
前面三篇我麼講述了如何實作網路爬蟲,從網頁上擷取資料。
接下來我們要用一天的篇幅,
簡單介紹如何將爬蟲所擷取的初始資料存入資料庫,
以用後續的資料處理。
礙於篇幅緣故,過多細節的部分,會挑重點講述,如有疑問歡迎留言討論
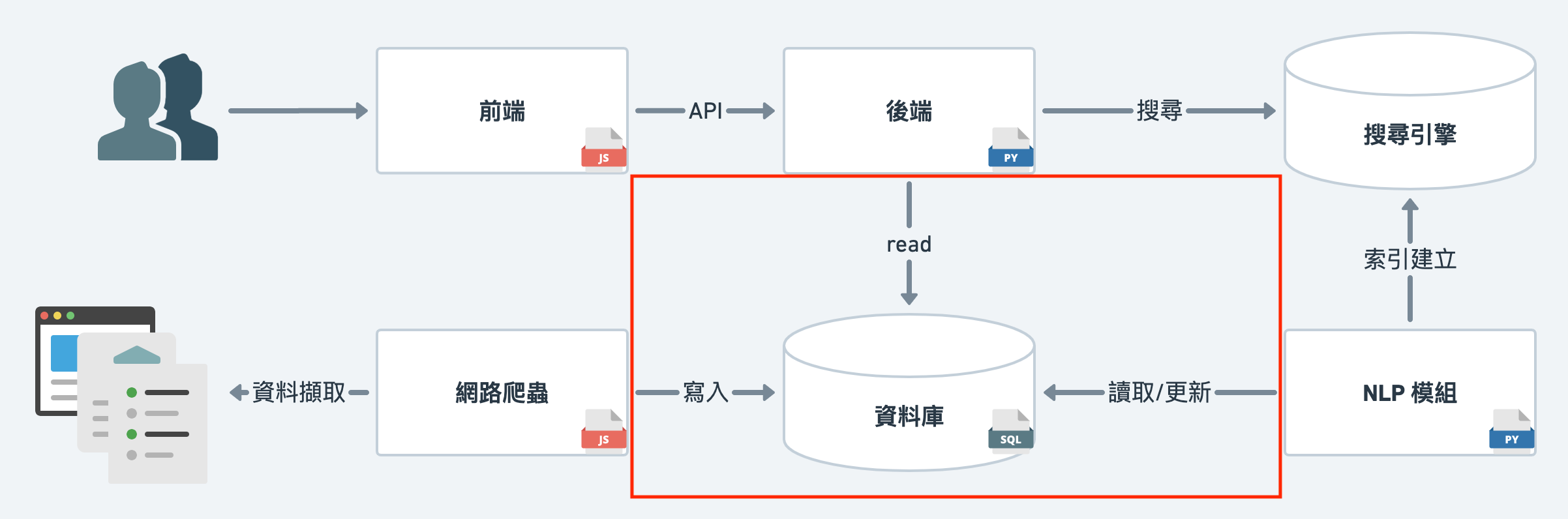
首先,我們要先介紹這次所使用的 serverless postgres,supabase。
serveless 資料庫幫我省去了自己架設資料庫的功夫,
我們只需要在 supabase 上創建帳號後,
開一個新的 project,便可以透過 API key 連接資料庫,開始使用。
