今天選個大資料集,來試試看BM25的語義搜尋。(據說BM25不必先做”斷詞處理”,說錯了,是不必處理stopwords)
59萬筆COVID-19相關文獻860MB
資料集來源:Kaggle COVID-19 metadata.csv 568,230筆(不重覆者)(title有內容的有48萬筆)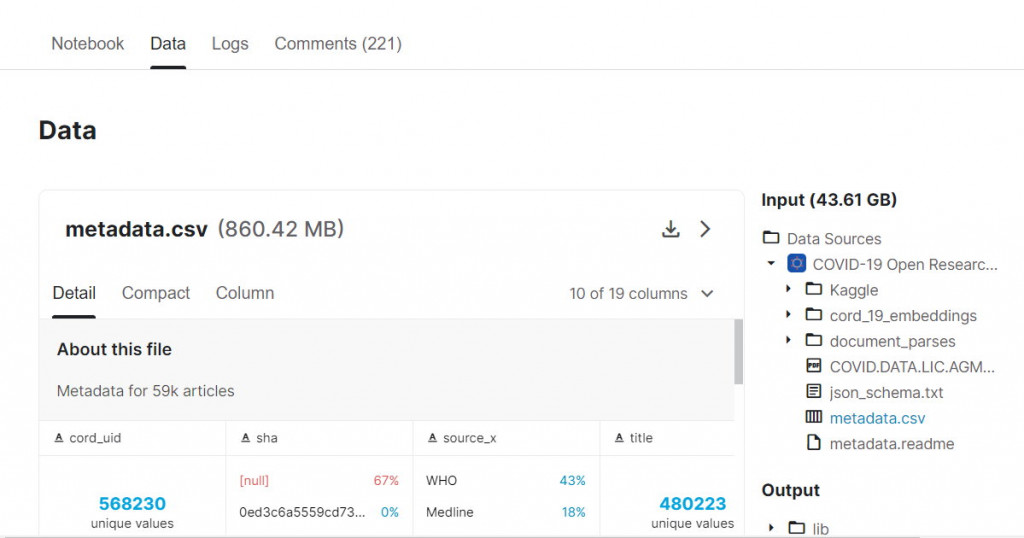
先前兩篇請參考 < 語義檢索 Semantic Search NLP >
< Semantic search BM25 COVID-19 dataset 自然語言BM25搜尋新冠文獻資料>
搜尋關鍵字: Taiwan vaccine mortality
搜尋標的: 文獻Title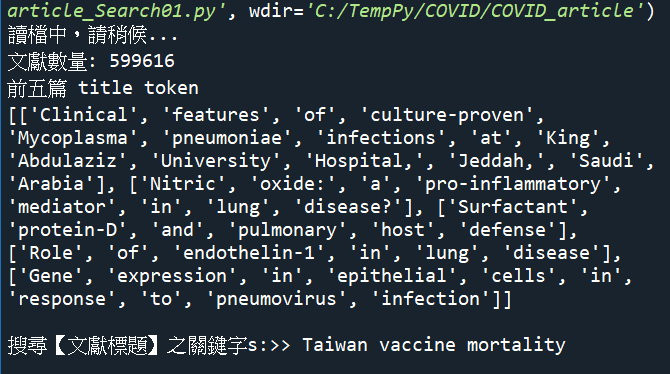
程式就簡單一點,少一點花俏。
''' article_search01.py
searching article title
BM25 method '''
from rank_bm25 import BM25Okapi
import pandas as pd
import numpy as np
''' main flow '''
# load csv file
# https://www.kaggle.com/maksimeren/covid-19-literature-clustering/data?select=metadata.csv
print('讀檔中,請稍候...')
