
我們今天把基礎查詢方法的坑填上~
今天會介紹
phrase search:
GET /test_phrase/_search
{
"query": {
"match_phrase": {
"desc": "value"
}
}
}
// 原始文檔
"desc": "I'm testing a Function!"
// 搜尋語句
"desc": "m test" // 會找不到
"desc": "test a function" // 可以找到
{
"query": {
"match_phrase": {
"desc": "value",
"analyzer": "your_analyzer",
"slop": 1
}
}
}
這邊說一下slop:
| position 1 | position 2 | position 3 | |
|---|---|---|---|
| Document | Es | is | good |
| your query | is | ES | |
| first slop | → | ES/is | |
| second slop | ES | ← |
Fuzzy match query:
Fuzzy query:
Search object, nested:
// 示範index
PUT /test_nested_index
{
"mappings": {
"properties": {
"obj": {
"type": "nested"
}
}
}
}
// query
GET /test_nested_index/_search
{
"query": {
"nested": { //需要表明是nested
"path": "obj", // 表明路徑是哪個nested field
"inner_hits": {
"name": "my_hits",
"size": 3 // 減少inner_hits的返回數量能加速查詢速度
},
"query": {
"match": {
"obj.xxx": ""
}
}
}
}
}
"hits": [
{
"_index": ...,
"_type": ...,
"_id": ...,
"inner_hits": {
"<inner_hits_name>": {
"hits": {
"total": ...,
"hits": [
{
"_id": ...,
...
},
...
]
}
}
},
...
},
...
]
Search join field:
GET /test_join_search/_search
{
"query": {
"has_child": { // 依照需求決定是has_parent還是找has_child
"type": "my_child",
"query": {
"match": {
"number": 1
}
},
"inner_hits": {}
}
}
}
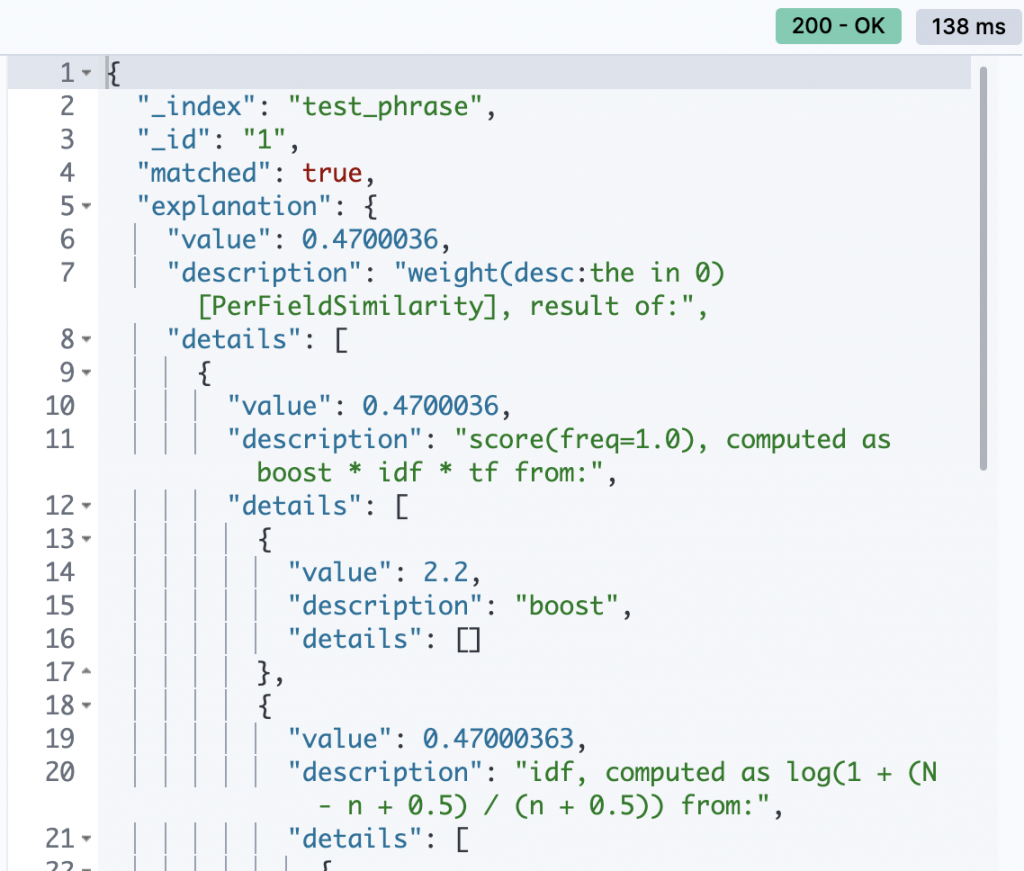
Relevance score:
GET /test_phrase/_explain/1
{
"query": {
"match": {
"desc": "the"
}
}
}
Search multiple fields:
GET /test_phrase/_search
{
"query": {
"multi_match": {
"query": "cheese",
"fields": ["name^2", "desc"], // 讓name匹配時,分數*2
"tie_breaker": 0.3
}
}
}
明天我們會開始進到compound queries
先前我們都只做單一查詢,沒有用到什麼and跟or或是must等等概念
而明天開始則會介紹複合的查詢語句,讓我們更能夠去貼近使用時的查詢邏輯~
參考資料
Match phrase query:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html
fuzziness:
https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html#fuzziness
match fuzzy參數詳解:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html
nested query:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-nested-query.html
joining query:
https://www.elastic.co/guide/en/elasticsearch/reference/current/joining-queries.html
inner hist:
https://www.elastic.co/guide/en/elasticsearch/reference/current/inner-hits.html#inner-hits
relevance score:
https://opster.com/guides/elasticsearch/search-apis/elasticsearch-scoring-understanding-the-explain-api/

 iThome鐵人賽
iThome鐵人賽