經過昨天使用DNN辨識手寫圖片,有沒有發現再怎麼調整參數,準確率都上不去了呢?
這是因為DNN的演算法就只能有這樣的效果,那我們要怎麼提高準確率呢?
也就是今天的主題卷積神經網路(Convolutional neural network)
跟昨天一樣先放一張架構圖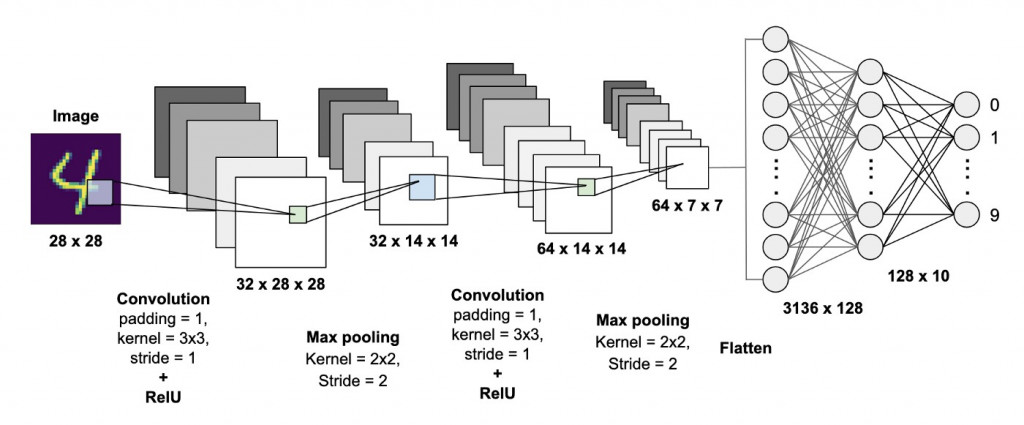
圖片來源:https://becominghuman.ai/building-a-convolutional-neural-network-cnn-model-for-image-classification-116f77a7a236
看到圖片後有沒有注意到攤平(Flatten)後的部分,是不是與昨天學習到到DNN相同,那兩者差別在哪呢?答案就是CNN會通過捲積(Convolution)、池化(Pooling)等運算方式提取出更重要的特徵,通過攤平(Flatten)將特徵放入到全連接層(DNN也是種全連接神經網路)的架構當中,得到更好的輸出結果。
知道上述的概念之後,接下來開始更深入的介紹捲積層(Convolution Layer)、池化層(Pooling Layer)、全連接層(Fully Connected Layer)究竟是什麼。
捲基層的原理是利用卷積核(Kernel)通過步長(Stride)的滑動對圖像提取訊息,若超過圖片大小則會對其填充(Padding)補值,我們用例子來說明:
可以看到圖片中兩個英文單字X與A,那怎麼知道哪圖片是X又哪張圖片是A呢?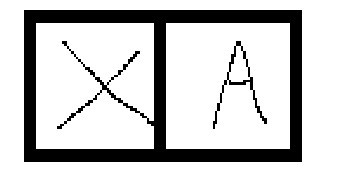
我們可以先畫個方框將圖片拆解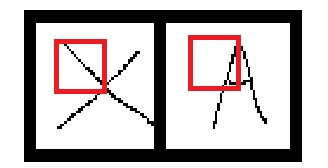
這時候就能用些較簡單的邏輯分辨出特徵,例如:X左上角的區塊是由左上到右下畫出來的,而A左上角的區塊則是右上往左下畫出來的。在圖片中的紅框處,它會先加總方框內的圖像數值之後與卷積核相乘,並通過步長移動方框的位置,產生出新的陣列。
我們架構圖的例子計算一次
圖片的大小是28x28,而我們的捲積核大小為3x3,步長為1,那麼新的陣列大小就會是28(往右)/1(步長)x28(往下)/1(步長)=28x28。
但在例子中3x3的捲積核移動26次(26+3)時就會發現超出圖片的範圍了,那該怎麼辦?這時候會使用填充的技巧,把超出外框的值做墊零(zero padding),這樣子就可以防止發生陣列大小不相等的問題了。
當經過捲積層計算之後我們會取的一個含有圖片特徵陣列,而在那麼在這一層的工作就是利用pooling的方式處理這些特徵。
我們先來看到圖片中的MaxPooling是什麼?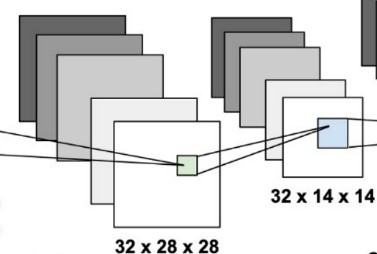
我們可以看到經過MaxPooling後的陣列大小從28x28變成了14x14這是因為MaxPooling只會保留選取範圍的最大值,這樣子可以有效的取得特徵、並移除雜訊(noize),同時縮減陣列大小從而提高運算速度。
我們在前面的兩層看到的動作都是在做特徵擷取與強化,到了這層才是真正學習的過程,概念與我們昨天說到的DNN是相同的,這邊就不在講解了,如果沒有跟上的人可以到昨天的課程【day3】Deep Neural Network MNIST手寫辨識學習相關知識
今天的實作會分成以下的部分:
1.導入函式庫與介紹
2.資料前處理
3.建構網路&訓練模型
4.儲存模型
5.評估模型
import numpy as np
import tensorflow.keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential,load_model,model_from_json
