資料表[Person].[Person]共有19972筆資料,
在我們的"AdventureWorks範例資料庫"佔有一定的資料量。
雖然執行起來的速度不慢,
但為了避免以後資料量增加影響到速度,
我想拿來做為增加INDEX的範例。
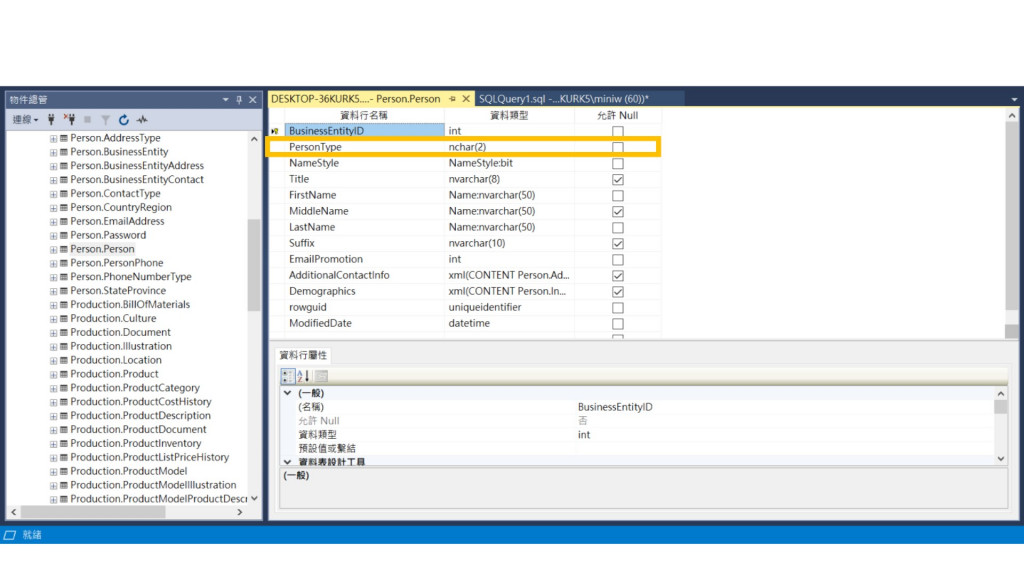
觀察資料表設計結構,
從表中可以發現有不錯的欄位適合做為INDEX:
就是PersonType欄位。原因是:
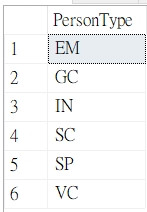
我先確認PersonType的資料內容,
發現有六種分類:
SELECT PersonType FROM [Person].[Person] GROUP BY PersonType
先建立一個名為index_PersonType的索引:
--CREATE INDEX 索引名 ON [表] (欄位)
CREATE INDEX index_PersonType ON [Person].[Person] (PersonType)
接著我們來使用看看兩者的查詢語法有何不同:
--未使用
SELECT *
FROM [Person].[Person]
--使用
SELECT *
FROM [Person].[Person]
WITH (INDEX(index_PersonType))
看一下執行計畫: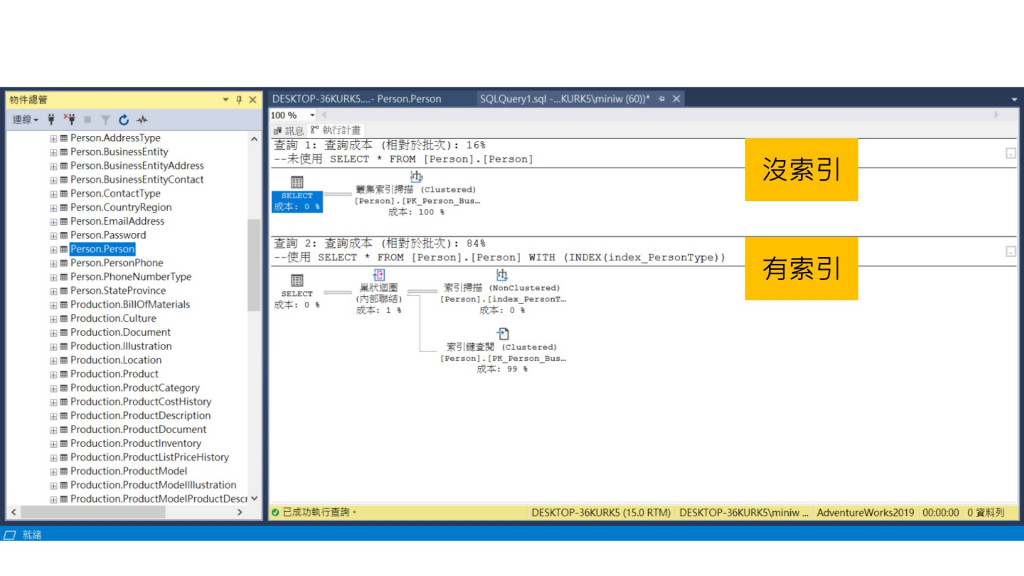
可以發現雖然結果相同,
但查詢的過程是很不一樣的。
雖然在這個例子裡,
效能並沒有如我們預期的有所提升,
(舉例選得不好,我檢討)
但我們更認識了執行計畫是有不同的路線,
也看見了效能的差異。
小提醒:
聽前輩說:過少的分類「不適合」作為INDEX。
原因是過少的分類(如性別):除男性、女性,即使增加第三性別,
假設資料有一千萬筆,使用性別INDEX後,資料量仍大。
因此很難有助益。
今天先這樣了,
我會好好檢討舉例的...

