前面的幾天主要都是介紹 Lex,我們使用它來生成詞法分析器。從本日起,我們要開始探討 Yacc的部分了。與 Lex 識別Regular Expression的情況不同,Yacc 則是識別整個文本的語法。Lex將Input劃分為token,然後Yacc將這些片段以邏輯方式組合在一起。因此,Yacc必須搭配Lex才能運作。
Yacc 的運作方式主要分成兩大步驟:語法樹建立與程式規則執行。前者是根據開發者提供的語法規則來分析輸入的文本,將其轉換為語法樹或抽象語法樹的結構,這有助於理解和處理語言中的複雜語法結構。後者是程式執行某語法規則所對應的操作,這部分由C++程式語言撰寫。
以下我們將一步步解釋這個流程。
我們先前提到,lex可以把複雜的訊息分類並標記token。這些token在Yacc可以用來建立程式規則。
舉例來說,我們若要計算1+2是多少,首先必須先定義下列事項:
這兩個問題很簡單,但是要讓程式知道,則必須做下面兩件事:
以上的”標記”動作是由lex完成,經由編譯與整合,讓yacc端知道這些標記符號的意義是甚麼。
在標記動作完成後,我們便要根據Yacc的語法規則,定義甚麼情況下要進行操作。
以剛剛的例子來說,加法規則的定義如下
數值 加法符號 數值 -> 將兩數值相加
也就是說,當讀取到三個相鄰字串的token分別為”數值” “加法符號” “數值”,此時便匹配到加法規則。
以此類推,當所有字串匹配相對應的規則後,便會形成語法樹,說明符合操作的字串序列,並列出操作的先後順序。
我們用四則運算來說明整體流程。
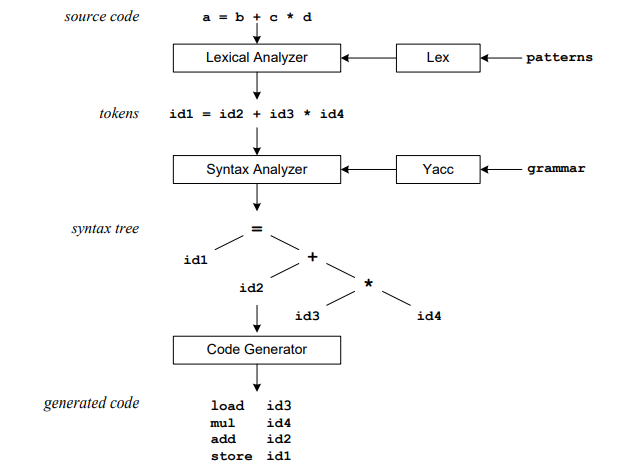
上圖中,輸入的文字是一條算式,由變數、等號、運算符號(加法與乘法)組成。Lex會先將不同類別的字串分類,並為其加上token。如上圖例子中,a, b, c, d四個變數被標記成”id”,運算符號與等號則自成一個token。
接著,Yacc會透過規則的建立,將標記好的標籤依規則做後續處理。上圖例子中,需要建立的規則如下:
規則建立之後,當遇到特定的條件後,就會觸發相對應的規則,並執行該規則下的後續動作。
接著,我們來看看Lex & Yacc是如何與C++結合,編譯出一個執行檔的:
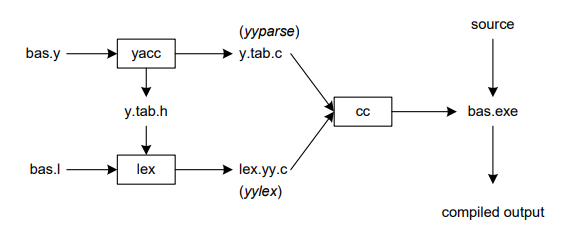
上圖說明了Lex和Yacc形成語法剖析器的過程。Lex的程式主要寫在.l檔中,內有自訂義的標籤及其名稱。Yacc的程式主要寫在.y檔中,內有自訂義的規則及相對應的處理函式。接著,我們透過以下幾個步驟生成一個語法剖析器。
yacc -d bas.y
lex bas.l
g++ lex.yy.c y.tab.c -o bas.exe
看到這裡,有沒有發現,yacc的編譯是放在lex編譯之前?這是因為token的宣告是在.y檔內,所以在yacc編譯過程中會產生一個y.tab.h檔。接著,Lex會讀取.l檔裡的pattern敘述式及y.tab.h內的宣告,產生一個詞法分析器(lexical analyzer),並寫在lex.yy.c內。另外,Yacc會讀取.y檔內的語法規則並產生一個語法分析器,並寫在y.tab.c中。最後一步則是透過編譯把兩者連結在一起,產生一個執行檔。
今天介紹的Yacc需要搭配Lex才能運作,因此結構比較複雜。
我們明天會來談談Yacc的語法規則是怎麼建立的。這部分會用到BNF表示式。


 iThome鐵人賽
iThome鐵人賽