這次要嘗試的是將爬蟲與 line bot做結合,那你可以使用 line bot 就能夠查詢到本周上映的新片。
首先要安裝下列套件
pipenv install requests
pipenv install BeautifulSoup4
pipenv install lxml
import requests
from bs4 import BeautifulSoup
#GET請求
r = requests.get('http://www.atmovies.com.tw/movie/new/')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
print(soup)
為了避免抓取到的內容用 Unicode 解析時出現亂碼,我們可以設定 encoding 為 utf-8。
再來因為想要挖的是本周新片的標題與網址,那我們可以先到網頁那邊看看他的原始碼。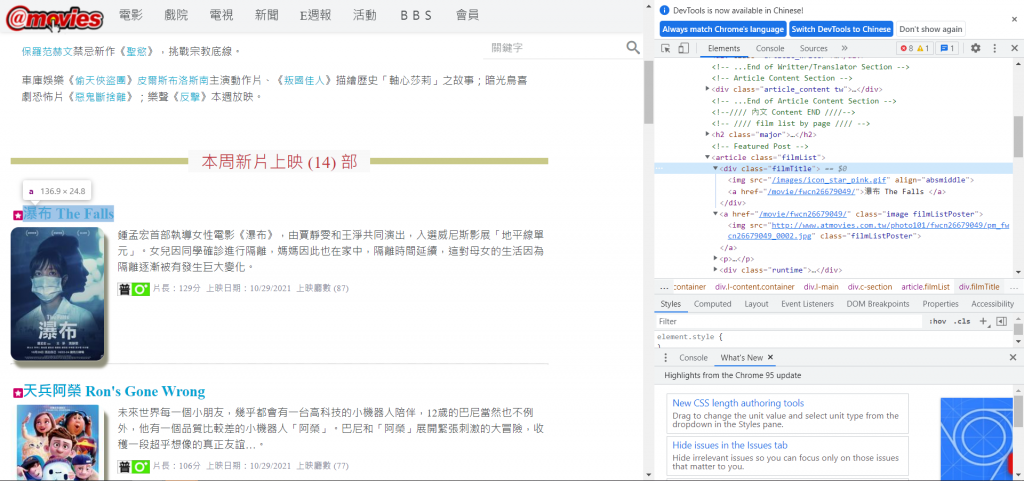
可以看到他的標題與網址部分是在 class 名稱為 filmTitle 的 div 裡面的 a 標籤中。因此,我們可以將程式碼改成下列樣子。
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.atmovies.com.tw/movie/new/')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
filmTitle = soup.select('div.filmTitle a')
print(filmTitle)
輸出結果會是
[<a href="/movie/fwcn26679049/">瀑布 The Falls </a>,
<a href="/movie/fren47504818/">天兵阿榮 Ron's Gone Wrong </a>,
......
]
soup.select('div.filmTitle a')代表的是我們想要取得 class 名稱為 filmTitle 的 div 中的 a 標籤。
但我們只想要 a 標籤內的文字跟網址部分,那就需要更精準的指令。
import requests
from bs4 import BeautifulSoup
r = requests.get('http://www.atmovies.com.tw/movie/new/')
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'lxml')
filmTitle = soup.select('div.filmTitle a')
print(filmTitle[0].text)
print("http://www.atmovies.com.tw/" + filmTitle[0]['href'])
我們只要 filmTitle[0] 裡的文字(也就是第一部電影的名稱),所以使用filmTitle[0].text。
而 href 得內容只有 /movie/fren47504818/,還不是一個有效的網址,所以我們需要在前面加上 http://www.atmovies.com.tw/ 。
 Arashi
Arashi
