前言
K-means集群分析(中文:k-平均演算法),是屬於Clustering分類演算法的一種, 而Clustering類別的演算法幾乎都屬於非監督式學習(Unsupervised learning),K-means也是非監督式學習。
K-means介紹
用一句話來概括K-means的話就是:物以類聚(貓會跟貓組成一群,狗則會跟狗組成一群),但是貓跟狗的資料不會自己分類,那我們要怎麼分類他們呢?
所謂的k-means就是你想要將資料分成幾群(k代表的就是分成幾群; means則是每一個類別群的群心,且群心是動態會移動的)
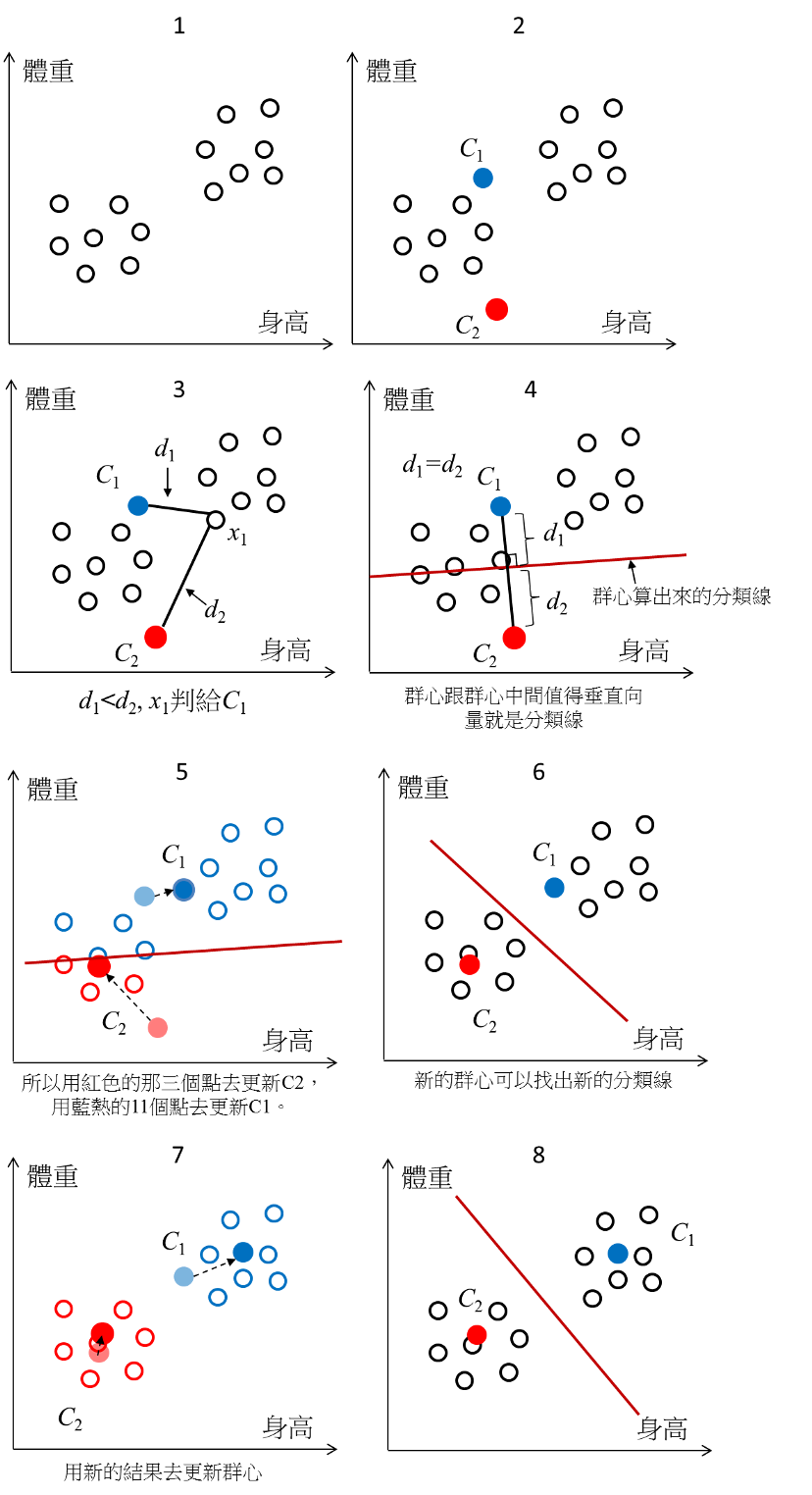
K-means運作步驟概念
假設今天要將好幾隻貓跟好幾隻狗分群
x, y坐標軸分別代表身高跟體重,如何將他們分類?
第一步:先設定好資料要分群成幾群(幾k)
第二步:在m維度中(維度不一定只有二維也可能是多維)給定k個集群群心
第三步:每個資料都會有所有k個群心去算跟歐式距離(直線距離公式)
也不一定要是直線距離公式有不同的公式可以使用,但基本上採用歐式距離第四步:將每筆data分類給距離他最近的群心
第五步:群心會根據移進來的新data做浮動(根據資料做動態更新)
第六步:第三步至第五步會一直持續做loop做到群心不再變動(收斂)的時候,K-means運作結束,且確立群心跟資料分類。
https://en.wikipedia.org/wiki/K-means_clustering


 iThome鐵人賽
iThome鐵人賽