強化學習的本質就是靠獎勵,不斷刺激網路,使得智能體選擇可以取得最大獎勵的動作輸出。很重要在講三次。
強化學習的本質就是靠獎勵 x 3 
用簡單的圖片來說明整個輪廓,共有四個部分,分別為環境 (Enviroment), 狀態 (state), 獎勵 (reward), 智能體 (agent)
Environment
負責處理 state 與 reward 的返回,可能會有一些資料的管理,主要是跟 Agent 互動的一個抽象類別。這邊的設計可以參考 gym 的文件。
State
外界環境,智能體會需要互動的對象,就像是我們打槍戰遊戲,畫面的本身就可以是Agent的返回值,當然還可以是血量、彈藥數量、剩餘時間…
比較複雜的環境Open Five,在訓練的時候,為了很好訓練模型,結構化的資訊有到上萬筆…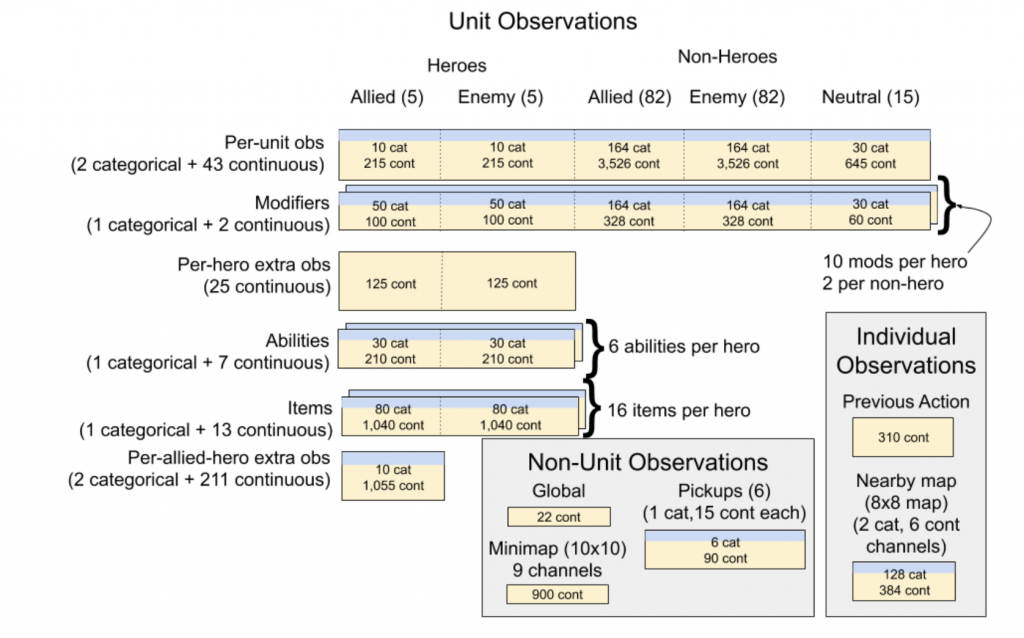
Reward
這跟演算法訓練得好不好有很大的關聯,像是Doom的射擊遊戲,就根據射擊、命中、吃醫藥包都有給固定值,獎勵的大小就決定了模型執行任務的優先順序。這邊要注意的是盡可能把獎勵分成不同層次設計,如果獎勵本身有衝突,那就會訓練得不好,或是它太在乎某些獎勵,例如遊戲中 agent 可能會因為想保命,躲在角落瑟瑟發抖拖台錢,這就不是設計者所期望的,通常會給一個很小的懲罰值,可能-0.001,使模型不會在那浪費時間。也有一些進階的玩法,可以讓模型自己學習怎麼輸出獎勵,我們稱之為逆強化學習 (Inverse reinforcement learning)
Agent
智能體就看我們的應用場景而設計,可以輸出連續也可以離散,甚至可以是混合的,但是不太好訓練。在神經網路的應用中,我們就會針對網路輸出的格式,去挑選它的機率分佈。
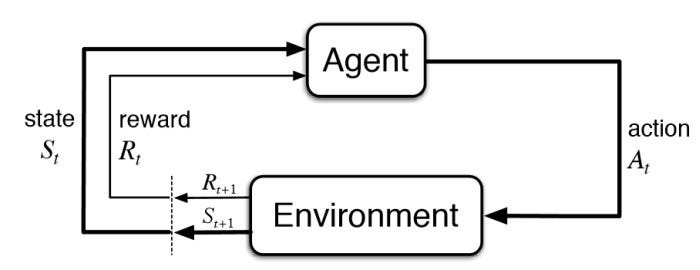
這大概就是整個互動方式,強化學習許多傑出的研究,不外乎就圍繞在這幾塊進行,像是更複雜的智能體、更結構性的狀態、更彈性的獎勵 … 還有些比較工程的研究,像是提供物理模擬的 Pybullet,很多 RL 研究在使用,還有高效的分散式框架 Ray ,整個生態系到現在也是如火如荼的發展中。


 iThome鐵人賽
iThome鐵人賽