了解Scrapy Shell的使用與測試擷取所需資料的操作後,實作練習以擷取批批踢股票看板的發文標題、推文數和作者資料為例,建立Scrapy的爬蟲專案。
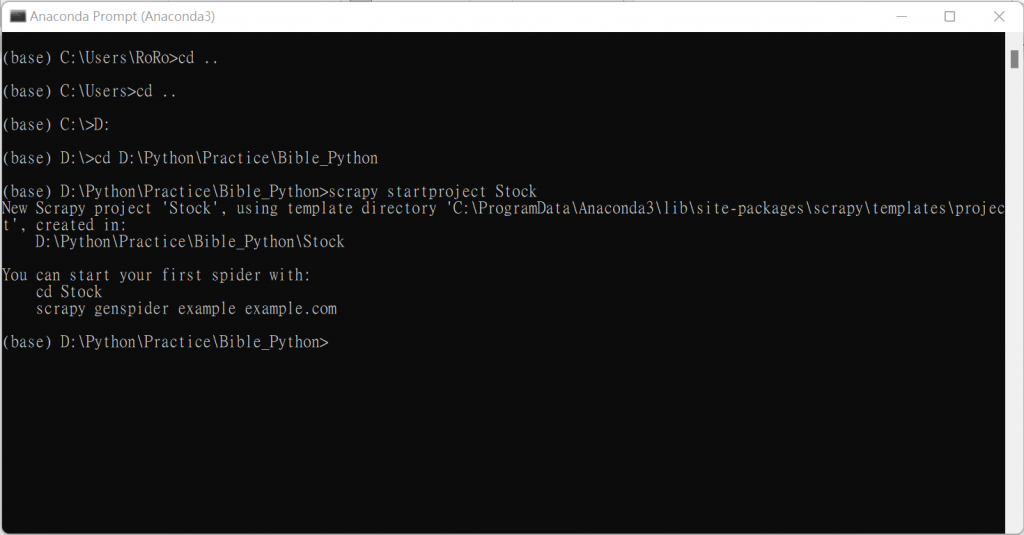
開啟Anacaonda Prompt命令提示字元,選擇建立專案的目錄
cd .. #返回上一層目錄
cd #到指定的目錄路徑

新增專案
scrapy startproject 專案名稱
使用cd指令切換到專案目錄,再使用下方指令新增Python爬蟲程式
scrapy genspider 檔案名稱 爬取網域

完成後可以看到Spyder內新增的爬蟲程式pttstock.py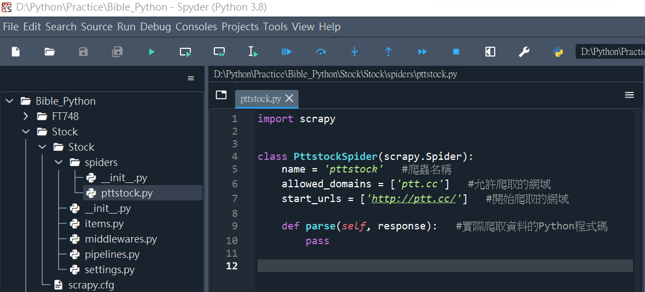
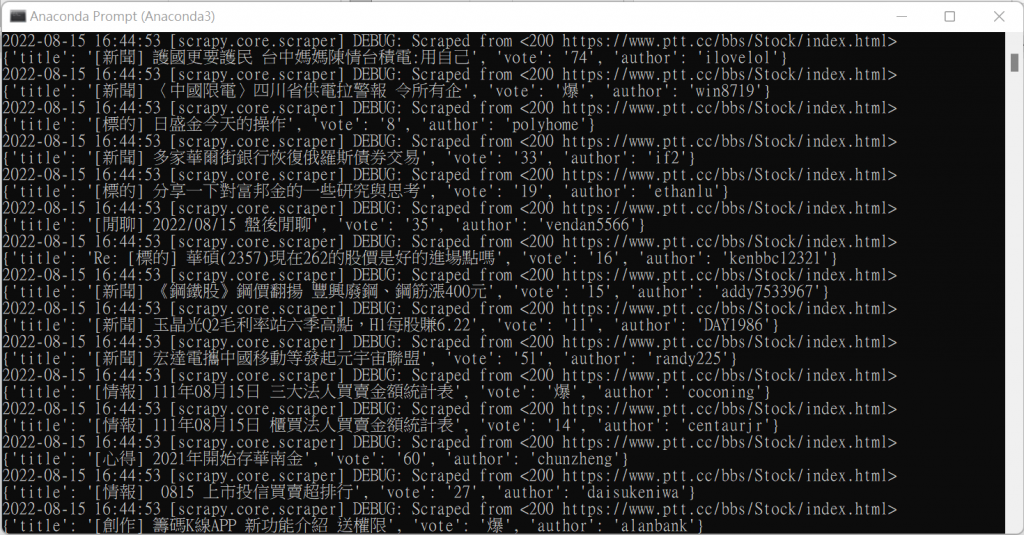
在parse()函數下定位與擷取所需的資料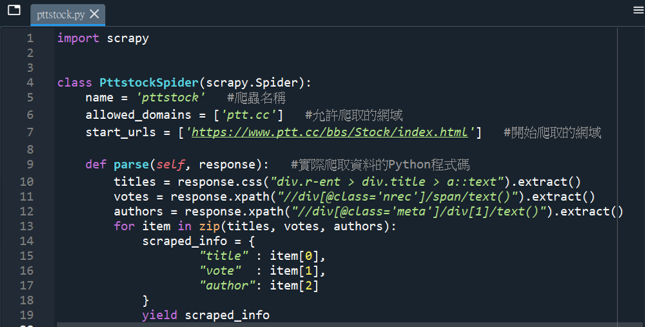
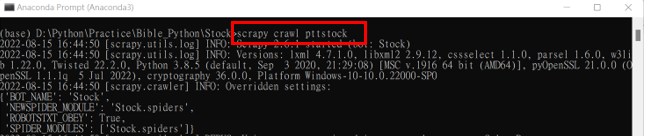
執行程式
scrapy scrawl 檔案名稱


 iThome鐵人賽
iThome鐵人賽