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.utils import to_categorical
from PIL import Image
import matplotlib.pyplot as plt
函式庫說明:
1.keras.datasets:包含著一些著名的資料集例如:nmist、IMDB影評
2.keras.models:架構神經網路、與神經網路相關操作
3.keras.layers:創建神經網路Dense(DNN)、conv2d(CNN)
4.keras.utils:資料正規化
5.PIL:圖像相關操作
6.matplotlib.pyplot:繪畫表格
我們今天使用的架構為CNN,當使用不同架構時都需要注意他的input_shape,在CNN中輸入則是(長,寬,色彩),經過昨天的實作我們知道我們的資料是(長,寬),所以在這邊我們只需要稍微修改昨天的作法將維度reshape成(長,寬,色彩)就可以了。
#讀取資料
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#CNN的輸入為(長,寬,色彩) 1代表黑白 3代表彩色
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#正規化圖像
x_train = x_train/255
x_test = x_test/255
#將label轉換為label
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
這次選用的激勵函式都與昨天的實作相同,我們只需加入三層網路分別是捲積層Conv2D、池化層MaxPooling2D與攤平Flatten就能使網路從DNN架構轉變成CNN架構。
#建構網路
model = Sequential()
#CNN輸入為(長*寬*色彩)
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
#池化層(找最大值不用激勵函數)
model.add(MaxPooling2D(pool_size = 2))
#攤平(攤平不用激勵函數)
model.add(Flatten())
#全連接層
model.add(Dense(16, activation = 'relu'))
#輸出層
model.add(Dense(10, activation = 'softmax'))
# 宣告loss finction與optimizer
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 開始訓練model batch_size一次丟多少資料進去訓練 epochs總共要訓練幾次
history = model.fit(x_train, y_train,
batch_size=64,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
-----------------------------------顯示-----------------------------
Epoch 10/10
938/938 [==============================] - 9s 9ms/step - loss: 0.0424 - accuracy: 0.9973 - val_loss: 0.1313 - val_accuracy: 0.9836
val_accuracy: 0.9836是不是比之前DNN跑出來的準確率還要高呢!!
