接下來我們將介紹 pettingzoo 這個多智能體的環境。在跟單智能體相比, multi-agents 如何交互、決定順序、以及動態如何增加或遞減智能體,在工程上都是一個很大的挑戰。Pettingzoo 累積了過去許多研究與工程的優缺點,以及介紹 ACE (Agent Environment Cycle)這個概念。
一般的 RL 環境觀察以 POMDP (Partially Observable Markov Decision Process)概念去進行演算法與環境交互,一種最熱門的多智能體模式為 POSG (partially observable stochastic game),為了在multi-agent 達到檢簡易、清晰的交互概念,pettingzoo 提供了ACE的流程。如圖
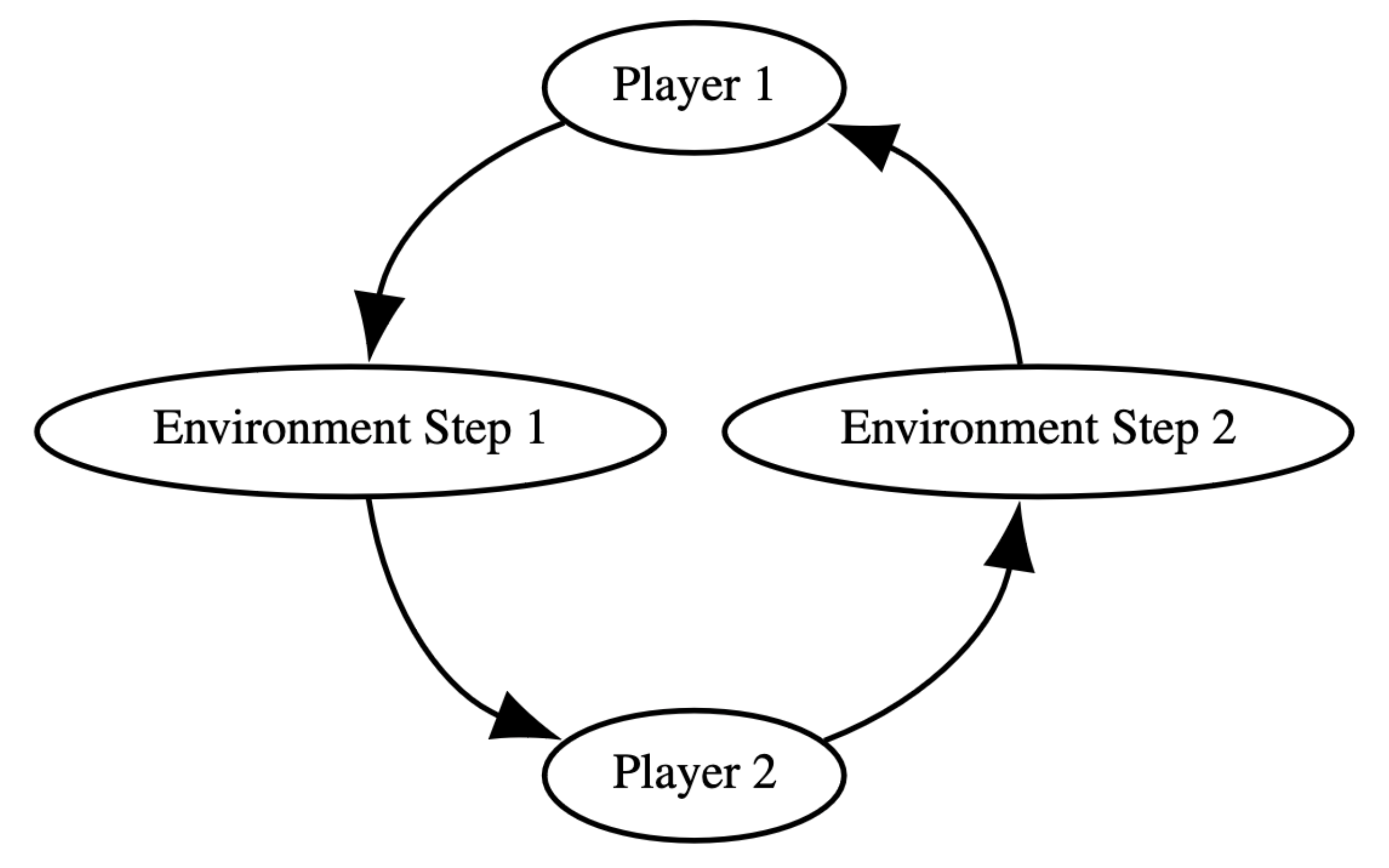
一個 agent 結束後的行為,影響環境,環境返回下一個 state 給下一個 agent。不過這種速度肯定很慢的,所以官方另外提供一個方法 Parallel API ,讓使用者在更大規模的智能體的時候,可以包覆使用。不過我也蠻好奇的底層怎麼時做的,如果不是一個接一個去跑的話,可能 agent 彼此間會造成些隨機性與噪音,這可能就要看看底層文件來深究了。
安裝 pip install pettingzoo 就可以使用哩,另外可以裝一些其他的環境套件
pip install pettingzoo
pip install pettingzoo[atari]
pip install pettingzoo[all]
這邊可以做些環境設定,設定完成後就可以跑模擬了~
from pettingzoo.butterfly import cooperative_pong_v5
env = cooperative_pong_v5.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# this is where you would insert your policy
action = env.action_space(agent).sample()
env.step(action)
env.close()
cooperative_pong_v5 是指定的虛擬環境,env可以設定變數,例如是否要看畫面還是只有圖像矩陣。
env.agent_iter 就是剛剛提到的讓每個環境可以像是迴圈一樣,逐個執行。
env.last 的話就是執行後所獲得的狀態與資源。
多智能體的困難隨著數量與任務性質的複雜性,要解決許多工程上的問題,我們算是蠻幸運的在這一塊有許多成熟框架的時期。不過效能優化還會遇到資源有限的瓶頸問題,這時候還是要看你或是公司的銀彈夠不夠拉~


 iThome鐵人賽
iThome鐵人賽