
ItIron2022 Javascript我們昨天快速的認識了Puppeteer這個套件並用其做了一個簡單的實作,但實際上頁面截圖這樣的功能可能讓你沒有什麼感覺,今天我們就再深入一點了解Puppeteer,利用它替我們擷取頁面上我們想要的資訊吧!
Step1: 專案結構
你可以接續昨天的專案結構,我們需要的套件一樣只有Puppeteer一個,且需要一個app.js檔案去執行我們的腳本,最終你應該要有這樣的專案結構準備好。
目前為止你的專案結構應該會是這樣。
Step2: 在app.js檔案中引入puppeteer
首先先釐清一下我們今天的目標,我們今天試圖利用puppeteer擷取頁面上的資訊,為了方便說明我就用youtube的頁面來做示範吧!我們假設今天你因為某種原因想知道youtube在首頁的所有影片標題,並想將這些標題儲存起來另作他用。(是的,我平常都看這些亂七八糟的東西)

那麼首先我們就要釐清整個頁面的結構,因為不管後續你想對這些標題做什麼操作,第一步你都是要先告訴puppeteer哪些是你要擷取的資訊,這就會需要DOM的概念,就像我們之前在做任何js微型專案時,我們需要先選取要操作的元素。
既然這不是我們自己刻的頁面,要知道class或是id之類的資訊也就只能靠devtool囉!
請你打開你的devtool並選取影片標題的元素,你會看到它有個id叫做'video-title'

那麼我們要做的事情就簡單了,我們需要透過puppeteer完成以下的流程
其中1~3的步驟我們昨天都已經操作過了,今天我們只要做一個小小的變化讓它達成我們的需求即可! 請你將以下的程式碼寫入app.js檔案,我們先從取一個值的情況下開始。
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto("https://www.youtube.com/");
const content = await page.evaluate(() => {
const title = document.querySelector("#video-title");
return title.innerText
});
console.log(content);
})();
接著請你在你的終端機內輸入以下的指令
node app.js
下方一樣會開啟一個新的瀏覽器,打開分頁後並前往youtube頁面,同時請你查看你的終端機,會發現確實有抓到影片標題並印出。

今天我們用到的新API是page.evaluate,它可以傳入一個function,用來表示進入頁面後你想要做些什麼,在這次的示範中最終我們回傳了一個字串並將它存為content變數,由於document.querySelector會選取第一個符合條件的元素,因此僅出現一個結果完全在我們的意料之中! 理解原理後我們就可以修改一下以上的程式碼,讓它直接找出頁面中所有的影片標題囉! 請你將js的程式碼再次修改,變為以下的內容
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto("https://www.youtube.com/");
const content = await page.evaluate(() => {
const titleElements = document.querySelectorAll("#video-title");
const titles = [];
titleElements.forEach((titleElement) =>
titles.push(titleElement.innerText)
);
return titles;
});
console.log(content);
browser.close();
})();
接著請你再次在你的終端機內輸入以下的指令運行腳本
node app.js
由於我們加入了關閉瀏覽器的程式碼,最後你僅會看到最終在終端機的輸出結果,一切都運作的相當如預期!

我們今天利用了page.evaluate API擷取了畫面中元素的內容,這樣的你就已經懂得最最基本的爬蟲技巧了,爬蟲說穿了並不困難,核心的概念就是藉由自動化去取代一些傳統需要人工操作的一些行為,而一般在爬蟲指的行為就是資訊的獲取。 現階段你可能覺得這些技巧還稱不上多實用,但隨著文章的進行你會學到越來越多操作瀏覽器行為的指令,這些技巧最終整合起來就可以變為你自己自動化的工具,我當時是用來做一些E2E以及一些腳本的測試,在工作中幫了我不少忙! 這一系列文章雖然不會帶太深,但我相信足以成為不錯的入門磚讓你去發展自己的應用囉!
文章中的範例程式碼可以在這邊取得,歡迎自行取用
Danny,我做蠢事了,面試雖然還在進行中,但我已經口頭答應一間公司的offer,沒想到另一家我更想去的公司後來也發offer給我,我該怎麼辦?
我自己也不太敢相信這個問題我居然被問了兩次wwww,我必須不斷地強調台灣軟體圈子很小這一個事實,所以可以的話盡量不要把事情鬧得太難看,但這並不表示你就得乖乖去第一家公司。
坦白說,只要白紙黑字還沒有簽,一切就有週轉的餘地,若你真的很想去第二家公司,那麼我建議的策略永遠都是誠實為上,儘早、好好跟對方說明你的情況,不要猶豫不決耽誤彼此的時間才是上策!
本文章同步發布於個人部落格,有興趣的朋友也可以來逛逛~!
Danny你好
重作第二次,程式碼是貼網頁上的,輸出結果都是[],可以幫忙檢查嗎?!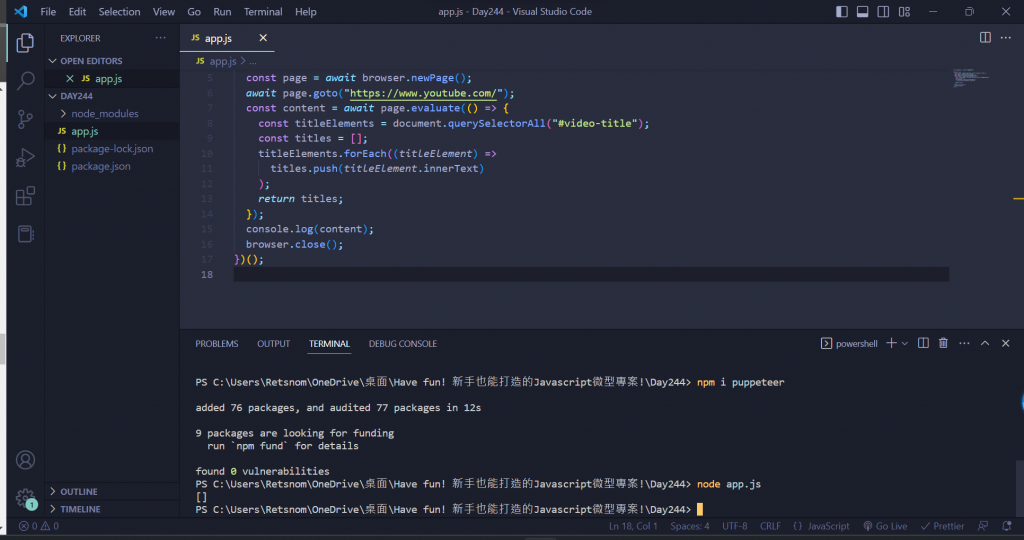
Hihi 112182ssss 我剛看了一下當時的程式碼,實際運行之後並沒有碰到什麼問題,也許是我有忽略了其他情況導致你無法得到相同的結果,可以試著先把瀏覽器關掉那行註解掉,然後一步步console.log出來之前的步驟,看是哪個部分出問題導致你得到一個空陣列囉!
會照著你提供的方法再嘗試找問題,感謝你快速地回覆。