在keras中model有兩種儲存的方式:分別是model.save與model.save_weights,這兩者差別就在於是否有神經網路。
若我們使用model.save儲存模型,需要使用load_model讀取檔案
#儲存model(包含網路)
model.save('model.h5')
#讀取整個model
model = load_model('model.h5')
若是使用model.save_weights,需重新定義原本的神經網路以及使用load_weights讀取檔案
#只儲存權重
model.save_weights('model_weights.h5')
#需重新定義網路
model = Sequential()
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
model.add(MaxPooling2D(pool_size = 2))
model.add(Flatten())
model.add(Dense(16, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
#讀取權重
model.load_weights('model_weights.h5')
當訓練好一個模型之後要怎麼知道這模型好不好呢?我們要先了解什麼是過擬合(Overfitting)與欠擬合(Underfitting)。
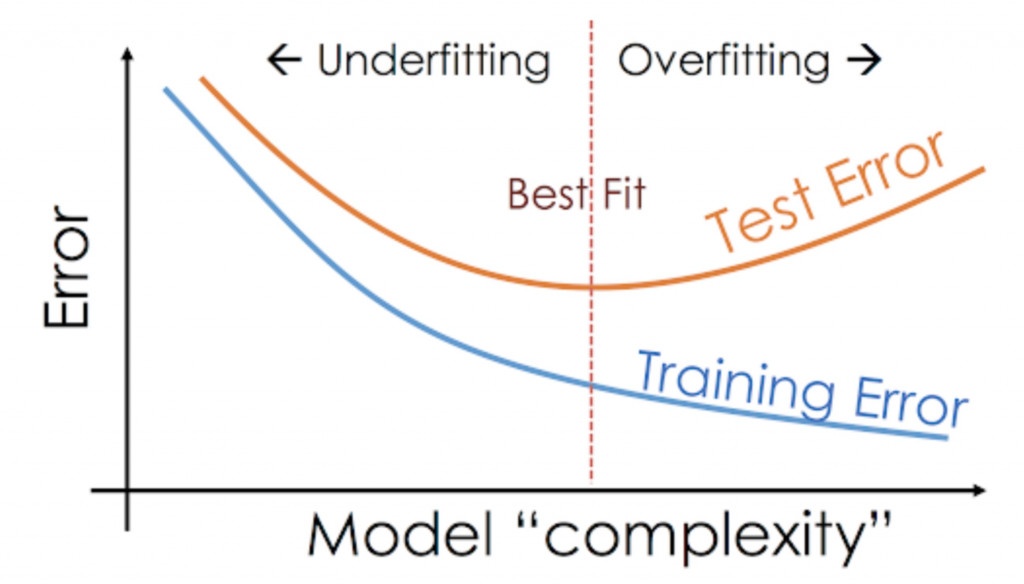
圖片來源:https://www.analyticsvidhya.com/blog/2020/02/underfitting-overfitting-best-fitting-machine-learning/
過擬合(Overfitting):是因為過度學習訓練資料,而變得無法順利去預測或分辨不是在訓練資料內的其他資料,也就是在圖片的右半邊train loss下降,但test loss卻不會再變動了甚至往上升的趨勢。
欠擬合(Underfitting):通常會發生在模型參數過少、模型結構過於簡單或資料過於雜亂時,導致無法捕捉到資料中的規律的現象,也就是我們圖片的左半邊,test loss始終追不上train loss。
現在我們開始寫程式來繪出train loss與test loss的折線圖找到最好的訓練次數吧!!
