XPath是一種表達是語言,可以在XML文件中走訪和標示節點位置。它可以直接依據HYML標籤內容來搜尋網頁內容,也可以直接傳回符合HTML元素的內容與屬性值。目前BeautifulSoap不支援此查詢語言,進階網路爬蟲函式庫(ex. Selenuim、Scrapy)則有支援。
下方有兩種方式可以取得XPath表達式:
用XPath Helper工具取得XPath表達式字串
XPath Helper是Chrome瀏覽器的擴充功能,可以讓我們產生、編輯和測試XPath表達式來查詢網頁
(1) 進入Chrome線上應用程式商店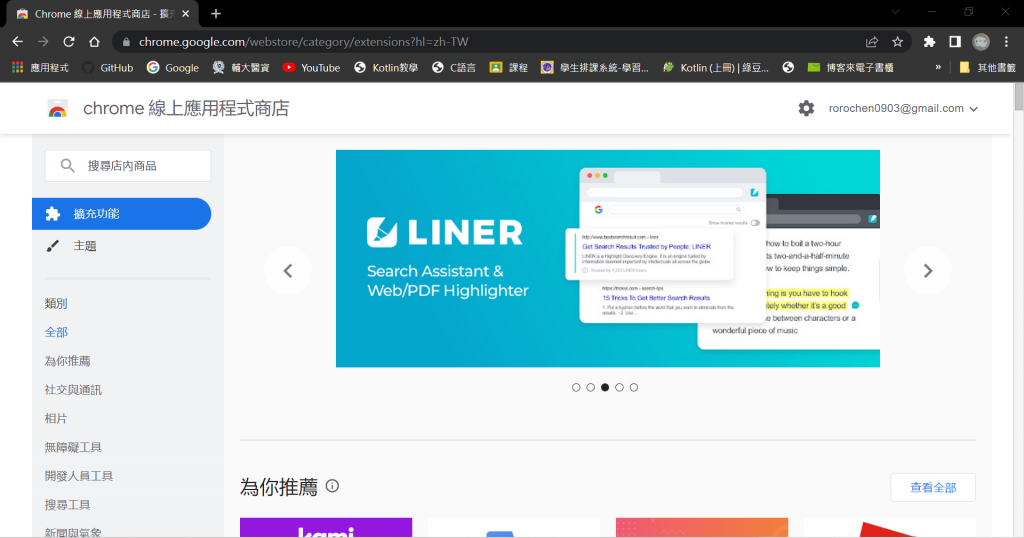
(2) 輸入”XPath Helper”搜尋商店,按下”加到Chrome”鈕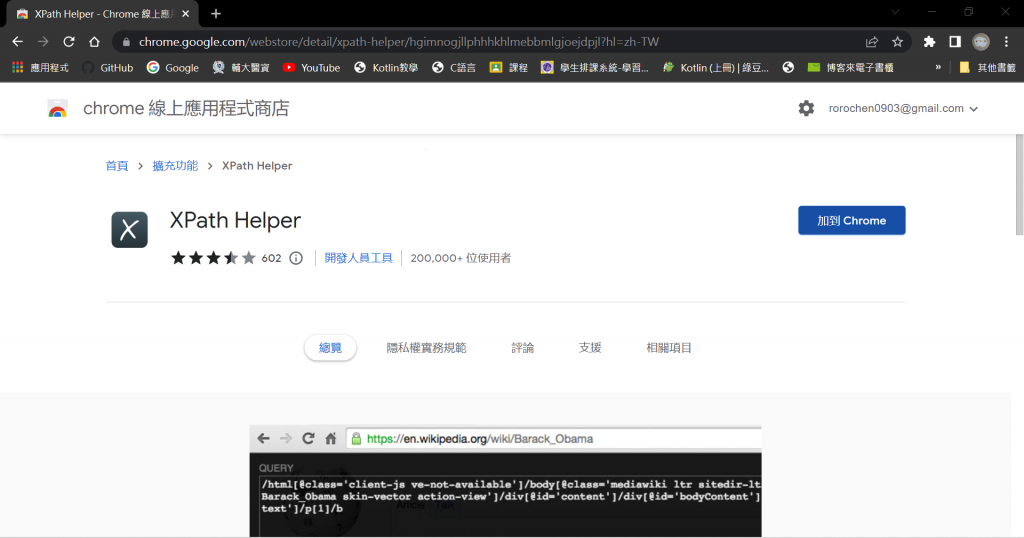
