
為什麼需要 Spark ?
MapReudce 的出現雖然解決了大數據離線計算的需求,但其有一些缺點存在,比如:
-
高延遲:MapReudce 在計算時通常需要進行多次的硬碟 I/O,這大大降低了計算性能,也造成了較高的處理延遲。
-
編程模型複雜:開發人員需要手動編寫 Map 與 Reduce 函式,同時還需要處理資料分發、排序以及錯誤處理等問題,這使得開發與維護 MapReduce 變得非常繁瑣。
-
適用性受限:MapReduce 適合用於離線的批處理上,在實時數據流、迭代計算或是一些複雜的處理中表現較差。
Spark 的出現即是為了解決上述這些問題。
Spark 簡介
Apache Spark 跟 MapReduce 一樣屬於分散式的大數據的處理框架,最初由加州大學柏克萊分校的 AMPLab 開發,使用 Scala 編寫,目標是「One stack to rule them all」,也就是在一套架構下處理所有的大數據任務,現在由 Apache 基金會負責維運。
Spark 的優點包括:
-
速度快:Spark 通過內存(記憶體)計算和執行引擎優化來降低數據處理的延遲,在處理速度上優於傳統的 MapReduce,官方說法是快了 10~100 倍。此外,由於 Spark 將中間數據保留在內存當中,因此特別適合用在迭代計算上,如機器學習與圖處理。
-
簡化編程模型:Spark 提供了高級 API,如 Spark SQL、DataFrame 和 Structured Streaming,使用者能更輕鬆地編寫程式,而不用手動編寫 Map 和 Reduce 函式。另外,Spark 也支援多種程式語言,包括 Scala、Java、Python 和 R,使用者可以選擇熟悉的程式語言進行開發。
-
高適用性:除了批處理外,Spark 擁有豐富的生態系統,包括 Spark Streaming (實時處理)、MLlib(機器學習)和 GraphX(圖形處理),能適用在多種處理情境。
Spark 抽象層
在 Spark 的架構中包含了兩個重要的抽象層 (abstraction layer),分別是:
-
Resilient Distributed Datasets (RDD)
RDD 是 Spark 中的一種抽象數據結構,是 RDD 的核心數據結構,接下來的文章會對 RDD 做更詳細的介紹。
-
Directed Acyclic Graph (DAG)
DAG 是一種圖形結構 (有向無環圖),用來表示 Spark 作業的執行計畫、描述作業之間的依賴關係和任務順序,Spark 會將使用者的操作轉換為 DAG,以優化性能與資源的利用效率。
Spark 架構
Spark Core 實現了 Spark 的基本功能,採用主從架構 (Master / Slave),主要有三個核心組件,分別是 Spark Driver、Cluster Manager 與 Spark Executor:
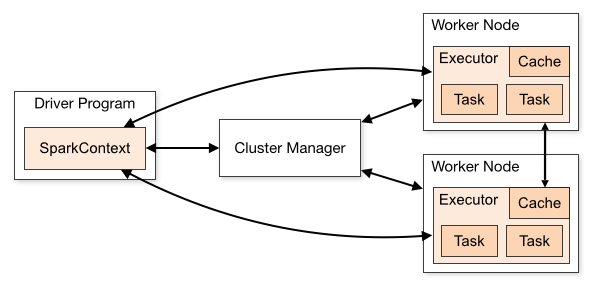
(圖片來源: Spark Components)
驅動程序 Spark Driver
主程式 (Master) 的部分,一般會在集群中的一個節點上,透過 SparkContext 物件來協調應用程式的執行,負責分配任務給各個工作節點,並監控應用程式的執行狀況。
集群管理器 Cluster Manager
負責集群的資源管理任務,可以選擇使用:
-
Standalone:Spark 內建的資源管理器,適合單一集群上的應用,提供基本的資源分配和管理功能。
-
Apache Mesos (Deprecated):分佈式資源管理器,可用於多個集群上,包括 Spark 應用程序,並提供彈性的資源分配和多工作負載管理。
-
Hadoop YARN:Hadoop 的資源管理框架,能夠集成Spark 並共享集群資源,實現多種工作負載共存。更詳細的工作原理可以參考前幾天的文章:Day05 Hadoop 介紹
-
Kubernetes – 容器化的集群管理平台,支援 Spark 容器的運行,提供彈性和自動化的資源配置和管理。
執行程序 Spark Executor
每個工作節點上運行著多個執行程序,每個執行程序負責處理任務的一部分。它們能夠在記憶體中存儲數據,以實現高性能的計算。
每個應用程式 (SparkContext 物件) 都有自己的執行程序,應用程式之間彼此獨立,有各自的執行程序,這也導致除非使用外部存儲系統,否則不同應用程式之間的資料無法直接進行分享。
預告
明天會深入介紹 Spark 的數據結構:RDD、DataFrame、DataSet。
參考資料
《實戰大數據 (Hadoop + Spark + Flink) 從平台構建到交互式數據分析 (離線/實時)》- 楊俊
Apache Spark Architecture – Detailed Explanation
Spark Components


 iThome鐵人賽
iThome鐵人賽