本文同步發表於小弟自架網站:微確幸資訊站
全字庫網址:
https://www.cns11643.gov.tw/
各單位通常都有難字造字檔,但個別造字檔在彼此交換資訊時就產生許多問題。
台灣有訂出字庫標準CNS,也就是上面的全字庫,今年也開始由數位發展部主責管理。
各單位遇到最多的狀況應該是姓名的造字,身分證的姓名主管單位是戶政機關,
期待未來戶政可以從源頭把關,所有的造字都以全字庫為統一標準,未來各單位也可以逐漸改成全字庫,
避免各自為政的造字資訊混亂。
以下進入主題:
目標資料在電腦中的顯示如下: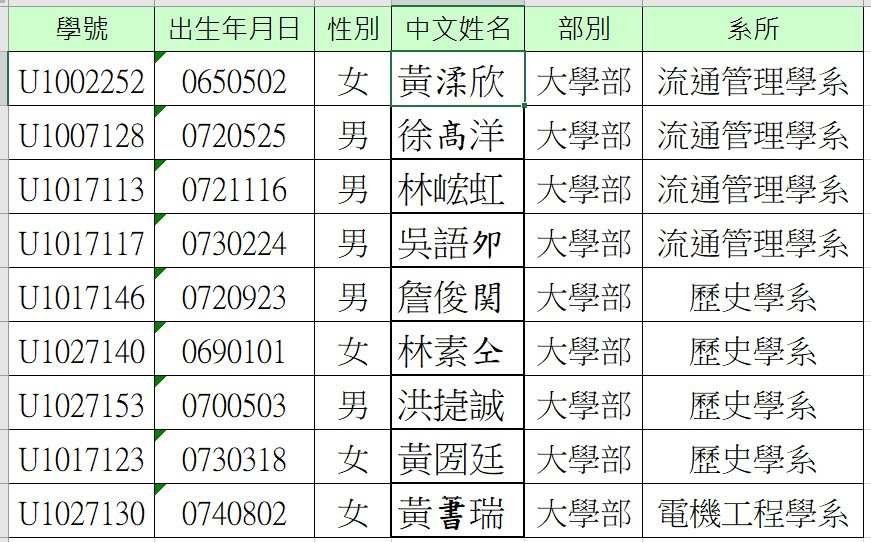
接下來以程式來讀取目標資料:
import pandas as pd
Location1 = '0000_學生資料_造字範例檔.xlsx'
df1 = pd.read_excel(Location1, sheet_name='資料檔')
df1
讀出來的造字會顯示為亂碼: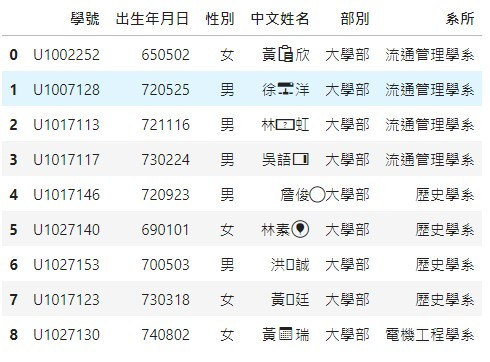
讀取自己的造字和全字庫造字的對照檔:
df2 = pd.read_excel(Location1, sheet_name='造字對照檔')
df2
程式讀進去後,顯示的狀況: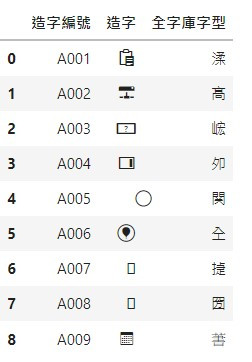
再來把自己的造字和全字庫的字型做成dictionary:
replace_dict = dict(zip(df2['造字'], df2['全字庫字型']))
replace_dict
自己的造字是亂碼(變成unicode編碼),但全字庫是看的到的:
先複製一個df,然後新建一欄「全字庫姓名」將自己的造字以上面的dictionary取代:
df = df1.copy()
df['全字庫姓名'] = df.中文姓名.replace(replace_dict, regex=True)
df
最後結果: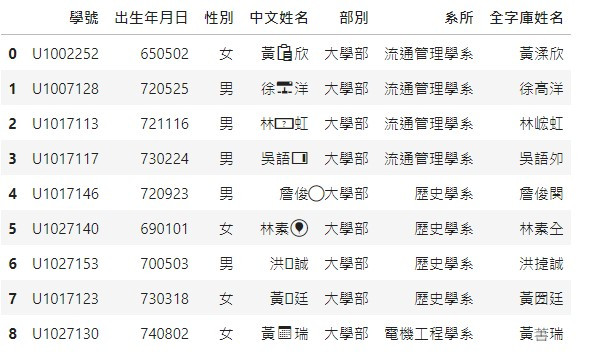
 mackuo
mackuo
