執行計劃是Postgres的系統決定執行該query的方式。由於SQL是宣告式的語言,說要取得什麼資料,而沒有指定要如何取得,所以執行一條query可以有很多種方式,像是filtering的套用時機以及資料掃瞄的方法等等。Postgres的優化器會透過一系列的內部規則,為多種可能的執行方法個別計算出一個成本(cost)的數值,並使用這些方法裡面總成本最低的。
在PostgreSQL query的前面加上EXPLAIN,可以輸出query的執行計畫。 對query執行EXPLAIN ANALYZE則會讓Postgres輸出執行計畫的同時真正執行該條query,並且在輸出中加上query實際執行的統計資訊。
EXPLAIN ANALYZE指令下了之後,會出現類似下面的資訊:
EXPLAIN ANALYZE SELECT * FROM tenk1 t1, tenk2 t2 WHERE t1.unique1 < 100 AND t1.unique2 = t2.unique2 ORDER BY t1.fivethous;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=717.34..717.59 rows=101 width=488) (actual time=7.761..7.774 rows=100 loops=1)
Sort Key: t1.fivethous
Sort Method: quicksort Memory: 77kB
-> Hash Join (cost=230.47..713.98 rows=101 width=488) (actual time=0.711..7.427 rows=100 loops=1)
Hash Cond: (t2.unique2 = t1.unique2)
-> Seq Scan on tenk2 t2 (cost=0.00..445.00 rows=10000 width=244) (actual time=0.007..2.583 rows=10000 loops=1)
-> Hash (cost=229.20..229.20 rows=101 width=244) (actual time=0.659..0.659 rows=100 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 28kB
-> Bitmap Heap Scan on tenk1 t1 (cost=5.07..229.20 rows=101 width=244) (actual time=0.080..0.526 rows=100 loops=1)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0) (actual time=0.049..0.049 rows=100 loops=1)
Index Cond: (unique1 < 100)
Planning time: 0.194 ms
Execution time: 8.008 ms
中間被稱作query plan的內容可以理解成是樹狀結構的一種,每個節點會從下層節點或是table來取得資料,然後回傳給上層的節點做使用,然後在最頂端取得查詢結果。
接在節點名稱右邊的括號表示Postgres預估/實際的query執行情況,其中預估的cost或者是實際執行的時間會有兩個數值,左邊的數值為startup cost/time,代表該節點取到第一行資料所花的時間/開銷,右邊的則是該節點執行完畢所需的時間/開銷,rows代表預估的/實際回傳的行數。ANALYZE被加入之後,右邊括號中的rows代表實際回傳的行數,loops代表該節點總共被執行的次數。
透過執行EXPLAIN指令,我們可以觀察query執行過程中的哪些步驟耗費掉大量時間或者是不合理,進而調整query或資料庫的設定來嘗試改善。
執行計畫中常見的節點除了有先前提過的sequential scan全表掃描以及index scan/bitmap index scan/index-only scan索引掃描之外,Postgres對於table join也有幾種不同的策略,像是nestloop/merge join以及hash join。
nestloop:巢狀迴圈,將左邊(outer)table的每一行和右邊(inner)table的每一行做對比,找到可以join的組合,正常情況下會在inner table足夠小,nestloop不會造成太大性能耗損的情況下被使用。
hash join會先將inner table做hash,然後將outer table的每一行透過hash funciton來檢查是否在inner table中存在。
merge join會先將兩邊的table使用join key進行排序,然後先從inner table的第一行和outer table的第一行做比較。如果可以做join就輸出,然後將inner table的掃描前進一行之後再次比較,否則將outer table的掃描前進一行之後再比較。這樣子的join方式之下,兩邊的table都只會被讀取過一次。
另外Postgres在某些情況下支援使用多個parallel worker多執行續來執行節點,像是parallel seq. scan,在由一個execution plan中所有可平行執行節點組成的子樹頂端會有一個Gather node來合併這些worker process的執行結果。
另外還有一些其他的,像是Sort node對應排序,Limit node對應到輸出結果筆數的限制(LIMIT),Append節點對應UNION ALL,GroupAggregate對應到GROUP BY等等......
在使用EXPLAIN的時候可以在EXPLAIN的後面加入一些選項,好比說EXPLAIN(ANALYZE, VERBOSE, COSTS, TIMING, BUFFER)
VERBOSE可以讓EXPLAIN指令輸出更進一步的資訊,像是每個節點會輸出的table欄位名稱
COSTS跟TIMING預設是打開的,就是輸出預估的cost以及執行時間的部分
BUFFER可以查看該query的每個節點執行時,有多少部分的緩衝區被讀取或寫入
如果覺得純文字的形式難以解讀,可以使用下列的網頁
https://explain.dalibo.com/
將explain的輸出結果貼入之後,可以用圖形化的介面查看內容,左邊欄可以快速將每個節點所占用的時間以及行數等資訊並列來做比較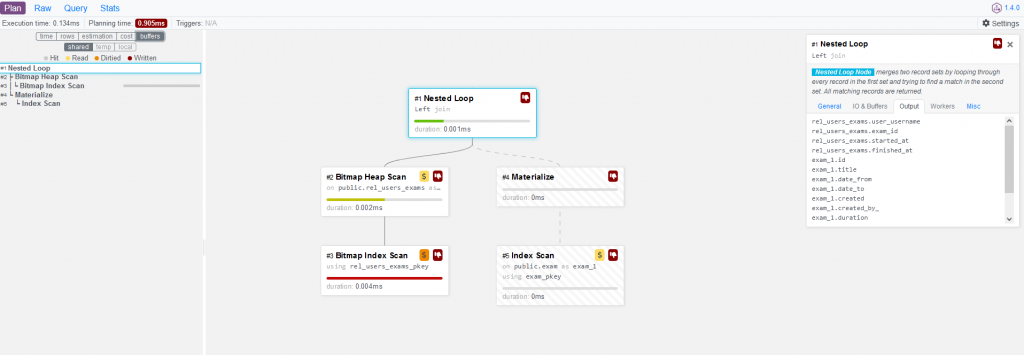
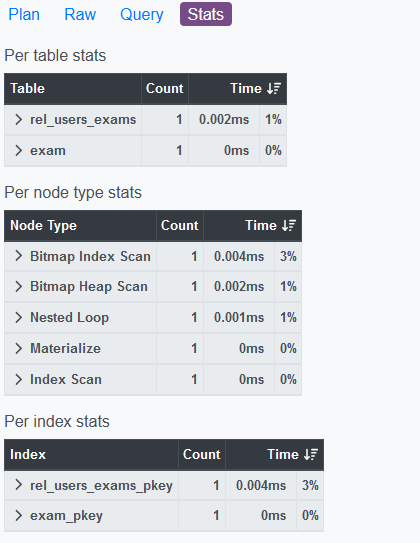
可以依照table/操作類型來統計各個query的部份在總執行時間中的占比