由於查詢部分的篇幅相較於前幾者較多,因此將查詢的部分獨立出來寫
另外這邊寫的只有一些基礎的操作,像是 group_by 等稍微進階的操作
之後會另外寫一篇文章來講解
對於文章內容有疑問或是有更好的寫法,歡迎留言討論喔~
由於查詢的資料需要比較多,因此這邊採用 政府資料開放平台 新創圓夢網-創業補給站 的 opendata 來當作操作的資料
這部份如果不是很清楚的話可以參考 這篇文章
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column
from sqlalchemy import Integer, String, DATETIME, TEXT
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
engine_url = "sqlite:///C:\\Users\\nick\\Desktop\\sqlalchemy_test\\test.db"
engine = create_engine(engine_url, echo=True)
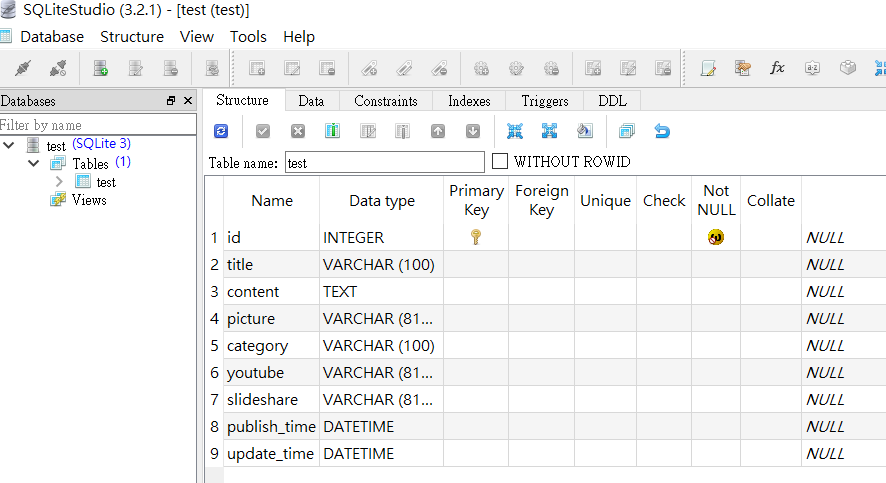
class Test(Base):
__tablename__ = "test"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(100))
content = Column(TEXT)
picture = Column(String(8182)) # Chrome 網址長度上限
category = Column(String(100))
youtube = Column(String(8182)) # Chrome 網址長度上限
slideshare = Column(String(8182)) # Chrome 網址長度上限
publish_time = Column(DATETIME)
update_time = Column(DATETIME)
def create_table():
Base.metadata.create_all(engine)
def drop_table():
Base.metadata.drop_all(engine)
def create_session():
Session = sessionmaker(bind=engine)
session = Session()
return session
if __name__ == '__main__':
drop_table()
create_table()
from main import create_session
from main import Test
import requests
import json
from datetime import datetime
url = "https://sme.moeasmea.gov.tw/startup/upload/opendata/gov_infopack_opendata.json"
res = requests.get(url)
datas = json.loads(res.text)
for item in datas:
data_obj = {
"title": item["標題"],
"content": item["內容"],
"picture": item["主圖"],
"category": item["分類"],
"youtube": item["youtube嵌入代碼"],
"slideshare": item["slideshare嵌入代碼"],
"publish_time": datetime.strptime(item["建立時間"], "%Y%m%d%H%M%S"),
"update_time": datetime.strptime(item["修改時間"], "%Y%m%d%H%M%S")
}
session = create_session()
session.add(Test(**data_obj))
session.commit()
session.close()
語法: result = session.query(Test).first()
註: first() 會回傳第一筆資料,另外可使用 all() 來讀取全部的資料,於第二段會講解
利用欄位取得資料
from main import create_session
from main import Test
session = create_session()
result = session.query(Test).first()
print(result.id)
print(result.title)
output:
C:\Users\nick\Desktop\sqlalchemy_test\venv\Scripts\python.exe C:/Users/nick/Desktop/sqlalchemy_test/test.py
1
test1133
Process finished with exit code 0
from main import create_session
from main import Test
from pprint import pprint
session = create_session()
result = session.query(Test).first()
pprint(result.__dict__) # pprint 用於美化輸出
output:
C:\Users\nick\Desktop\sqlalchemy_test\venv\Scripts\python.exe C:/Users/nick/Desktop/sqlalchemy_test/test.py
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000001471DB84880>,
'category': '活動專頁',
'content': '3213123213',
'id': 1,
'picture': 'http://sme.moeasmea.gov.tw/startup/upload/infopack/20200525112659agd.jpg',
'publish_time': datetime.datetime(2020, 5, 25, 11, 26, 59),
'slideshare': '',
'title': 'test1133',
'update_time': datetime.datetime(2020, 6, 9, 2, 46, 21),
'youtube': ''}
Process finished with exit code 0
此部分操作原理同 first(),只不過會將每一筆資料加到一個 list 當中
我們可以利用迴圈進行拜訪
from main import create_session
from main import Test