(3) 按下”新增擴充功能”鈕即可安裝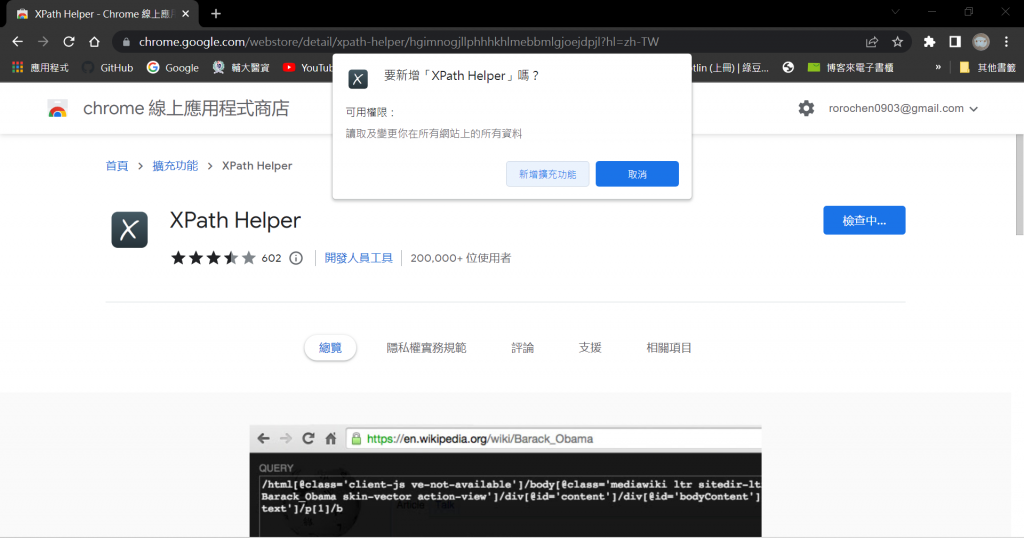
(4) 按住”Shift”鍵並移動游標來選取HTML元素
用Google Chrome開發人員工具取得XPath表達式字串
(1) 按F12開啟開發人員工具
(2) 選取HTML元素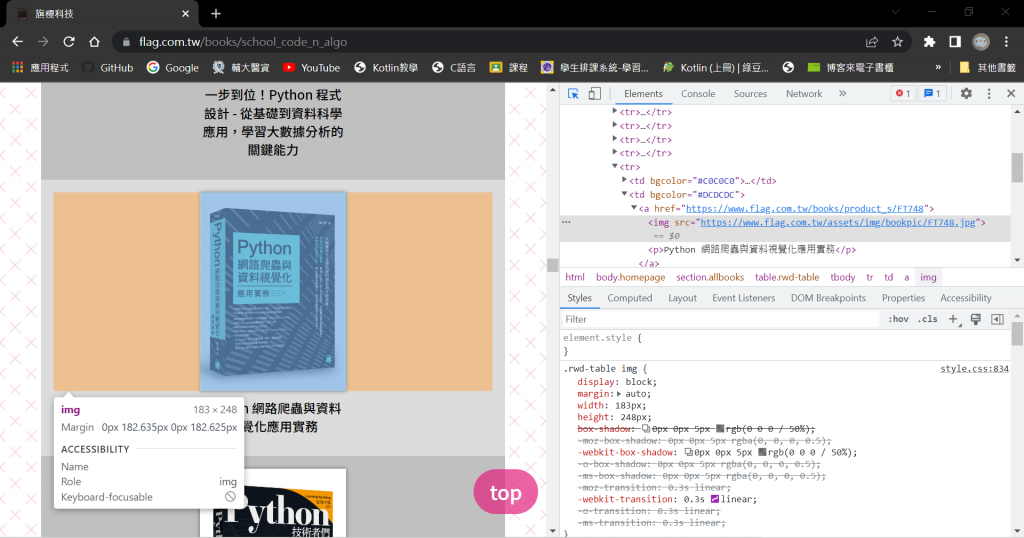
(3) 取得CSS選擇器字串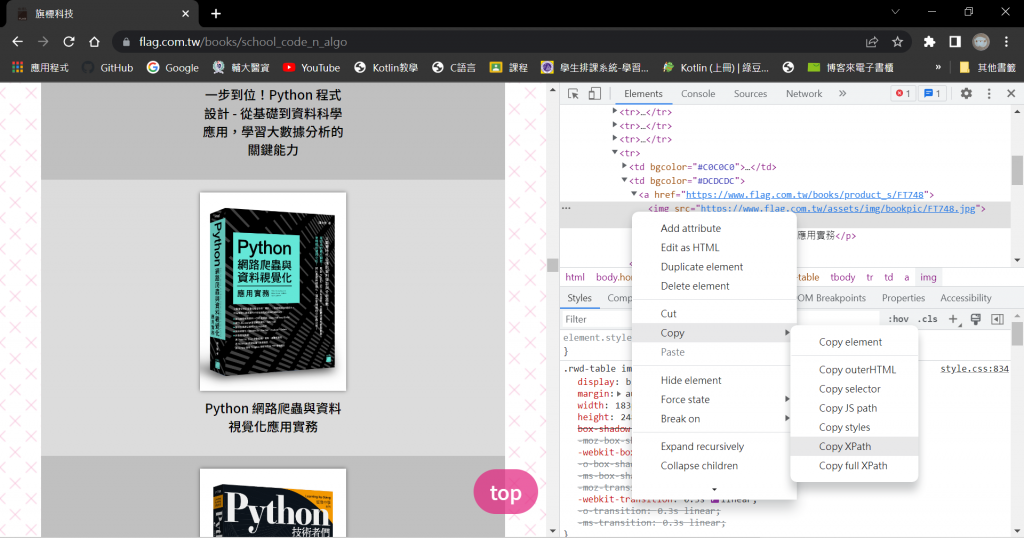
以旗標網站為例找出Python網路爬蟲與資料視覺化應用實務的書籍名稱與圖片。這裡使用Ixml套件來定位需要擷取的網頁元素。注意!!!Ixml在剖析table元素時並沒有tbody子元素,所以在XPath表達式要刪除tbody,不然執行程式時會發生錯誤
import requests
from lxml import html
r = requests.get("http://www.flag.com.tw/books/school_code_n_algo")
tree = html.fromstring(r.text)
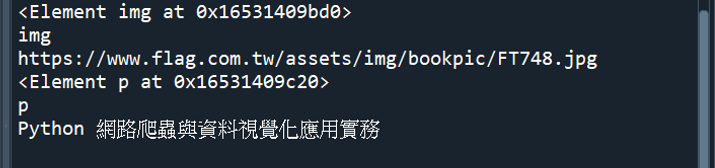
tag_img = tree.xpath("/html/body/section[2]/table/tr[8]/td[2]/a/img")[0]
print(tag_img)
print(tag_img.tag)
print(tag_img.attrib["src"])
tag_p = tree.xpath("/html/body/section[2]/table/tr[8]/td[2]/a/p")[0]
print(tag_p)
print(tag_p.tag)
print(tag_p.text_content())


 iThome鐵人賽
iThome鐵人賽