哈囉,大家好!
前幾天在研究.group方法時,雖然被Guide 搞得有點混亂,但令我最在意的是雖然無法直接下Todo.group(:completed),但卻能下Todo.group(:completed).count,雖然心裡默默覺得八成跟SQL aggregate 出來的結果形態有關,因為group(by) vs. count 剛好讓query 結果的形態對等了,所以才能作用;但後來其實有點小白,硬要去嘗試size和length可不可以
# 猜猜哪些可以作用、哪些不可以?
Todo.group(:completed).count
Todo.group(:completed).size
Todo.group(:completed).length
# 答案是length,你腦袋是不是出現了“duh?”的聲音呢?
所以今天就順勢來研究三者的差異啦!
count vs. size vs. length 三個方法的差異應該是每個小白都很好奇卻又疑惑的東東;讓我們先來看看各自的source code 冷靜一下:
count
Count the records.
是ActiveRecord::Associations::CollectionProxy < Relation、ActiveRecord::Calculations 的方法
def count(column_name = nil)
if block_given?
unless column_name.nil?
raise ArgumentError, "Column name argument is not supported when a block is passed."
end
super()
else
calculate(:count, column_name)
end
end
size
Returns the size of the collection. If the collection hasn't been loaded, it executes a SELECT
COUNT(*)query. Else it calls collection.size.If the collection has been already loaded size and length are equivalent. If not and you are going to need the records anyway length will take one less query. Otherwise size is more efficient.
是ActiveRecord::Associations::CollectionProxy < Relation 的方法
# File activerecord/lib/active_record/associations/collection_proxy.rb, line 780
def size
@association.size
end
length
Returns the size of the collection calling size on the target. If the collection has been already loaded, length and size are equivalent. If not and you are going to need the records anyway this method will take one less query. Otherwise size is more efficient.
是ActiveRecord::Associations::CollectionProxy < Relation 的方法
source code 在Github 上: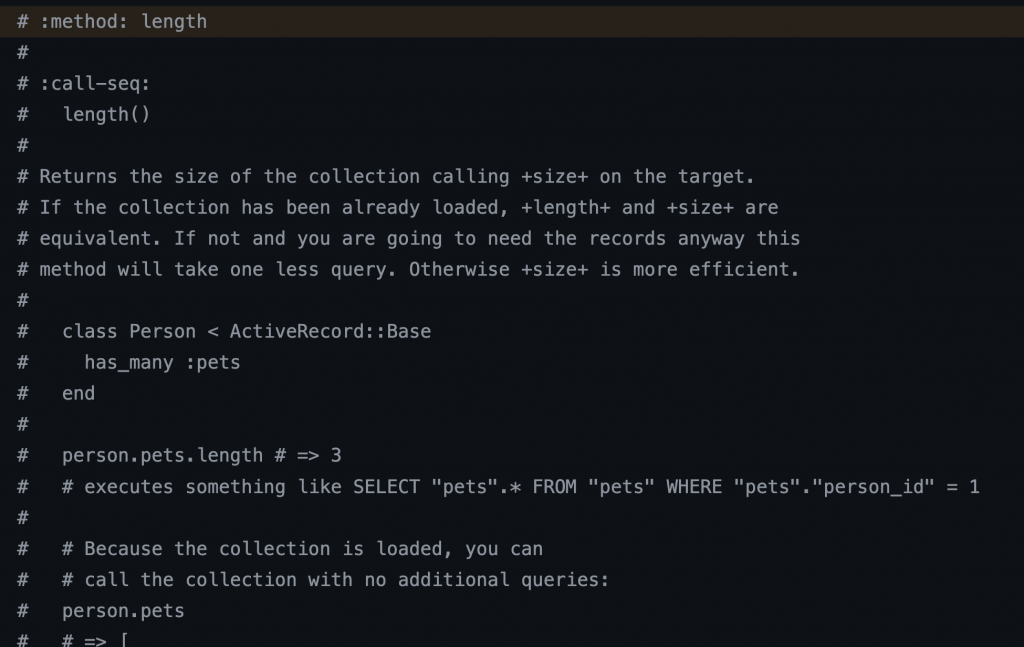
首先我們能看到三者使用的時機有差,除了count外,其他兩個要使用在relation、association、collection 等物件上,這也就能解釋為什麼我們直接執行Model.count/size/length會得到這樣的結果:
irb(main):036:0> Todo.length
Traceback (most recent call last):
1: from (irb):38
NoMethodError (undefined method `length` for #<Class:0x00007fd0bdc0d808>)
irb(main):037:0> Todo.size
Traceback (most recent call last):
1: from (irb):37
NoMethodError (undefined method `size` for #<Class:0x00007fd0bdc0d808>)
irb(main):039:0> Todo.count
(1.1ms) SELECT COUNT(*) FROM "todos"
200
那我們該怎麼做呢?
