昨天非常簡要的帶過爬蟲,今天來稍微帶過下。
以下是使用requests爬蟲的大略流程。
先講下常使用到的套件:
這是青島社區動物園 aka 成功高中的學校首頁。
假設我們今天要來把他第一頁的公告標題全部存下來。
先找到那個一堆公告的地方,接著打開你的網頁開發工具。
主流瀏覽器(Edge, Firefox, Google)都是按下F12就能叫出來。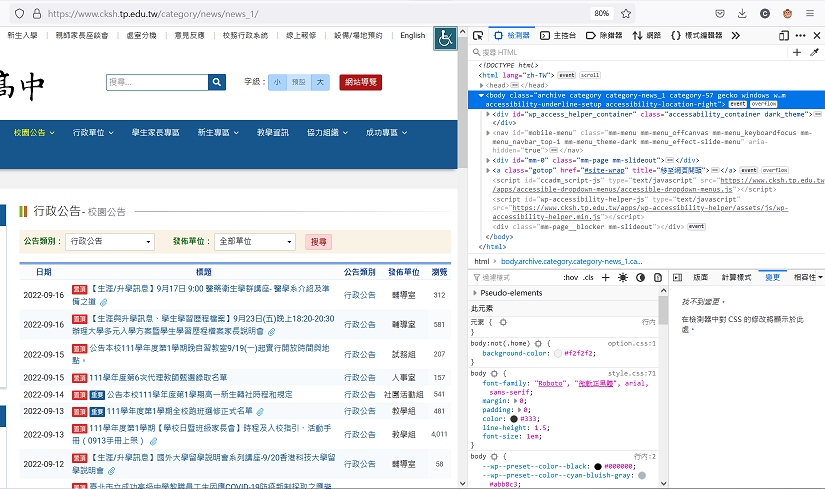
接著按一下左上角這個超好用的小箭頭,點一下你想要爬的位置。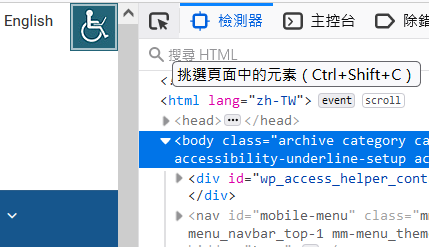
如圖,他就能顯示這個元素在HTML的位置。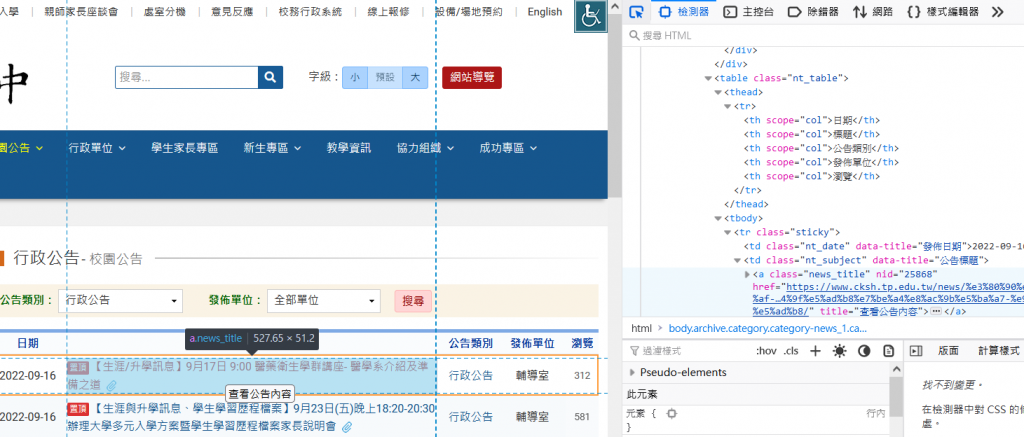
這裡可以發現文字還是沒出現,於是再點一下元素的尾部的'...'把他更展開一點。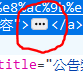
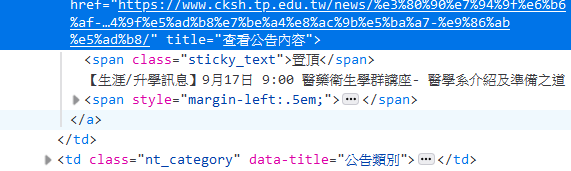
好耶,找到了,讚。
在點了幾個公告的標題後,可以發現這些標題都在a的標籤下並擁有著名為'news_title'的class下
現在就可以理出要怎麼爬下這些公告標題了,使用requests抓下整個網頁後再用Beautifulsoup解析網頁再透過上面這行的資訊來定位出所有的標題並輸出。
接下來幾天會慢慢講到的,大概。
那如果今天是要用xpath呢?
如下圖在元素上按右鍵後也能通過開發者工具直接複製下來xpath,真是好文明。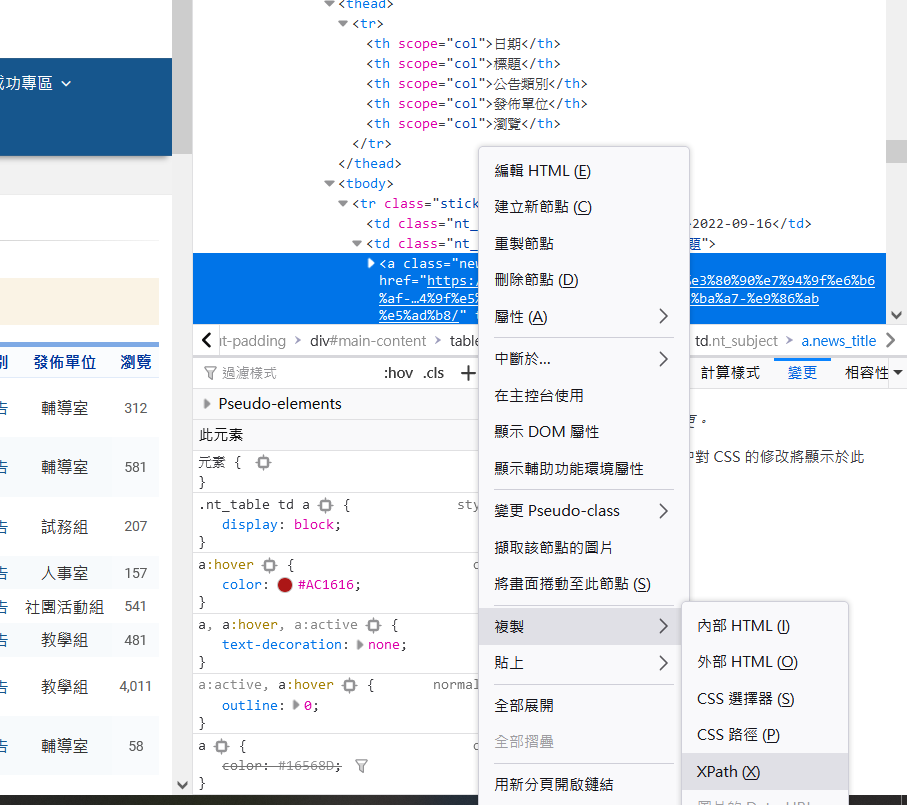
但這樣複製下來當然是只有第一條公告的路徑就是了。
具體要怎麼寫跟與beautifulsoup的詳細區別之後會講到的,大概。

 iThome鐵人賽
iThome鐵人賽