如果說 GET 請求是單純取得一個頁面,那麼 POST 請求就是送出一些資料,並且交給伺服器端處理。
最常見的情況大概就是登入了。試想一個 POST 請求,表單內容有你的帳號密碼,伺服器確認無誤後,就頒發 Cookies 給你。
如果你想要模擬 iT 邦幫忙的登入,那麼首先,你必須知道該登入表單是怎麼被送出去的 ?
值得高興的是,市面上的瀏覽器通常都有支援開發者工具,你可以用熱鍵 Ctrl + Shift + I 或 F12 按出來,然後檢查網頁的封包。
大家熟知的熱鍵應該是 F12。不過筆者使用的是 60% 鍵盤,沒有上排的 F1 ~ F12,所以習慣按 Ctrl + Shift + I。
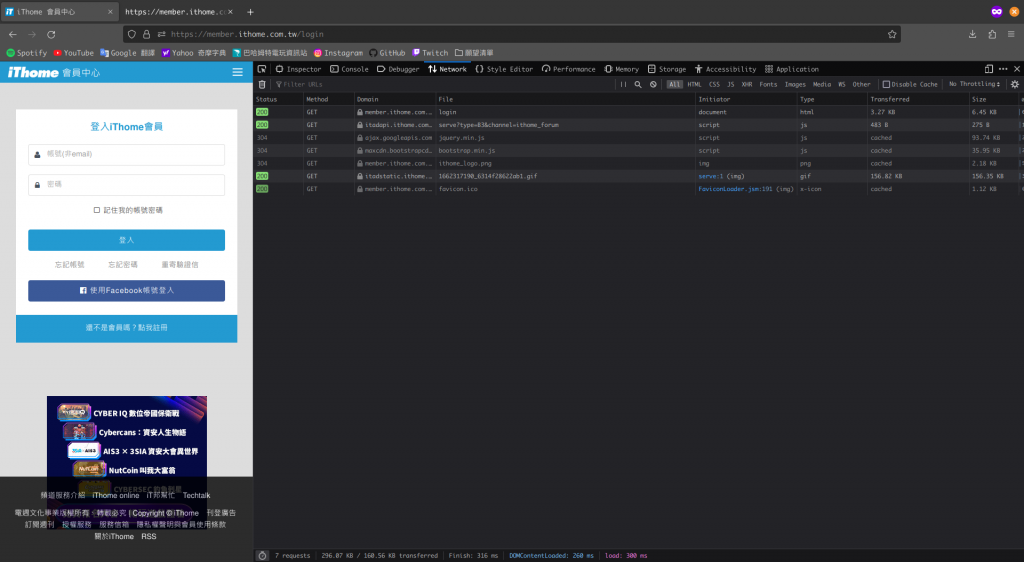
接著輸入帳號密碼,讓登入這個請求被送出去。
account 和 password 是我的真實帳號密碼,礙於隱私問題,我已經把它塗掉。
筆者使用的瀏覽器是 Firefox。根據瀏覽器的不同,你撈封包的畫面可能會和我不同。
也許你會疑惑,_token 裡面難道不是一個 key value 的資料結構嗎 ? key 是 0 和 1,value 都是 token ?
恩 ... 不是的,那是 Firefox 對陣列的表達方式。確實很容易令人誤會 !