df_raw = pd.read_csv('ArticleCOVID.csv',dtype=object)
# 測試 sample 1萬筆
#df = df_raw.sample(n = 10000, random_state=20)
df = df_raw
#print(df.head())
# 取我們要的相關欄位
mtitle = df['title'].astype(str)
mabs = df['abstract'].astype(str)
murl = df['url'].astype(str)
mpubtime = df['publish_time'].astype(str)
mpmcid = df['pmcid'].astype(str)
mauthor = df['authors'].astype(str)
mjournal = df['journal'].astype(str)
mdoi = df['doi'].astype(str)
#print(len(mtitle),mtitle.shape)
#print(mtitle.iloc[5])
#--- 把文獻title tokenize
tokenized_corpus = [doc.split(" ") for doc in mtitle]
print(f'文獻數量: {len(tokenized_corpus)}')
print(f'前五篇 title token\n{tokenized_corpus[:5]}')
#--- initiate BM25
bm = BM25Okapi(tokenized_corpus)
# query --> 要查詢的 keywords 可多詞,以空格間隔
query = input('搜尋【文獻標題】之關鍵字s:>> ')
tokenized_query = query.split(" ")
print(f'keywords數目: {len(tokenized_query)}\n tokenized: {tokenized_query}')
# 計算 BM25 score (log)
scores = bm.get_scores(tokenized_query)
# sort scores (take index)
s1 = np.argsort(scores)
sidx = s1[::-1] # reverse s1
print(sidx[:10]) # top 10 highest score papers
fw = open('article_result.txt','w',encoding='utf-8')
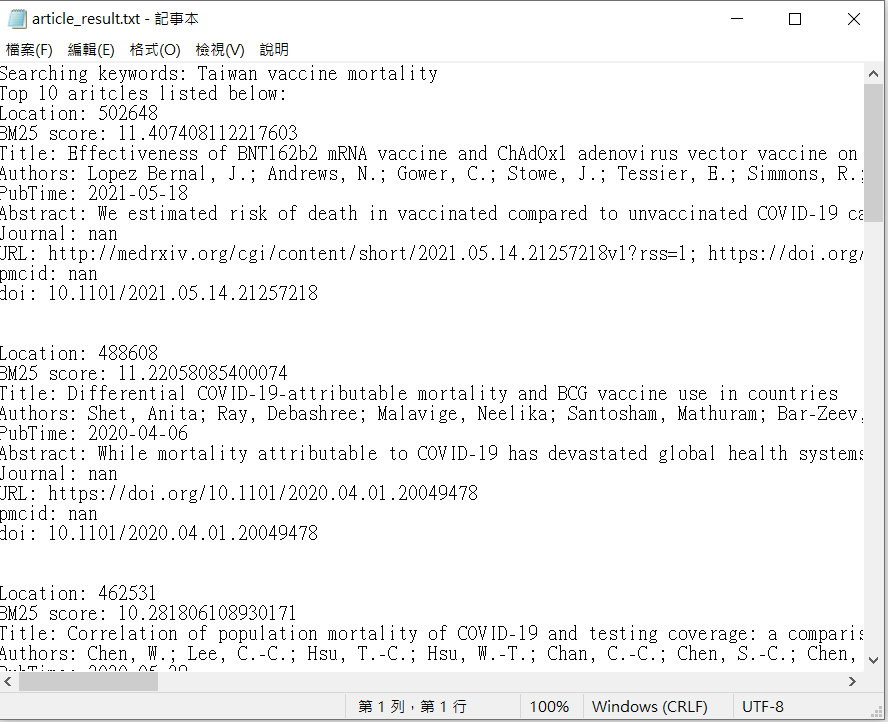
print(f'Searching keywords: {query}')
print('Top 10 aritcles listed below:')
print(f'Searching keywords: {query}',file=fw)
print('Top 10 aritcles listed below:',file=fw)
for i in range(10):
no = sidx[i]
tmp = f'Location: {no}\n'
tmp = tmp + f'BM25 score: {scores[no]}\n'
tmp = tmp + f'Title: {mtitle.iloc[no]}\n'
tmp = tmp + f'Authors: {mauthor.iloc[no]}\n'
tmp = tmp + f'PubTime: {mpubtime.iloc[no]}\n'
tmp = tmp + f'Abstract: {mabs.iloc[no][:500]}\n'
tmp = tmp + f'Journal: {mjournal.iloc[no]}\n'
tmp = tmp + f'URL: {murl.iloc[no]}\n'
tmp = tmp + f'pmcid: {mpmcid.iloc[no]}\n'
tmp = tmp + f'doi: {mdoi.iloc[no]}\n\n'
print(tmp)
print(tmp,file=fw)
fw.close()
print('搜尋結果,已存檔完成: article_result.txt')
 neocaffe
neocaffe

 iThome鐵人賽
iThome鐵人賽