上一集當中我們完成了Lucene基本操作中的Create與Read,這一集會將CRUD中的Update與Delete的操作方法告訴你,並且本集會著重於講解關於"Norms"與權重(Boost)在Lucene中的使用操作。
對於Lucene還沒有一些基本認識的朋友,建議先回到上一篇文章中閱讀呦!
更新其實就是將存在的索引刪除並重新建立Document,不存在的則直接新增。
首先準備一組資料準備更新
List<Product> GetUpdateProductsInformation()
{
return new List<Product>
{
new Product{ Id = 6, Name = "香蕉", Description = "運動完後吃根香蕉補充養分。"},
new Product{ Id = 2, Name = "橘子", Description = "橘子跟柳丁你分得出來嗎?"}
};
}
欲更新的Document必須與創建所引時使用的Document欄位相同
void Update(string key, List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using( var directory = FSDirectory.Open(dir))
{
using(var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
indexWriter.UpdateDocument(new Term("Name", key) ,document);
}
}
}
}
來測試看看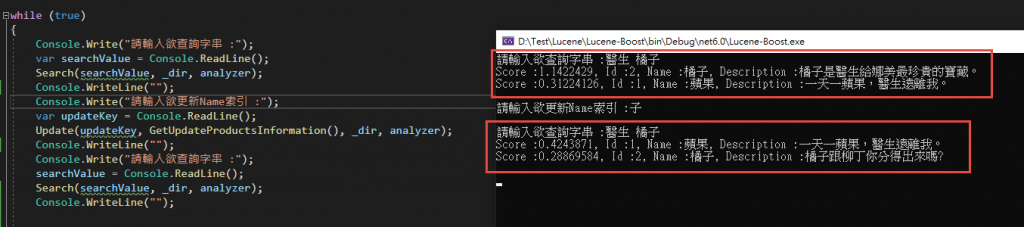
可以看見 Name = 橘子 的索引已經改為我們新準備的資料囉。
再來是刪除!
與更新非常相似,只需要使用deleteDocument()就可以了。
void Delete(string key, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, false, IndexWriter.MaxFieldLength.LIMITED))
{
indexWriter.DeleteDocuments(new Term("Name", key));
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
再來看看輸出結果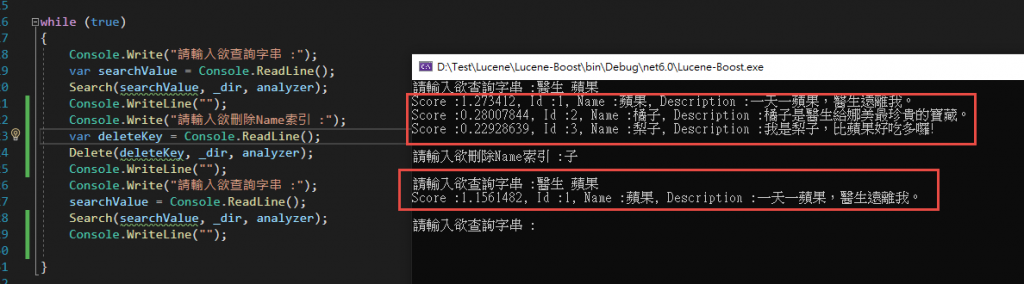
可以發現 Score :0.7554128, Id :2, Name :橘子, Description :醫生給娜美最珍貴的寶藏。這筆索引已經被移除囉!
可以發現筆者於更新或刪除時都是輸入單一字來做異動,除了表達可以對索引做複合更動外,
是因為更新與刪除索引同樣會使用到分詞器(analyzer),
所輸入的索引值非ID等數值時必須要配合分詞器的分詞能力才能取得所想異動的索引喔!
Boost是什麼呢?
Boost 分為 :
void CreateIndexWithBoost(List<Product> information, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(dir))
{
using (var indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED))
{
foreach (var index in information)
{
var document = new Document();
document.Add(new Field("Id", index.Id.ToString(), Field.Store.YES, Field.Index.NO));
document.Add(new Field("Name", index.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Description", index.Description, Field.Store.YES, Field.Index.ANALYZED));
document.GetField("Name").Boost = 1.5F;
document.GetField("Description").Boost = 0.5F;
indexWriter.AddDocument(document);
}
indexWriter.Optimize();
indexWriter.Commit();
}
}
}
並記得重新CreateIndex才能刷新欄位的權重值喔。
很明顯的搜尋出來的Score分數變動了! 但是有沒有發現明明Name欄位的Boost改成了1.5,蘋果的數值卻仍然只有一半呢?