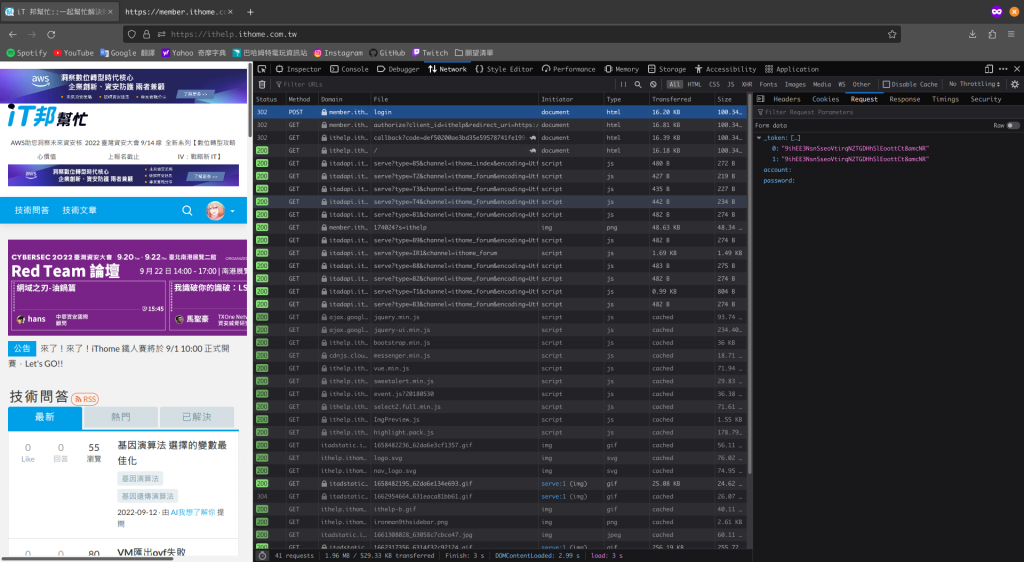
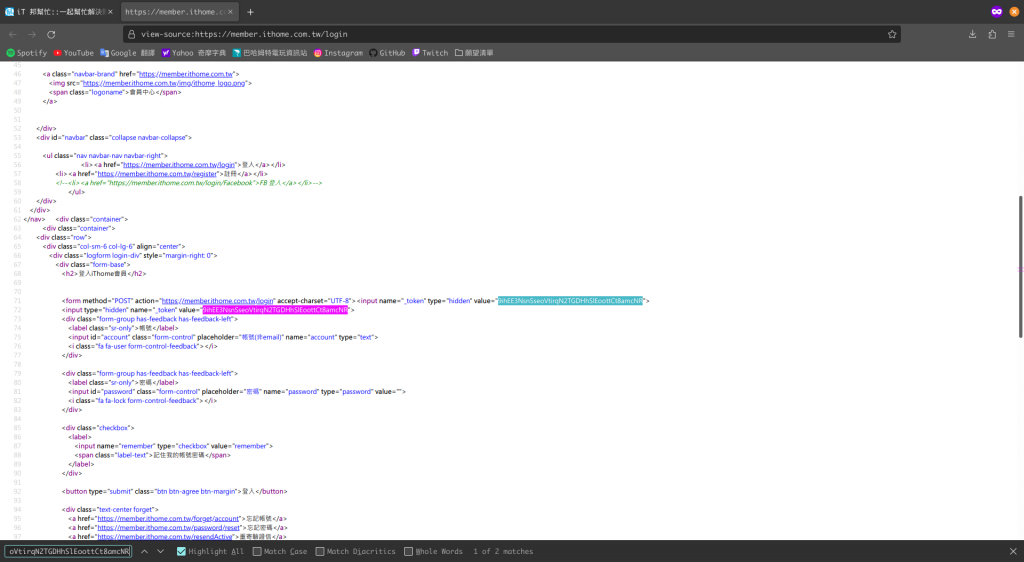
_token 是一個陣列,裡面的兩個值看起來都一樣,而且可以在登入頁面的網頁原始碼被搜尋到。
它其實是 CSRF Token。我將會在未來的文章提到,在此範例,我們只要知道,我們必須去滿足表單的內容即可。
實作會像是以下程式碼。
需要特別注意的是,一點進登入頁面的時候,其實就開始了一個 session,並且我們要使用這個頁面給定的 CSRF Token。
所以在第一個請求的時候,我們需要手動抓取 CSRF Token,並且把這份 cookies 保存起來,下次請求繼續使用。
如果你想試試看以下程式碼,account 和 password 記得要手動填入喔 !