加個.all 讓他變成Relation 吧!(突然想起老師曾經說的,想不到要加什麼就加.all 吧 XD~~)
接著讓我們看看query 的statement 是否如documents 上的定義:
irb(main):041:0> Todo.all.length
Todo Load (3.9ms) SELECT "todos".* FROM "todos"
200
irb(main):042:0> Todo.all.size
(0.7ms) SELECT COUNT(*) FROM "todos"
200
irb(main):043:0> Todo.all.count
(0.7ms) SELECT COUNT(*) FROM "todos"
200
size和count的query 是一樣的,正如同documents 上的那句:If the collection hasn't been loaded, it executes a SELECT COUNT(*) query
接著我們先將物件做成association 試試:
irb(main):049:0> User.first.todos.length
User Load (0.5ms) SELECT "users".* FROM "users" ORDER BY "users"."id" ASC LIMIT $1 [["LIMIT", 1]]
Todo Load (0.4ms) SELECT "todos".* FROM "todos" WHERE "todos"."userId" = $1 [["userId", 1]]
20
irb(main):050:0> User.first.todos.size
User Load (0.4ms) SELECT "users".* FROM "users" ORDER BY "users"."id" ASC LIMIT $1 [["LIMIT", 1]]
(0.4ms) SELECT COUNT(*) FROM "todos" WHERE "todos"."userId" = $1 [["userId", 1]]
20
irb(main):051:0> User.first.todos.count
User Load (0.6ms) SELECT "users".* FROM "users" ORDER BY "users"."id" ASC LIMIT $1 [["LIMIT", 1]]
(0.7ms) SELECT COUNT(*) FROM "todos" WHERE "todos"."userId" = $1 [["userId", 1]]
20
這邊能看到length需要分別load 一次users、todos 才計算數量,但時間還是跟size差不多
那如果我們已經先將association load 起來呢?
irb(main):065:0> todos_of_user1 = User.first.todos
irb(main):066:0> todos_of_user1.length
20
irb(main):067:0> todos_of_user1.size
20
irb(main):068:0> todos_of_user1.count
(0.6ms) SELECT COUNT(*) FROM "todos" WHERE "todos"."userId" = $1 [["userId", 1]]
20
這就能看到差異了,在已經先load association 的狀態,length的確和size結果一樣,而count則是會紮實地query Db,我們可以這麼測試:
irb(main):071:0> todos = Todo.all
irb(main):071:0> Todo.create(userId: 1, title: "IThome", completed: "false")
(0.2ms) BEGIN
User Load (3.9ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]]
Todo Create (13.8ms) INSERT INTO "todos" ("userId", "title", "completed", "created_at", "updated_at") VALUES ($1, $2, $3, $4, $5) RETURNING "id" [["userId", 1], ["title", "IThome"], ["completed", false], ["created_at", "2022-10-08 14:54:38.475969"], ["updated_at", "2022-10-08 14:54:38.475969"]]
(3.8ms) COMMIT # 後略
irb(main):072:0> todos.size
200
irb(main):073:0> todos.length
200
irb(main):074:0> todos.count
(0.7ms) SELECT COUNT(*) FROM "todos"
201
只有count反映了Db 真實的筆數
借用一下前輩的圖片及整理迄今的結論:
length: calls and loads query into memory and calculate -> 較慢,但會存入memorycount: calls query every time and calculate; hits database every time -> 速度次之,但每次都會重新count database,能得到最準確的資訊size: load query and calculate -> 因不會重讀database 所以速度最快
翻譯蒟蒻:要用length 不如用size,要最準確的數量就用count,但效能稍微差一些,所以那麼length 被設計出來的用途是什麼呢?Hmm...
但被翻爛的書以後知道要選哪個方法計算數量了吧?(應該啦 XD)
那今天的研究就到這邊囉,謝謝大家~!
參考資料:

