由於樹狀結構並不像 Lined List 或陣列那樣是線狀的,故需要遍歷整個樹狀結構是很複雜的,而且有多種方式。
大致上分為以下兩種:
而 Depth-first Search 依照搜尋順序不同又分為:
此搜尋方式是每層每層遍歷,根節點遍歷之後換根節點的左右子節點,接著換左右子節點的左右子節點,接著遍歷下去直到沒有子節點。
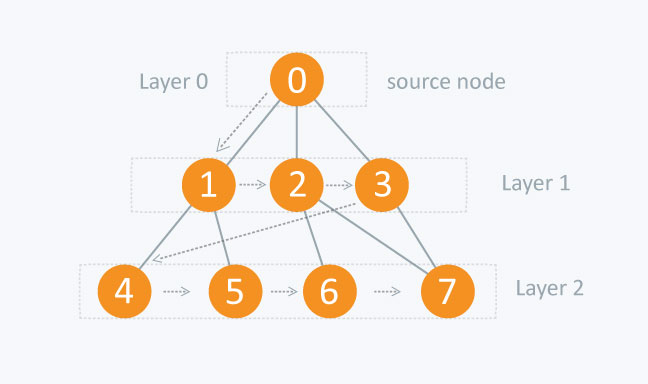
而實作上我們需要建立一個 Queue 與一個遍歷完存放節點的物件,這兩個都可以用陣列達成。
第一步先將根節點放入 Queue 中,接著開始遞迴查找當前 Queue 拿出來的節點底下是否有左右節點,有的話就放到 Queue 裡面等待查詢,
由於根節點 (當前節點) 已經查找過了,除了從 Queue 拿出來之外,也要放入遍歷完存放節點的陣列中,此陣列是最後遞迴結束時要回傳的最終結果。
再來一樣的步驟,從 Queue 拿出來節點當作當前節點,查找當前節點底下是否有左右節點,有的話就放到 Queue 裡面等待查詢,接著把當前節點放入遍歷完存放節點的陣列。
當 Queue 裡面都沒有節點時,迴圈結束,回傳結果。
以下圖樹狀資料為例:

queue: [10], result: []
queue: [6, 15], result: [], current: 10
queue: [6, 15], result: [10], current: 10
6 ,查找左右子節點,並放到 Queue 裡:queue: [15, 3, 8], result: [10], current: 6
queue: [15, 3, 8], result: [10, 6], current: 6
queue: [3, 8, 20], result: [10, 6], current: 15
queue: [3, 8, 20], result: [10, 6, 15], current: 15
queue: [8, 20], result: [10, 6, 15, 3], current: 3
queue: [20], result: [10, 6, 15, 3, 8], current: 8
queue: [], result: [10, 6, 15, 3, 8, 20], current: 20
breadthfirstSearch() {
const data = []
const queue = []
let node = this.root
queue.push(node)
while(queue.length) {
node = queue.shift()
data.push(node.value)
if (node.left) queue.push(node.left)
if (node.right) queue.push(node.right)
}
return data
}
此搜尋方法是從根節點開始往左遍歷下去,直到左邊沒有節點後換找右邊。
一樣以 Breadth First Search 的舉例來說:
data: [10]
data: [10, 6]
data: [10, 6, 3]
3 左下沒節點,換找右下,右下也沒節點:data: [10, 6, 3]
6 找右下節點:data: [10, 6, 3, 8]
8 左下沒節點,換找右下,右下也沒節點:data: [10, 6, 3, 8]
6 ,但 6 左右都找過了,回到 10 找右下:data: [10, 6, 3, 8, 15]
15 左下沒節點,右下有:data: [10, 6, 3, 8, 15, 20]
20 左下沒節點,換找右下,右下也沒節點,回到 15 , 15 左右都找過,回到 10 , 10 左右都找過了且是根節點,回傳結果data: [10, 6, 3, 8, 15, 20]
實作上會用到 Recursion 的技巧,並建立一個 Helper Function 傳入節點,將該節點新增到回傳結果的陣列中,並檢查該節點是否有左右節點,有的話再呼叫一次自己帶入左右節點遞迴執行下去。
depthFirstSearchPreOrder() {
const result = []
function preOrderTraverse(node) {
result.push(node.value)
if (node.left) preOrderTraverse(node.left)
if (node.right) preOrderTraverse(node.right)
}
preOrderTraverse(this.root)
return result
}
一樣是先往左下遍歷,但先不把節點加進回傳結果中,直到遍歷至沒有左子節點時,換往右邊遍歷下去,直到沒有右子節點時,才將該節點加進回傳結果中。
整體而已只需要改一下上面程式執行的順序即可。
跟上面一樣的舉例,其結果會是:[3, 8, 6, 20, 15, 10]
depthFirstSearchPostOrder() {
const result = []
function postOrderTraverse(node) {
if (node.left) postOrderTraverse(node.left)
if (node.right) postOrderTraverse(node.right)
result.push(node.value)
}
postOrderTraverse(this.root)
return result
}
一樣是先往左下遍歷,但先不把節點加進回傳結果中,直到遍歷至沒有左子節點時,將該節點加進回傳結果中,換往右邊遍歷下去,直到沒有右子節點時結束。
也只需要改一行即可。
跟上面一樣的舉例,其結果會是:[3, 6, 8, 10, 15, 20]
depthFirstSearchInOrder() {
const result = []
function inOrderTraverse(node) {
if (node.left) inOrderTraverse(node.left)
result.push(node.value)
if (node.right) inOrderTraverse(node.right)
}
inOrderTraverse(this.root)
return result
}
以時間複雜度來看,每種遍歷方法都只會查找該節點一次而已,所以都是 O(n) 。
先看以下兩個情況:
圖 1 :假設下圖這樣平均分佈的樹狀資料共有 10 層
圖 2 :假設下圖這樣偏集中一邊的樹狀資料共有 1024 層
假設上兩個情況的總節點數都一樣。
以 Breadth First Search 來看,圖 1 的情況執行到越多層,會有越多節點存放在 Queue 中等待查找,在空間複雜度表現會較差。圖 2 的話因為每層都只有零星幾個,在空間複雜度上表現較好。
而以 Depth First Search 來看,由於是遞迴執行,會看總共有幾層需要一直遞迴下去,影響 Call Stack 需要存幾個執行函式。 (在 Recursion 的章節有提到 JS 執行函式時會將函式丟到 Call Stack 內,若函式裡又呼叫函式,則又會丟到 Call Stack 內,一直下去,直到函式執行完才會從 Call Stack 內移除。)
由此可知圖 1 平均分佈了 10 層, Call Stack 頂多只會存到 10 個執行函式,空間複雜度表現較好。而圖 2 偏一邊集中導致有超多層,代表 Call Stack 也需要存更多執行函式,因此空間複雜度表現較差。
而 Depth First Search 中的 PreOder 、 PostOrder 、 InOrder ,則可以根據情況來決定要使用哪種。
InOrder 的輸出結果是照大小順序的,適合用在需要照大小排列的情況。 PreOder 看輸出結果是從根節點開始往左再往右,適合用來複製資料,建構另個一樣的樹狀資料。