import requests
from bs4 import BeautifulSoup
# Get login page
response = requests.get('https://member.ithome.com.tw/login')
soup = BeautifulSoup(response.text, 'html.parser')
# Get csrf token
token = soup.find('input').get('value')
# Get cookies
cookies = response.cookies
# Authentication
response = requests.post(
'https://member.ithome.com.tw/login',
data = {
'_token' : [token, token],
'account' : 'account',
'password' : 'password'
},
cookies = cookies
)
print(response.text)
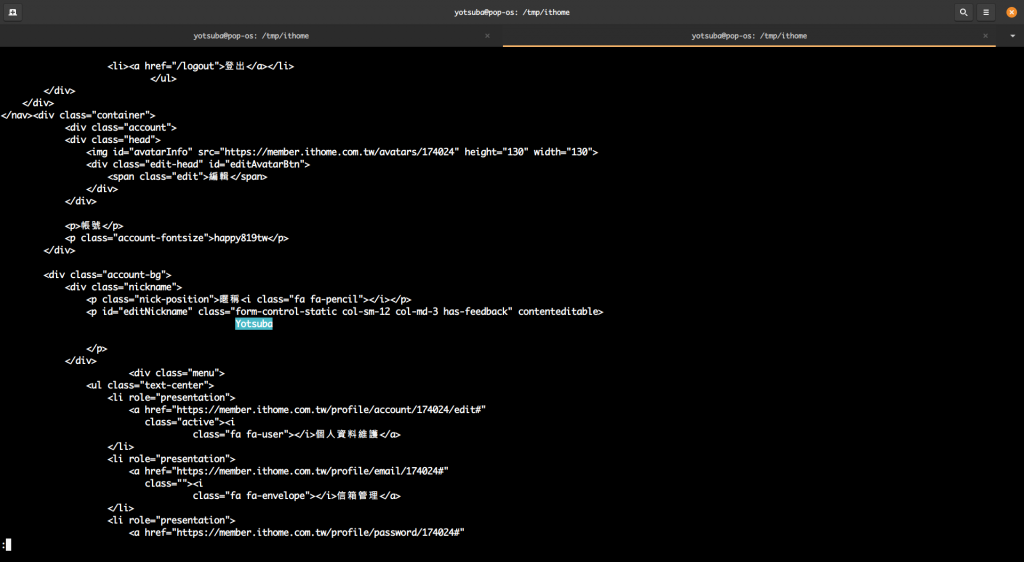
在執行後用 less 來看 output,可以搜尋到 Yotsuba 這個暱稱,證明我的登入是成功的。
Python requests 有一個非常強大的功能叫 Session,有如字面上的意思,它可以幫你搞定整個請求過程的 Session。
實際上 Session 在做的事情,主要是幫你紀錄並且保持住你請求後的 Headers。
試想一個情境 : 你想看到的最終頁面,前面還需要經過一個以上的頁面,並且都要保持住 Sesssion,你就必須一直手動保存 Cookies。
比方說購物車吧,你不斷選購商品的時候,還有你到最終付款頁面的時候,為什麼購物車可以持續保持你的狀態 ?
或者就像是剛剛簡單的登入情境就好了,因為輸入帳號密碼,準備登入的時候,還要帶上當前頁面的 CSRF Token,所以你需要處理這個「Session」。
讓我們來優化上一段程式碼,可以變成這樣。
利用 Session 物件會幫我們紀錄 Headers 的特性,我們就不用手動處理登入頁面的 Cookies,因為它下一次還會記得我們是誰 !
而且整份程式碼的可讀性也變高了,行為上會非常接近你使用瀏覽器的感覺,畢竟我們用瀏覽器的時候,瀏覽器就自帶紀錄 Cookies 的功能。
import requests
from bs4 import BeautifulSoup
# Create a session
session = requests.Session()
# Get login page
response = session.get('https://member.ithome.com.tw/login')
soup = BeautifulSoup(response.text, 'html.parser')
# Get csrf token
token = soup.find('input').get('value')
# Authentication
response = session.post(
'https://member.ithome.com.tw/login',
data = {
'_token' : [token, token],
'account' : 'account',
'password' : 'password'
},
)
print(response.text)