Client 端,目前 suapbase 有支援 javascript 的函式庫 supabase-js,
與 python 的 alpha 版函式庫 supabase-py。
我們在爬蟲及後續資料處理、後端時,都有用到。
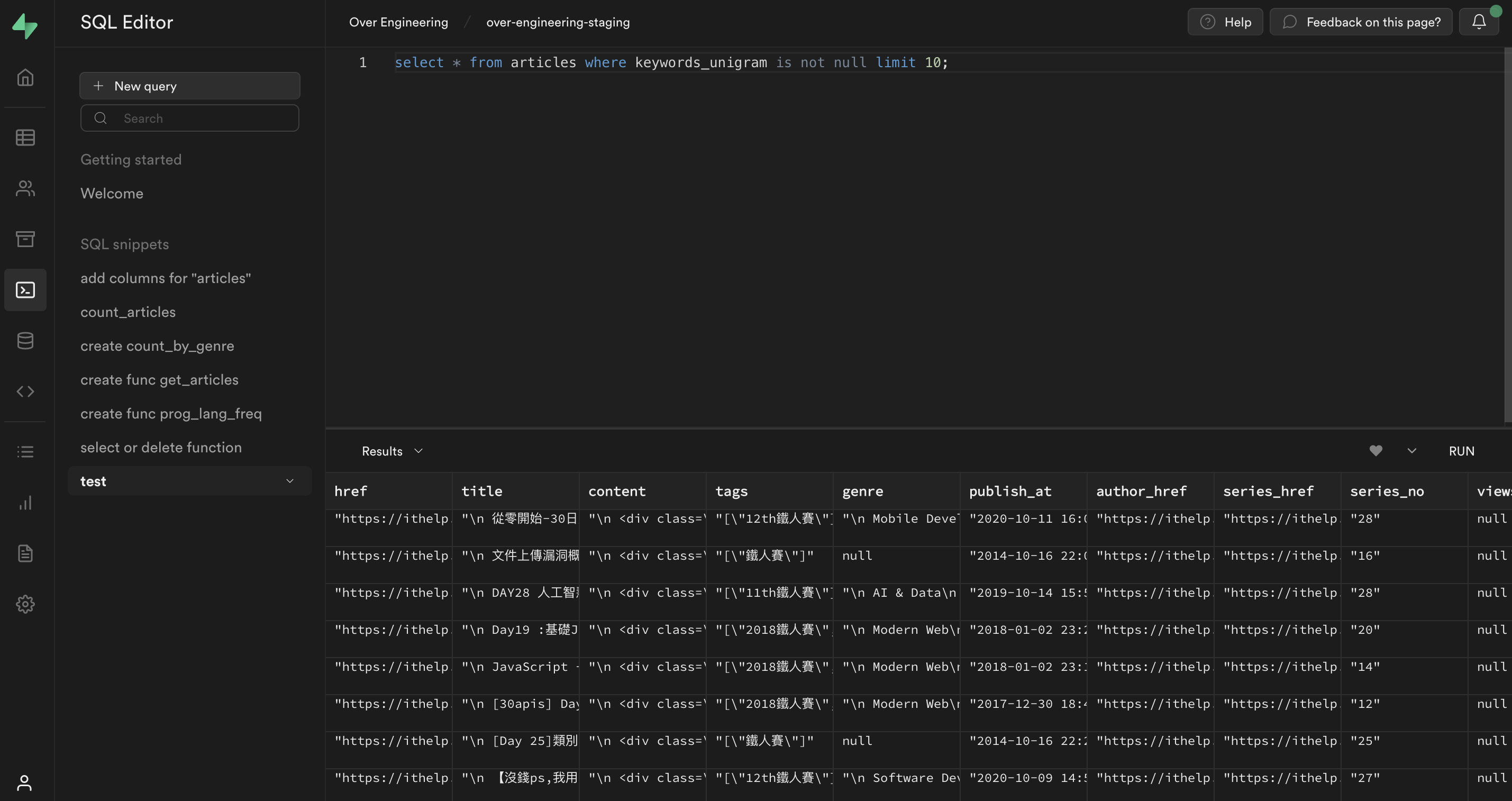
此外,supabase 網站上有提供 SQL Editor 及 Table Viewer,
透過 UI 介面下指令,建立新的資料庫或是瀏覽資料。
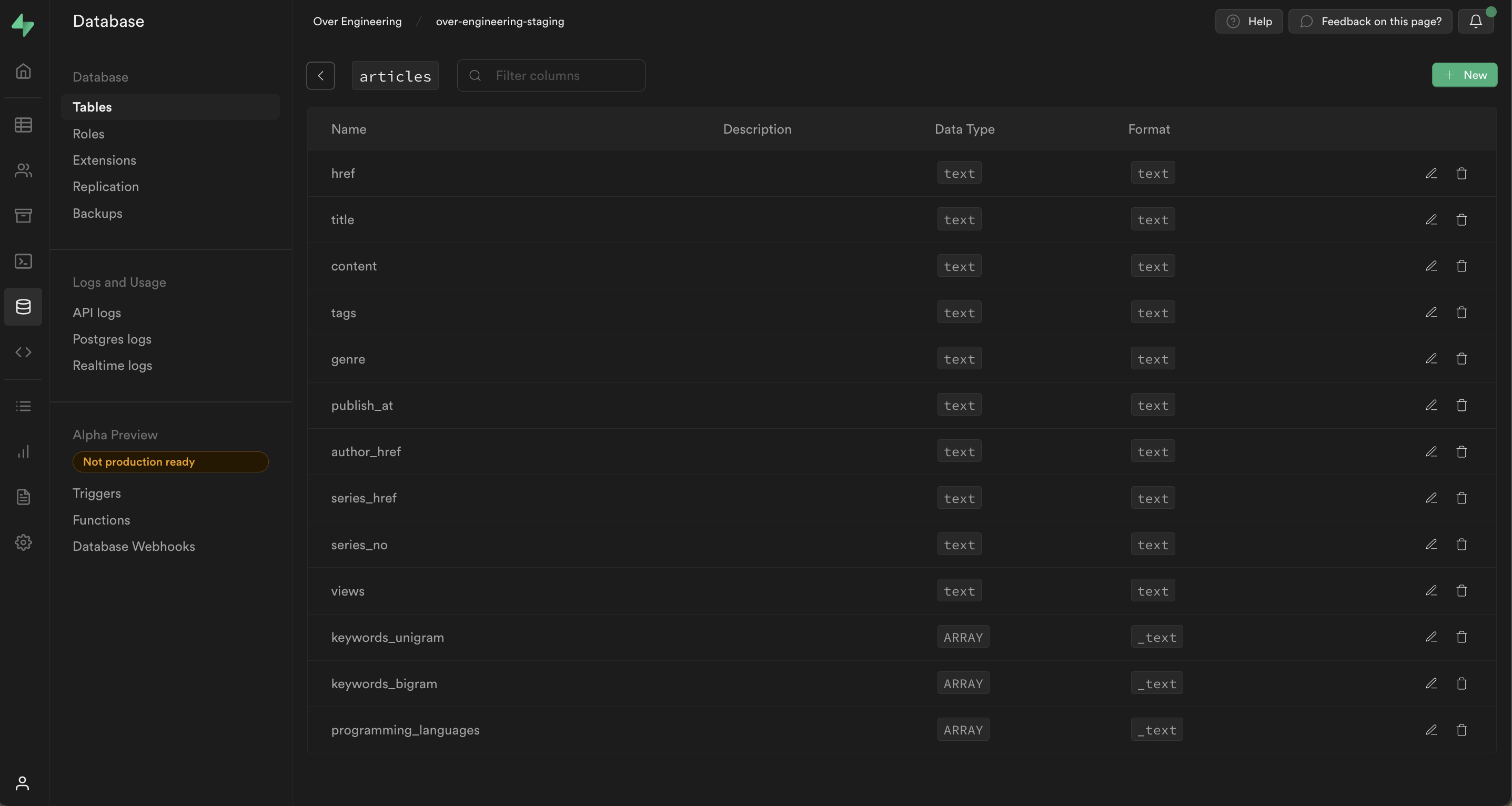
這次在建立 tables 時,
主要要考慮到存取對象的需求及會用到的 fields,
這次我們建立並使用的主要 table 是 articles,
下方有它的 fields。
此外,還會用到 stored procedure。
它類似於 SQL 資料庫端的 functions,
我們後續在實作後端 API 會比較詳細提到,
後端會使用 Supabase Client 函式庫,
透過 rpc 的方式去執行這些預存於 Supabase server 的 stored procedure。
(可以參考 supabase readme)
明天我們會開始進入資料處理與 NLP 的部分。
