使用Chinese LLama2專案的很多方法可以參考
${Root}/scripts/README.md,training/finetune/inference的教學以及說明
意外發現這邊提供針對單顯卡指令精調的教學,精調的文件格式默認為json,內容一樣是依據Stanford Alpaca格式:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
scripts/training/bash run_sft.sh內容修改指定training data與validation data的dir路徑
--tokenizer_name_or_path: Chinese-LLaMA-2 tokenizer所在的目录--dataset_dir: 指令精调数据的目录,包含一个或多个以json结尾的Stanford Alpaca格式的指令精调数据文件--validation_file: 用作验证集的单个指令精调文件,以json结尾,同样遵循Stanford Alpaca格式--flash_attn: 启用FlashAttention-2加速训练--load_in_kbits: 可选择参数为16/8/4,即使用fp16或8bit/4bit量化进行模型训练,默认fp16训练。這邊引用原說明關於單卡24G VRAM指令精調時,特別需要注意的問題
关于显存占用 (避開單卡OOM問題)
默认配置训练llama,单卡24G会OOM,可以删去脚本中的--modules_to_save ${modules_to_save} , 即不> 训练embed_tokens和lm_head(这两部分参数量较大),只训练LoRA参数,单卡使用显存约21G。
如果是在已有LoRA基础上继续微调,需要修改peft_path下的adapter_config.json文件,改为"modules_to_save": null
减小max_seq_length也可降低训练时显存占用,可将max_seq_length设置为256或者更短。
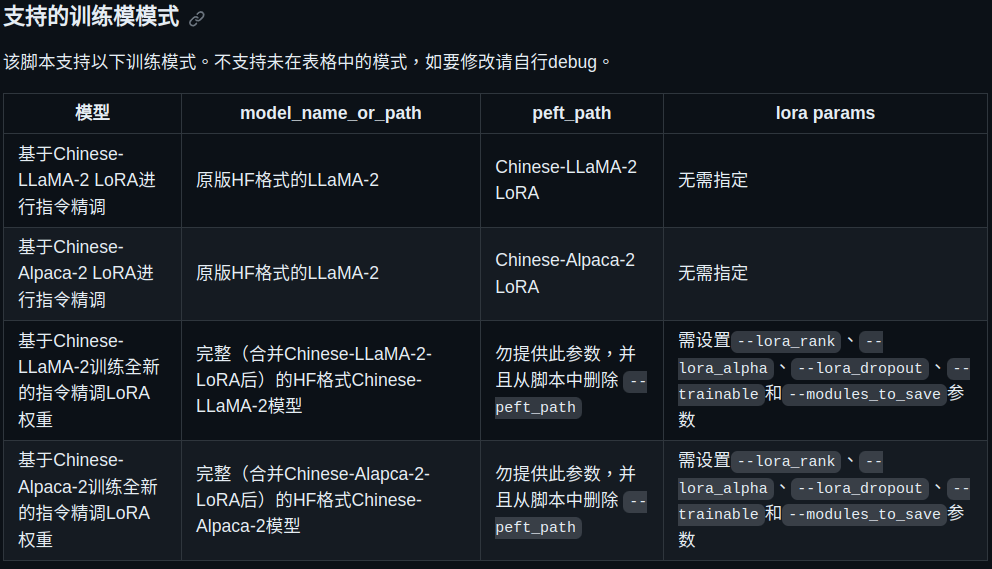
此腳本支援下圖中的finetune方法
引用原說明:
该脚本支持以下训练模式。不支持未在表格中的模式,如要修改请自行debug。
修改完以後, 開始instruction finetuningcd ./scripts/trainingbash run_sft.sh