
實驗管理顧名思義就是 追蹤、筆記和分享每一次實驗的進度,可以參考下圖
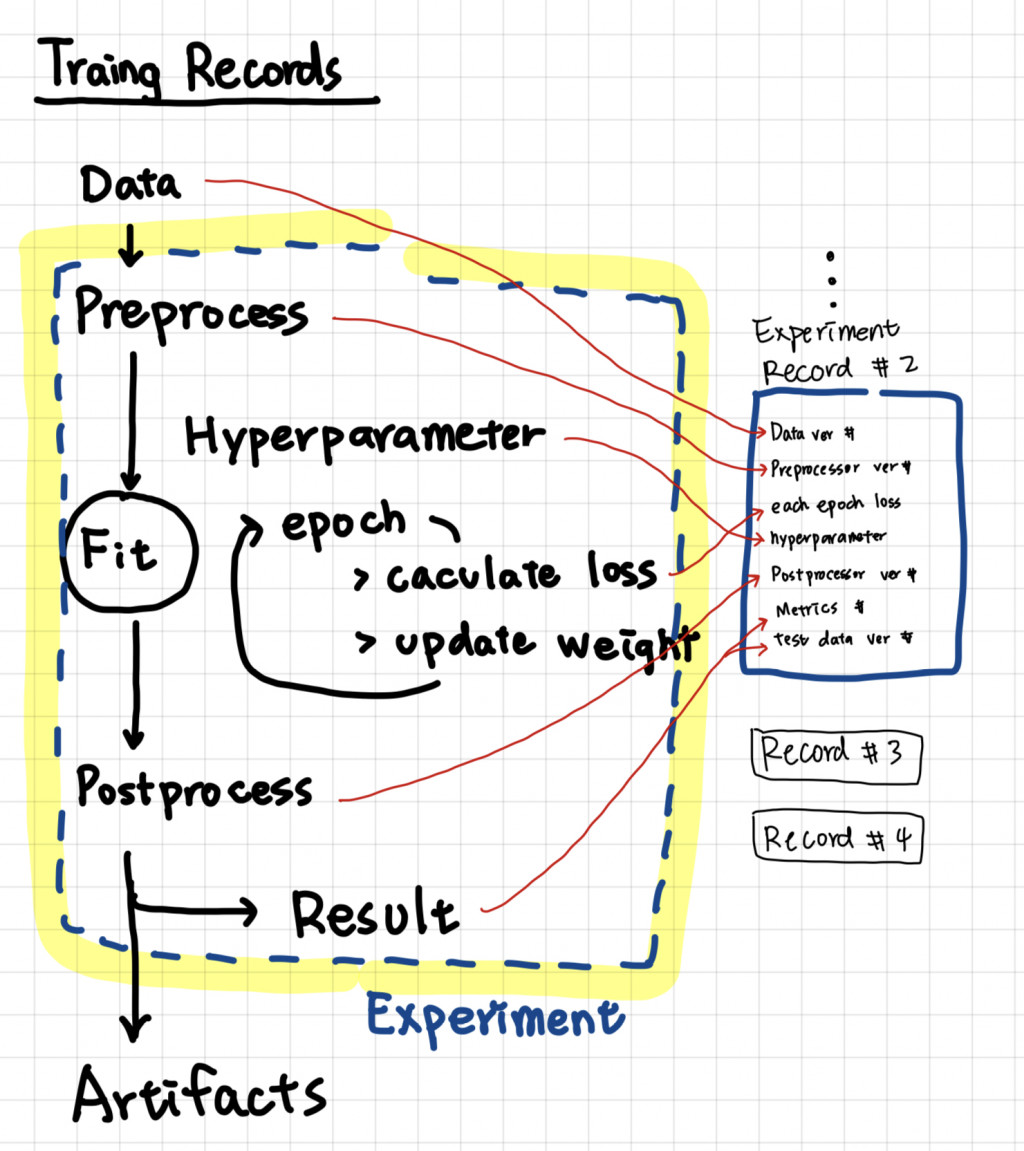
一個實驗通常包含以下幾項資訊
用 Jupyter Notebook 來做實驗管理以上這些資訊是非常困難的,更難以用"檔案名稱" 來做管理,當然可以透過一個 Folder 來做管理,但這樣會需要做很多額外的功能來解析 Folder 內的資料以及內容,所以一個比較好的方式是去使用一些套件或是 Service 來做到,可以做到這 Service 的方式非常多,有很多都將野心放在整個 MLops 系統的跟蹤,但一開始主要先介紹一款專注於 "實驗管理" 的套件 WandB 全名 Wright & Bias
Weights & Biases(縮寫為 WandB)是一個機器學習實驗跟踪工具,它可以幫助用戶記錄和視覺化模型訓練過程中的數據。其特色功能如下: 非常推薦直接看他們的介紹影片
最後 W&B 還支援在自己的 Cloud 上部署,很適合不希望資料流出的團隊,並且整個專案都包裝成 Containor 很容易部署
其他工具雖然也有提供實驗追蹤,但通常都是更全面的服務,以下我們簡介幾個
Sagemaker Studio 和 Training 是透過 Config 和 Model 兩個模塊把整個訓練過程做紀錄,最近也有嘗試集成更多的 Dashboard 來將線訓練和部署過程,優點是如果你全部照他們的建議流程 (從 Processing 到 Inference),有很多相關的工具可以使用 (Data Wrangler, Databrew, Autopilot 等等) 缺點是功能其實很不穩定,而且要做異質整合 (部分用 AWS Sagemaker 部分用自己架設的環境) 需要花比較多的心力
這算是業界很流行的開源軟體,但是他開源的版本不是非常好控制,通常需要花一定的人力去開發所需功能,原本的 UI 介面也比較陽春,通常選這個選項的公司都會考慮 Databrick 開發的版本,如上提到的如果要跟其他雲服務做異質整合會踩到很多雷,但 MLFlow 本身已經跨出純實驗追蹤的範疇了,比起這裡列的所有選項,開源就是他最大的優勢,可以讓團隊根據自己的公司的架構來實踐需要的功能
對於 TensorFlow 為基底的模型呈現很強大的視覺呈現,很多人會在訓練時使用,但他缺乏 MLOps 的其他功能,比較偏向個人或是小組取向的實驗,很容易堆積使用後即丟且不好管理的模型,但也是一個實驗追蹤的好工具
算是一套新的服務商,我都把他想成是類似 MLFlow 的雲端收費版本,有很多強大的介面也整合很多工具,最大的缺點就是貴 ... 但這可能也不是他的缺點
很多工具並沒有把自己定位在實驗管理,而是在服務整個 Machine Learning Life Cycle 的生態中,把實驗管理這塊做進去,可以依據自己的需求選擇
我會建議從以下幾個面向來做評估
