當有一個新的模型要來替換目前線上在使用的模型時,通常需要經過一連串的比較,除了透過像是 Accuracy, Pcrecision, Recall 等 Metrics 在 Testing Dataset 上表現比要好之外,更需要去量化視覺話,新的模型帶來多少進步,並檢測盒就模型相比是否一樣穩定
最暴力簡單的方式就是做 Shadow Test,與 A/B Test 不同,A/B Test 是將部份流到舊模型的流量部分流到新模型,然後比較兩者的結果如何;Shadow Test 是將所有流量在流到舊模型的時候同時流到新模型,但是模型的輸出與否不影響後續的行為
事實上兩者各有優缺點,A/B Test 會一定程度改變可觀測性,舉例來說如果模型發現被盜帳號都是透過釣魚信件來騙到用戶資訊,當模型偵測到這類行為,並能有效阻止這行為時,透過釣魚信件來騙用戶資訊的行為就會減少,轉而變成其他如 Man In The Middle 攻擊來騙取用戶資訊,這樣的結果就會導致觀測環境被改變,很難真的去衡量模型的好壞
另外在 Inference Score 上我們也會在進一步檢測
常見的方式都是在決定 Label 和決定 Threshold 下去針對模型做比對,但是從輸出分數的角度並搭配統計方法看,可以更全面的比較,分箱的目的就是把連續的統計分佈離散化,然後針對離散分佈做更近一步的統計檢測
常見的分箱方式有:
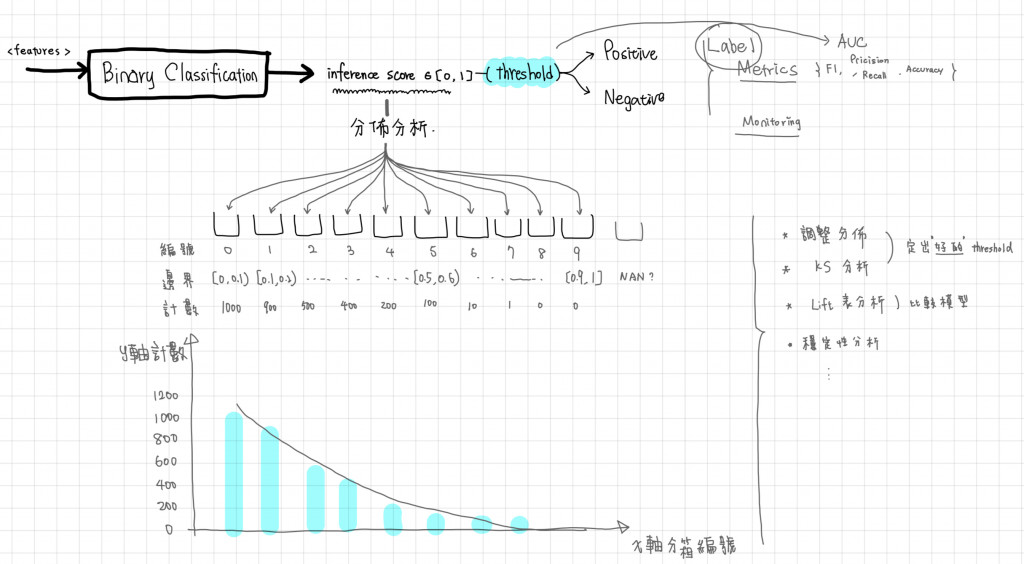
有了分箱後,我們可以做以下幾種統計量比較
IV 是量化某個分部對於目標的分辨比例,針對每一箱的 Positive/ Negative 做 Weight of Evidence (WOE) 值得計算,這個值可以就看成 Positive 樣本的比例,而 IV 可以看作是 WOE 的加權分數,目的是看模型的預測能力 (或說好壞的分辨能力),與之前的 KS Test 很像,但是 KS 更像是連續分佈的檢測,IV 是屬於連續分佈的範疇
事實上 IV 可以處理的 Range 不限於 0 ~ 1 之間,只要可以做分箱都可以做 IV 檢測,因此 IV 的檢測方式也很常用在特徵上做檢測,甚至可以拿來做特徵值的篩選
PSI 與 IV 在計算上非常的相似,數學上看起來幾乎是一樣,但是 PSI 不是針對每一箱的 Pos/ Neg 做比較,而是針對每一箱的兩個時間點做切割,兩個時間點可以是:
和 IV 相同,不局限於 Inference Score,也可以針對 Feature Value 做檢驗,數值大代表差異大,也就是說模型相對不穩定,如果特徵值訓練和測試的 IV 值很大,可以表示資料發生一定程度的 Concept Drift
換句話說如果第二個模型和第一個模型的 Inference Score 差異非常大,可以預期模型的表現非常不穩定或說不一致,這樣的模型上上去會造成不小的問題
Lift Table 透過視覺化的放來呈現正樣本與的變化,並且可以直接透過圖表看到不同的閥值對圖表的影響,通常我會整理成如下一個圖表
Lift 值的意義既受相對於隨機猜測,你的表現有多好,一般 Lift > 1 表示模型的預測能力比隨機猜更好,一般來說我們希望模型表現的隨機好,並且有好的好壞分辨能力,如果就上的表來解讀,我會認為這個模型從 Lift 看是有區分能力的,但從 IV 角度來看他並不是非常穩定,特別在最大一箱,我會嘗試去用一些規則濾掉那些明顯的案例重新訓練模型
最後回到一開始的模型比較,我們要來透過 Swap Table 來做模型比較,以下是一個 Swap Table 的範例,舉 old model 3, new model 4 為例M,數值是 483,697 代表在同樣的分箱方式,原本模型第三箱 (分數介於 0.3 ~ 0.4) 中有 483697 個 case 會跑到 第四箱 (0.4 ~ 0.5),一樣的想法,如果今天有些在就模型分數很高像是舊模型的第九箱,但在新模型跑到第 0 箱,像是圖表左下角的 85641 個案例,這可能會是很嚴重的事情,就需要去針對這些模型做解釋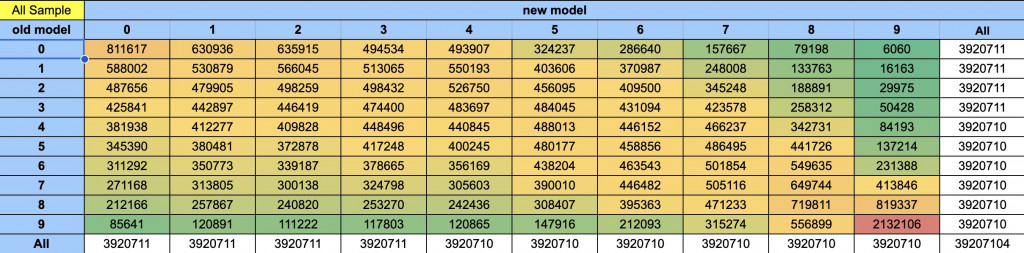
總之今天介紹了一些不同的方式去更一步檢驗模型,並依照這些檢驗的思路,去檢驗模型的迭代,在 MLOps 系統中,如何自動化的監測這些數字來幫助模型迭代都是非常重要的