session = create_session()
result = session.query(Test).all()
for row in result:
print(row.id, end=" ")
print(row.title)
output:
C:\Users\nick\Desktop\sqlalchemy_test\venv\Scripts\python.exe C:/Users/nick/Desktop/sqlalchemy_test/test.py
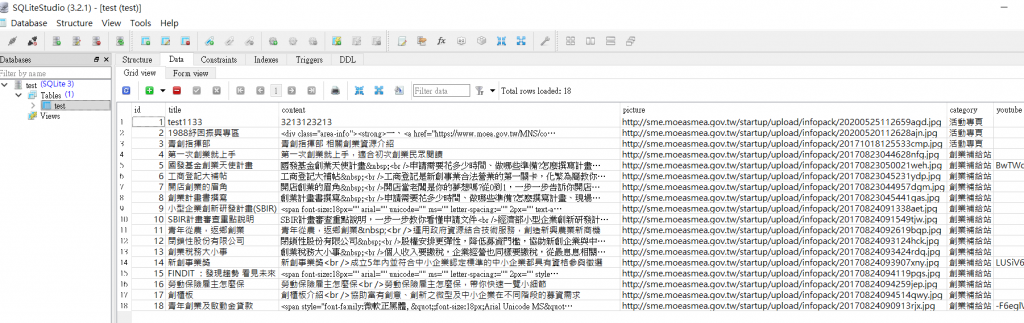
1 test1133
2 1988紓困振興專區
3 青創指揮部
4 第一次創業就上手
5 國發基金創業天使計畫
6 工商登記大補帖
7 開店創業的眉角
8 創業計畫書撰寫
9 小型企業創新研發計畫(SBIR)
10 SBIR計畫審查重點說明
11 青年從農,返鄉創業
12 閉鎖性股份有限公司
13 創業稅務大小事
14 新創事業獎
15 FINDIT :發現趨勢 看見未來
16 勞動保險雇主怎麼保
17 創櫃板
18 青年創業及啟動金貸款
Process finished with exit code 0
以下的範例透過表的欄位來進行簡單的篩選,日後有機會會再補上
進階的 filter_by 用法,此方法同樣適用於 first() 以及 all()
from main import create_session
from main import Test
from pprint import pprint
session = create_session()
result = session.query(Test).filter_by(id=3).first()
pprint(result.__dict__)
output:
C:\Users\nick\Desktop\sqlalchemy_test\venv\Scripts\python.exe C:/Users/nick/Desktop/sqlalchemy_test/test.py
{'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x000001F6393666A0>,
'category': '活動專頁',
'content': '青創指揮部 相關創業資源介紹',
'id': 3,
'picture': 'http://sme.moeasmea.gov.tw/startup/upload/infopack/20171018125533cmp.jpg',
'publish_time': datetime.datetime(2017, 10, 18, 12, 55, 33),
'slideshare': '5n28zWztX1TN1P',
'title': '青創指揮部',
'update_time': datetime.datetime(2020, 5, 15, 10, 52, 23),
'youtube': ''}
Process finished with exit code 0
當資料量過大,一次性將資料吐回來給使用者可能會造成使用者電腦無法負荷
因此可以透過分頁的功能來減少回傳的資料,其實就是 SQL 當中的 offset、limit
簡單範例:
from main import create_session
from main import Test
session = create_session()
result = session.query(Test).filter_by(category="創業補給站").offset(2).limit(5).all()
# 顯示取得幾筆
print(f"總共取得 {len(result)} 筆資料")
# 利用迴圈拜訪資料
for row in result:
print(row.id, end=" ")
print(row.title)
output:
C:\Users\nick\Desktop\sqlalchemy_test\venv\Scripts\python.exe C:/Users/nick/Desktop/sqlalchemy_test/test.py
總共取得 5 筆資料
6 工商登記大補帖
7 開店創業的眉角
8 創業計畫書撰寫
9 小型企業創新研發計畫(SBIR)
10 SBIR計畫審查重點說明
Process finished with exit code 0
顧名思義就是按照指定欄位將資料進行排序並輸出,此操作同樣能搭配 first()、all()
簡單範例:
註: desc() 為降冪、asc()為升冪
註: 若資料欄位為 DATETIME 型態,即可根據時間先後順序進行排序
from main import create_session
from main import Test
session = create_session()
result = session.query(Test).order_by(Test.publish_time.desc()).all()
# 利用迴圈拜訪資料
for row in result:
print(row.id, end=" ")
print(row.title, end=" ")
print(row.publish_time)
output:
C:\Users\nick\Desktop\sqlalchemy_test\venv\Scripts\python.exe C:/Users/nick/Desktop/sqlalchemy_test/test.py
1 test1133 2020-05-25 11:26:59
2 1988紓困振興專區 2020-05-20 11:26:28
3 青創指揮部 2017-10-18 12:55:33
17 創櫃板 2017-08-24 09:45:02
16 勞動保險雇主怎麼保 2017-08-24 09:42:59
15 FINDIT :發現趨勢 看見未來 2017-08-24 09:41:07
14 新創事業獎 2017-08-24 09:39:07
13 創業稅務大小事 2017-08-24 09:34:24
12 閉鎖性股份有限公司 2017-08-24 09:31:24
11 青年從農,返鄉創業 2017-08-24 09:26:19
10 SBIR計畫審查重點說明 2017-08-24 09:15:49
9 小型企業創新研發計畫(SBIR) 2017-08-24 09:13:38
18 青年創業及啟動金貸款 2017-08-24 09:09:13
5 國發基金創業天使計畫 2017-08-23 05:00:21
8 創業計畫書撰寫 2017-08-23 04:54:41
6 工商登記大補帖 2017-08-23 04:52:31
7 開店創業的眉角 2017-08-23 04:49:57
4 第一次創業就上手 2017-08-23 04:46:28
Process finished with exit code 0
 熊熊工程師
熊熊工程師
