上篇的說明當 b=0 時該如何校正w的, 其實基本上大同小異,都是用相同的方式去校正w
當 b!=0 的時候公式會多個b在算距離的時候先做加減: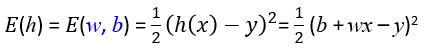
一樣對E(w,b)作偏微分,只需要注意不要微錯就好: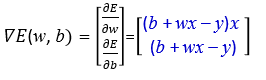
梯度訓練公式: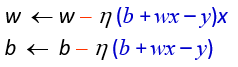
多個屬性的梯度下降跟單個屬性差不多,雖然看起來突然複雜了一點,過程跟流程都跟上面的步驟一致。
假設有M個屬性:
一樣對E(w1,w2,w3,...wM,b)作偏微分: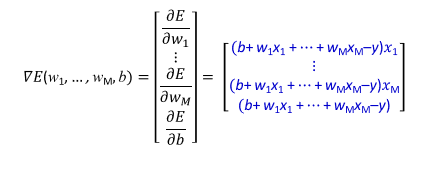
多屬性的訓練公式: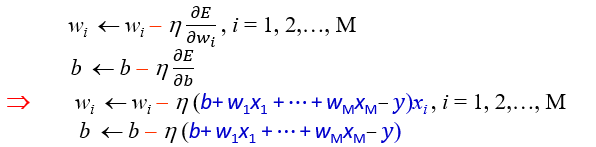
同時被稱為:
在回歸問題時可擁有無限輸出量的值,在分類問題時可以輸出有限的值。
Regression: with numeric output label(s) >> an infinite number of values
Classification: with nominal output label(s) >> a finite number of values
 minimindy
minimindy
