研究的目的就是要產出一個模型?這其實是一個有點危險的起手式,回故我們一開始提到的 AI Canvas 和 ML Canvas 兩個架構,我認為這兩個架構的其中一個重點就是:一個好的起手式不是去寫任何程式碼,而是去弄清楚這個專案:
用我們 Account Takeover Detection (ATO) 問題來回答這幾個問題
這裡一個問題如果 Rule 哪摸厲害為什麼還需要做模型?其實真的不用,在這場景下我們對模型有兩層期待
但要記得模型先天有一個限制,不可能會完全沒有 False Positive,所以如果場景對於 False Positive 的接受度很低的話,就無法做到一個完全 End-to-End 的模型 Solution
那我們假設已經把基礎的 Rule 都做好,此時若想繼續去窮舉更多的規則是非常耗時且不切實際的,所以接著回到我們的題目,如何開始模型的研究
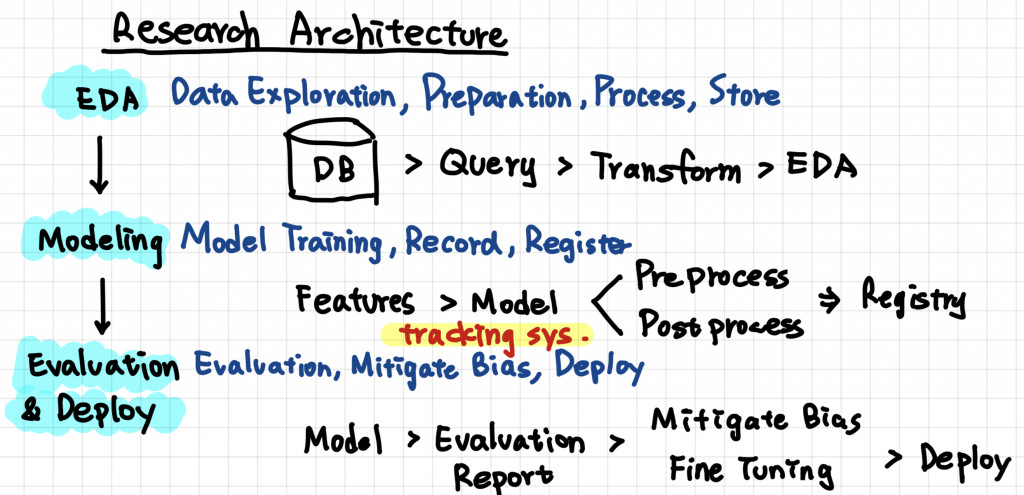
如上圖模型的研究很粗略的分成三塊,EDA, Modeling, Evaluation 和 Deploy,有透過 AWS Sagemaker 上模型的人對這一切應該不至於太陌生,所以這裡我會省略常見的步驟,專注在討論兩個題目:版本控制和 Bias
不管是 EDA 還是 Modeling 都會遇到一個問題就是,我們如何去管理我們的實驗中不同的嘗試,以及不同嘗試的產出,傳統上來說我們都會用 Github 來做特定的版本管理,但是版本管理有幾個問題
Data 版本管理最大的問題在於 Storage, 雖然有像是 Git LFS 這樣的工具可以提供,我們會在後面的 Data Version Control 主題討論更多 Git LFS 會遇到的問題
另外透過 Git 做實驗管理時會遇到的問題我們也會在後面的 Experiment Version Control and Tracking 討論要解決什麼樣的問題,以及透過 Lineage 以及 Artifacts 來知道在整個實驗中資料的流動是根據什麼樣的 Pipeline 以及後續的產出
但版本控制的重點就是要讓實驗可以被追朔,可以被重現最後來達到自動化實驗的目的也就常聽到的 AutoML
常見的 Bias 都是在實驗之前我們透過先驗知識或是標記資料中得知的,但有些 Bias 是很難被解決的,舉我們的題目 ATO 場景,常見的 Labeling 方式就是通過用戶客訴來拿到,但這樣的 Labeling 方式來說有兩個情境可能會照成 Bias,
當有些案例很難透過很好的 Process 或說他就直接在資料上就造成 Bias 要如何 Mitigate 並且更正確的 Evaluation 就是一個很重要的問題
後續的 Evaluation 就會針對這些繼續討論
那就等下週繼續寫關於 Experiment 相關的題目

