設定結束日期, 並放入 apiRange tuple 中
apiRangeObject.end = date.date() - timedelta(days = 1)
apiRange += (apiRangeObject,)
# 重置 api 的 RangeClass
apiRangeObject = RangeClass()
else:
# 不在 db 裡,要從 shioaji 取得
if apiRangeObject.start is None:
# api RangeClass 開始是空的,設定開始日期
if date.date() not in offDays:
# 判斷當天是不是休市,不是休市才進行設定
apiRangeObject.start = date.date()
if dbRangeObject.start is not None:
# 如果 db 的 RangeClass 有開始資料,就設定結束資料,並放入 dbRange tuple 中
dbRangeObject.end = date.date() - timedelta(days = 1)
dbRange += (dbRangeObject,)
# 重置 db 的 RangeClass
dbRangeObject = RangeClass()
# 結束後,檢查 db, api 的 RangeClass,
# 如果有還沒有結束的,就把它結束掉,並放入 tuple 中
if dbRangeObject.start is not None:
dbRangeObject.end = dateRange[-1].date()
dbRange += (dbRangeObject,)
if apiRangeObject.start is not None:
apiRangeObject.end = dateRange[-1].date()
apiRange += (apiRangeObject,)
# api 的 tuple 有資料
if len(apiRange) > 0:
for range in apiRange:
# 呼叫 shioaji 進行抓取
kbars = getKbarsFromApi(stock_code, range.start.strftime('%Y-%m-%d'), range.end.strftime('%Y-%m-%d'))
# 沒有資料,把日期存入 offDays
if len(kbars.index) == 0:
db.add(OffDays(range.start))
nextDay = range.start
while nextDay < range.end:
nextDay += timedelta(days=1)
db.add(OffDays(nextDay))
else:
# 有資料,把資料存到 db
for index, row in kbars.iterrows():
kbar = Kbars(
stock_code, index, row["open"], row["high"], row["low"], row["close"], row["volume"]
)
db.add(kbar)
db.commit()
# 從 db 撈資料並轉成 pd.dataframe
statement = db.query(Kbars.datetime, Kbars.open, Kbars.high, Kbars.low, Kbars.close, Kbars.volume)\
.filter(and_(func.date(Kbars.datetime) >= start,
func.date(Kbars.datetime) <= end,
Kbars.stock_code == stock_code)).statement
df = pd.read_sql(statement, db.bind)
df = df.set_index("datetime")
db.close()
return df
from repository import models
from repository.database import engine
import services
# 這一個是初始化 db 的, 如果是第一次執行的話不能省
models.Base.metadata.create_all(bind=engine)
# 直接呼叫取得資料
kbars = services.getKbars("2412", "2021-10-01", "2021-10-11")
這樣就可以取得我們的資料,之後我希望每天進行當日的資料分析,所以明天我們來實做一下如何進行排程


 iThome鐵人賽
iThome鐵人賽