這是因為我們的Search中所參照的欄位為Description,所以在計算Score的時候其實是完全沒有參與的喔!
另外要記得,使用Index Time Boost的時候,欲給予銓重分配的欄位Field.Index不能使用NO_NORMS,不然這個欄位並不會紀錄權重的資料。
再來我們試試看Query Time Boost
void SearchWithBoost(string searchValue, DirectoryInfo dir, StandardAnalyzer analyzer)
{
using (var directory = FSDirectory.Open(_dir))
{
using (var indexSearcher = new IndexSearcher(directory))
{
var query = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Name", analyzer).Parse(searchValue);
var query2 = new QueryParser(Lucene.Net.Util.Version.LUCENE_CURRENT, "Description", analyzer).Parse(searchValue);
query.Boost = 2.0F;
query2.Boost = 0.5F;
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.Add(query, Occur.SHOULD);
booleanQuery.Add(query2, Occur.SHOULD);
var hits = indexSearcher.Search(booleanQuery, 20);
if (!hits.ScoreDocs.Any())
{
Console.WriteLine("查無相關結果。");
return;
}
Document doc;
foreach (var hit in hits.ScoreDocs)
{
doc = indexSearcher.Doc(hit.Doc);
Console.WriteLine("Score :" + hit.Score + ", Id :" + doc.Get("Id") + ", Name :" + doc.Get("Name") + ", Description :" + doc.Get("Description"));
}
}
}
}
這次我們搜尋兩個欄位"Name"與"Description",並使用 BooleanQuery來將其組合。
BooleanQuery中的 Occur有三種參數 : "MUST","MUST_NOT","SHOULD",功能與字面上的意思一樣為"必須要有","必須沒有"與"有無都包含"。
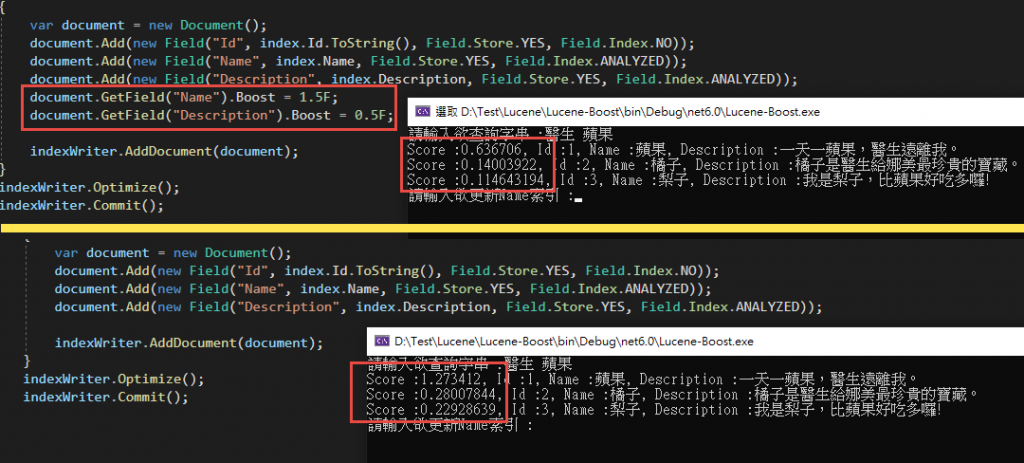
查詢出來的分數就不一樣囉!
以上就是這一次的分享,Lucene是一款容易入門但是要實際上戰場卻又十分複雜的功能,想要達成真正高效能的全文檢索,在前期的文件規畫配置與資料的權重配比都是一個巨大的挑戰。未來會繼續分享關於Lucene的其他有趣功能,還請繼續期待呦!
另外也可以到我的GitHub下載範例來參考呦!
參考文件:
 bodera
bodera

 iThome鐵人賽
iThome鐵人賽