情資資訊很多,假設每天只花十分鐘,固定看一個高可信整理過的網站是一種方法,另一種方法用程式協助收集資訊。
學寫程式需要一些時間,來試試看ChatGPT是否能幫我們的忙
1. 用開發人員工具,用檢查到我們想要收集資訊的地方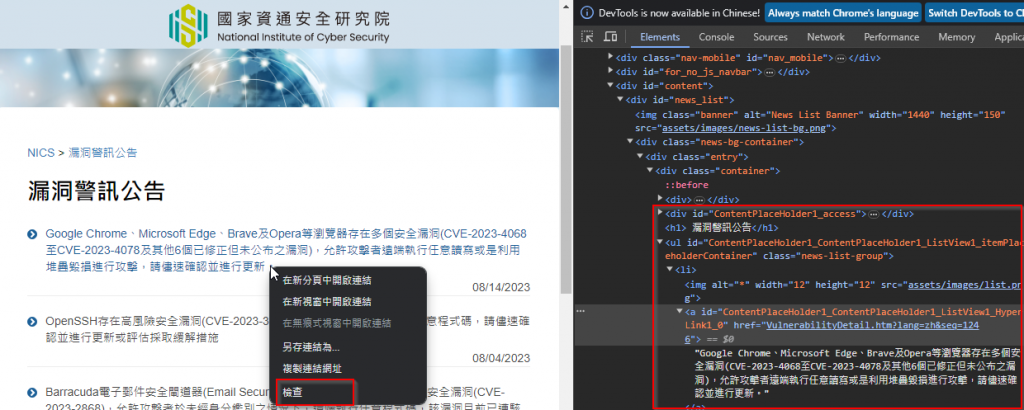
2. 詢問ChatGPT
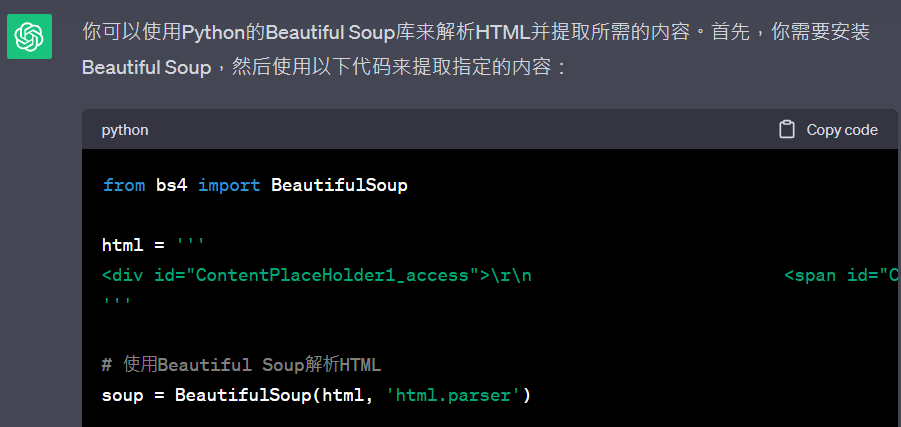
3. 請ChatGPT幫我們寫出完整程式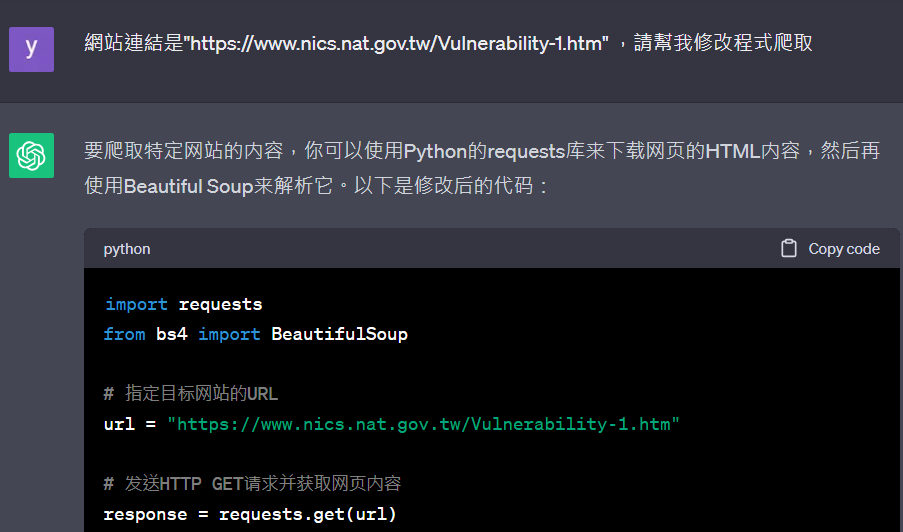
import requests
from bs4 import BeautifulSoup
# 指定目標網站的URL
url = "為了避免被爬蟲,請自行參考上面圖片網址輸入"
# 發送HTTP GET請求並獲取網頁內容
response = requests.get(url)
# 檢查狀態碼,確保請求成功
if response.status_code == 200:
# 解析HTML內容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取目標內容
div_content = soup.find('div', id='ContentPlaceHolder1_access')
h1_content = soup.find('h1').text
ul_content = soup.find('ul', class_='news-list-group')
li_items = ul_content.find_all('li')
# 印出提取的內容
print(div_content.text.strip())
print(h1_content.strip())
for li in li_items:
img_src = li.find('img')['src']
link_text = li.find('a').text
date = li.find('span', class_='date').text
print(f"標題: {link_text}")
print(f"日期: {date}")
print("\n")
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
4. 透過Google幫我們跑爬蟲程式
https://colab.research.google.com/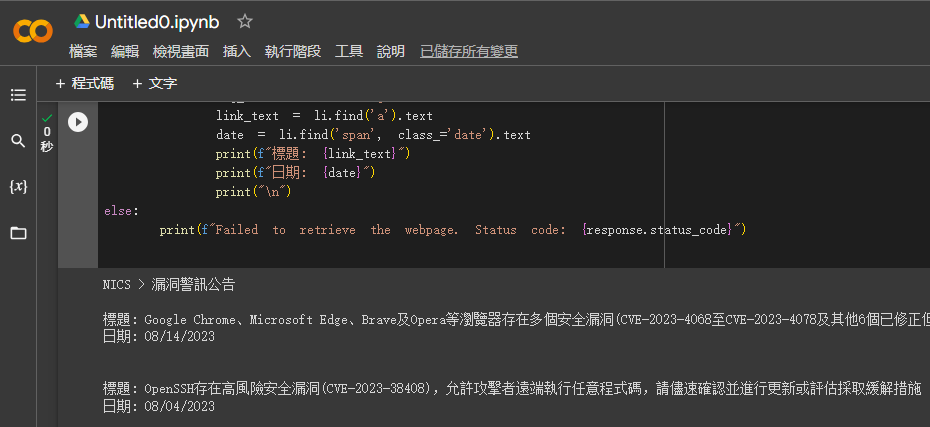
適當善用工具是進步的方式,雖然ChatGPT能減少我們儲備的知識,但還是要會操作相關工具的基本知識,就像是能把點過的技能+3的道具,身為資訊人員應該要先行去活用。

