資料在第一次從磁碟中讀出之後會進入到記憶體快取,之後再次使用時如果還在記憶體的裡面,速度會比直接從硬碟裡讀取快上許多。PostgreSQL透過作業系統以及檔案系統來維護資料在系統上的儲存,所以也會使用到作業系統對於檔案所做的記憶體快取,但是PostgreSQL裡面也有一個shared_buffers參數,是用來調整Postgres針對資料庫檔案自行維護的快取區大小。
(來源:https://www.interdb.jp/pg/pgsql08.html)
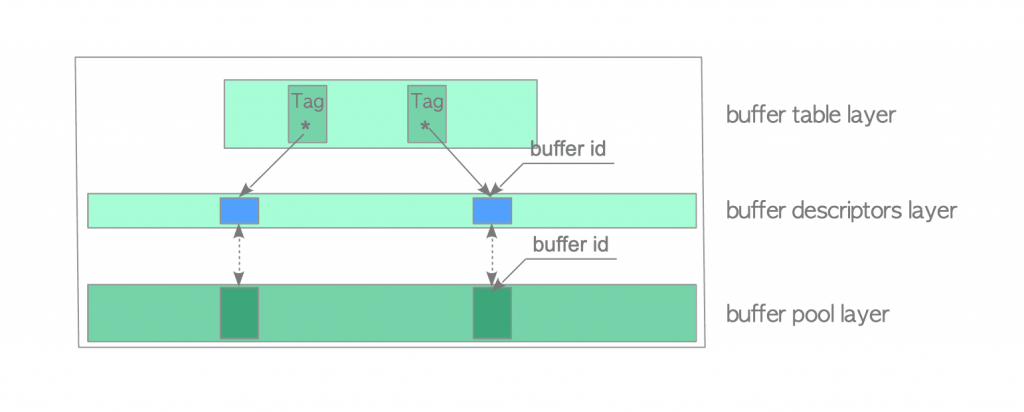
Postgres的buffer manager緩衝區管理可以分為三層:
建立一個buffer table,用hash table的方式,將一個buffer tag作為key。buffer tab紀錄了一組relation的OID,fork number(MAIN/VISIBILITY MAP OR FREE SPACE MAP)以及在檔案中對應的block相對位置。透過buffer tag進行hash function之後,可以找到對應的buffer descriptor。
buffer descriptor紀錄buffer tag/ref_count/usage_count/該buffer slot在shared_buffers中的位置還有一些表達buffer slot當前狀態的資訊。
buffer pool layer為一個陣列,存放整個shared_buffers,大小為postgres block(預設8k byte)的倍數。
PostgreSQL採用clock sweep演算法,所以PostgreSQL的Buffer manager會對共享緩衝區裡面的每一個block紀錄兩個變數:ref_count代表現在正在使用該區塊的程序數量,而usage_count代表該區塊被使用的次數,在被一個process使用過後會被加一。
當Postgres的shared_buffers共用緩衝區已經被占滿,而新的磁碟塊又被讀入,需要挑選一個block將其移出緩衝區以提供新的block使用空間,Postgres會從上次分配Buffer的位置開始往後尋找是否有ref_count跟usage_count皆為零的buffer,如果有的話就將它選為淘汰的對象,否則就將其usage_count減一之後檢查下一個。這樣子的設計相較於一般作業系統的緩衝區置換方法,能夠讓使用率高的資料有更大的機率留在快取裡面。
另外PostgreSQL也有buffer ring的策略,在一次操作裡面只分配一小部分的buffer cache,來避免大量讀寫操作將cache內容全部刷掉的情形,好比大型table的sequential scan。
在資料庫上啟用這個元件,可以幫助我們查看Postgres shared buffers的使用情形。
//啟用附加元件
test=# CREATE EXTENSION pg_buffercache;
CREATE EXTENSION
//下面是pg_buffercache提供的欄位,我們可以透過這個view查詢出shared_buffer中的每一個block他是來自哪個檔案,是否和硬碟上不一致(dirty)以及他最近被使用/現在正在使用之程序數量的計數。
test=# \d pg_buffercache
View "public.pg_buffercache"
Column | Type | Modifiers
-----------------+----------+-----------
bufferid | integer |
relfilenode | oid |
reltablespace |oid |
reldatabase |oid |
relforknumber |smallint |
relblocknumber |bigint |
isdirty |boolean |
usagecount |smallint |
pinning_backends|integer |
這些資訊經過SQL指令的整理與分析,搭配其他的system catalog查詢資訊做join可以做出進一步的分析。例如以下query可以查看每個table在shared_buffers中有多少的block是被快取起來的
test=# SELECT relname,
relkind,
count(*),
count(*) FILTER (WHERE isdirty = true) AS dirty
FROM pg_buffercache AS b, pg_database AS d, pg_class AS c
WHERE d.oid = b.reldatabase
AND c.relfilenode = b.relfilenode
AND datname = 'test'
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 7;
relname | relkind| count| dirty
---------------------------+--------+-------+-------
t_bloom | r | 8338 | 0
idx_bloom | i | 1962 | 0
idx_id | i | 549 | 0
t_test | r | 445 | 0
pg_statistic | r | 90 | 0
pg_depend | r | 60 | 0
pg_depend_reference_index | i | 34 | 0
(7 rows)
//下面的query可以將每個table在shared_buffers裡面的block,依照usage count分布來統計數量
SELECT
c.relname, count(*) AS buffers,usagecount
FROM pg_class c
INNER JOIN pg_buffercache b
ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d
ON (b.reldatabase = d.oid AND d.datname = current_database())
GROUP BY c.relname,usagecount
ORDER BY c.relname,usagecount;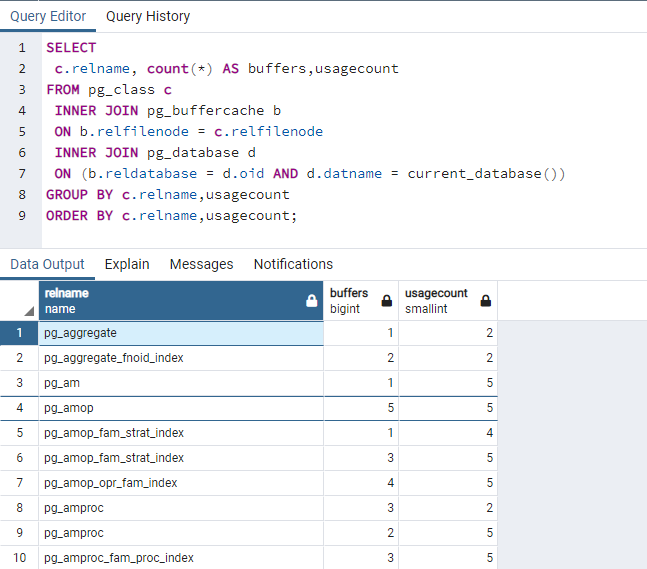
一般情況下Postgres的緩衝區在每次伺服器重開之後就會清空,之後資料再次從硬碟中讀取就需要稍作等待,透過pg_prewarm附加元件可以將特定table的資訊預先讀入shared_buffers裡面,可以加快訪問的速度。
//連線到資料庫之後,透過create extension指令來啟用pg_prewarm
CREATE EXTENSION pg_prewarm;
//設定將某個table自動讀入cache裡面
SELECT pg_prewarm('t_test');
//設定將某個table的特定範圍block讀入緩衝區
SELECT pg_prewarm('t_test', 'buffer', 'main', 10, 30);
//上面的指令設定pg_prewarn在資料庫啟動時讀取table t_test main fork的第10到30 block到緩衝區

