今天便是前言的最後一篇了,
在進入到接下來的實作前,
我們要來討論一下整體搜尋引擎的架構,
以及我們用到了哪些的技術。
選擇合適的技術棧及架構設計,
不僅能提升開發的效率,
也能避免後續可能產生的一些問題。
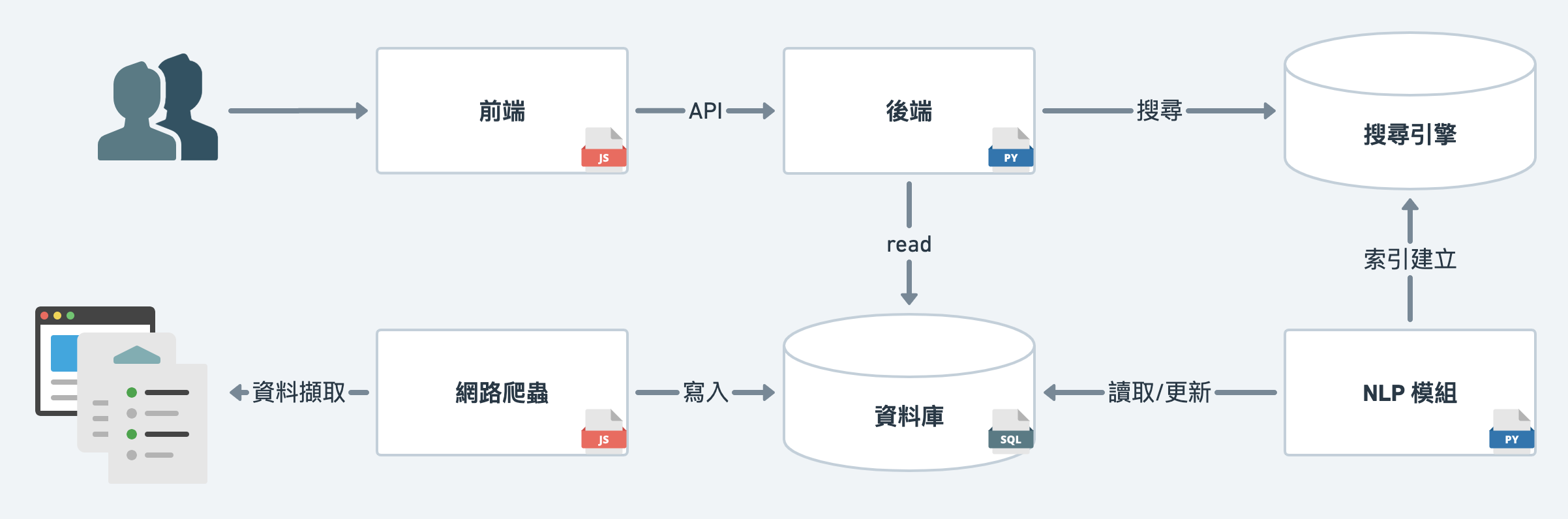
從上面一張簡單的架構圖中,我們可以從中間將整系統切為上下兩部份,
網路爬蟲 (web crawler)、資料庫、NLP模組、搜尋引擎等,來搜集與建構後台的資料庫。這次的鐵人賽在 day 01 也有提到過是與 Kirby 合作完成的,
我的專長在於NLP與搜尋引擎,後端與資料庫也有涉略,
唯獨對於前端部分是完全不會,而 Kirby 的專長也正是前端。
因此,在實作分工時,便由我負責NLP與搜尋引擎。
後端由於 API 都是與搜尋引擎功能緊密連結,所以也由我負責。
而 Kirby 則是負責前端的部分,與分擔網路爬蟲的實作。
一切都須從資料搜集開始,當我們確定搜尋引擎所要搜尋的資料目標後,
便需要開始搜集相關的資料。
javascript。Kirby 選擇用
javascript寫爬蟲的原因,
一來他比較喜歡javascriptXD
二來javascript爬蟲的文章相對python較少,
他也想藉此實作寫下一些文章。
選擇
supabase的原因除了 postgresql 外,
它在一定儲存量下也是免費的。
NLP也是其中不可或缺的一環。python,NLP及其他前處理後,選擇使用
python的原因,
也是因其有許多資料處理與機器學習的相關 packages,
相當的方便。
至於選擇
Meilisearch的原因,
則是它相對而言對於初學者更加的友善易上手。
取得並完成資料處理後,我們便可以開始建置我們應用程序的部分。
應用程序程序主要分為 Web 前端 跟 API 後端 兩個部分
Web 前端
負責與用戶互動,讓用戶能夠高效簡單的操作系統,
Kirby 採用 remix,一個新的 react ssr 框架。
API 後端
負責提供前端需要的資料、及相關服務,並保護敏感的資訊。
API 的部分也依據所提供的功能,
需要與搜尋引擎 Meilisearch 或是 supabase 連結溝通。
我使用 flask 架設了一個簡易的後端。
我原本是想用
golang寫後端的,
後來會選擇使用python也是為了避免過多不同的語言,
影響文章的可讀性。
同時過去也沒有用過flask,想嘗試看看。
最後,我們除了在本地端測試外,
也會將之部署到 fly.io 上。
fly.io 是一個相對於 aws 或 gcp 等更加簡單的平台,
只要將 docker image 準備好,就可以輕易部署完成。
同時,雖然有些許限制,但也是近乎免費。
非常適合用於產品週期前期的開發與測試。
明天我們將會進入到實作環節,並從資料處理部分的網路爬蟲開始。