我們先來查看訓練過程中的到的loss值
print('train loss:',history.history['loss'],'\n\ntest loss:',history.history['val_loss'])
------------------------------------顯示------------------------------------
train loss: [0.41220638155937195, 0.1390567123889923, 0.09521930664777756, 0.07572223246097565, 0.06420597434043884, 0.05522913485765457, 0.049094390124082565, 0.04410300403833389, 0.03952856734395027, 0.03593530133366585]
test loss: [0.16896437108516693, 0.10513907670974731, 0.08054570108652115, 0.06564835458993912, 0.06614525616168976, 0.05308758467435837, 0.053389910608530045, 0.052831731736660004, 0.05826638638973236, 0.05463290959596634]
我們可以看到keras會把每次epoch計算的loss值存成一個list,那我們就可以使用matplotlib.pyplot快速的畫出一張折線圖。
#train loss
plt.plot(history.history['loss'])
#test loss
plt.plot(history.history['val_loss'])
#標題
plt.title('Model loss')
#y軸標籤
plt.ylabel('Loss')
x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['Train', 'Test'], loc='upper left')
#顯示折線圖
plt.show()
這樣我們就能觀察到在第5或6次就會是模型最佳的結果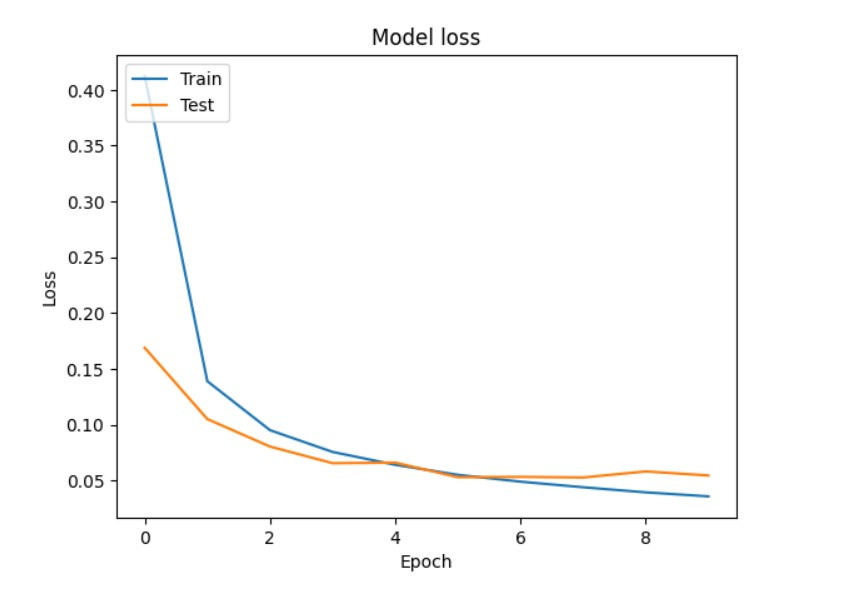
那們今天就到這邊,到現在程式都很簡單吧只需要了解一些理論就能簡單的實作出來,明天會來教近期最後一堂理論課程LSTM,之後就來玩點日常生活中AI的應用吧
import numpy as np
import tensorflow.keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential,load_model,model_from_json
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.utils import to_categorical
from PIL import Image
import matplotlib.pyplot as plt
#讀取資料
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#CNN的輸入為(長,寬,色彩) 1代表黑白 3代表彩色
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#正規化圖像
x_train = x_train/255
x_test = x_test/255
#將label轉換為label
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#建構網路
model = Sequential()
#CNN輸入為28*28*1
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
#池化層
model.add(MaxPooling2D(pool_size = 2))
#攤平
model.add(Flatten())
#全連接層
model.add(Dense(16, activation = 'relu'))
#輸出層
model.add(Dense(10, activation = 'softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
#儲存model(包含網路)
model.save('model.h5')
#讀取整個model
model = load_model('model.h5')
#只儲存權重
model.save_weights('model_weights.h5')
#需重新定義網路
model = Sequential()
model.add(Conv2D(32, kernel_size = 3, input_shape = (28,28,1),padding="same", activation = 'relu'))
model.add(MaxPooling2D(pool_size = 2))
model.add(Flatten())
model.add(Dense(16, activation = 'relu'))
model.add(Dense(10, activation = 'softmax'))
#讀取權重
model.load_weights('model_weights.h5')
課程中的程式碼都能從我的github專案中看到
https://github.com/AUSTIN2526/learn-AI-in-30-days


 iThome鐵人賽
iThome鐵人賽