前言
昨天的文章介紹了 Spark 的架構,還沒看過的人可以先看看:Day13 - Spark 介紹 (1):簡介與架構
昨天有提到,Resilient Distributed Datasets (RDD) 是 Spark 的核心數據結構,RDD 直接翻譯成中文是彈性-分散式-數據集,因此白話地說,RDD 就是一個「數據的集合」,其數據被「分散存儲」在群集中的多個節點上,且「有彈性」,意思是指 RDD 雖然預設存放於記憶體中,但當記憶體資源不足時會自動改為存入硬體,由 RDD 自動權衡與切換記憶體與硬體之間的存儲。
較為正式的說法是,RDD 是不可變、分區、可平行處理的資料集合:
Shuffle
Shuffle 本身不算是操作類型的一種,而是只有在部分 Transformation 操作中會被觸發的一種機制。Shuffle 會將數據重新分配,使新的分區結果與原先的分區結果有所不同,這些操作通常涉及 executors 之間的數據溝通,如因此運算成本很高,應該謹慎使用。
- 會導致 Shuffle 有操作包括:repartition 類、ByKey 類與 join 類
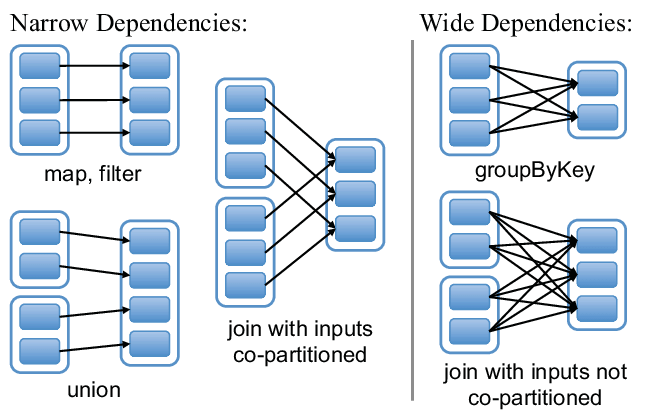
Narrow Dependency 窄依賴
Parent RDD 的一個分區最多只會對應到 Child RDD 的一個分區。
對於部分 Transformation 來說,其轉換具有一對一的映射關係,也就是 RDD 在轉換時並不需要進行跨分區的數據溝通,如 map()、filter(),而新產生的 Child RDD 的分區關係理所當然直接依賴於 Parent RDD 的分區。
Wide Dependency 寬依賴
Parent RDD 的一個分區可以對應到多個 Child RDD 的一個分區 (需要 Shuffle)。
部分 Transformation 操作會觸發 Shuffle 機制進行跨分區的數據溝通,如 reduceByKey()、groupByKey(),而這也導致 Child RDD 的一個分區通常需要依賴於 Parent RDD 的多個分區。
RDD 雖然是 Spark 的核心,但使用起來比較複雜,因此現在主流的用法是使用更高階的抽象 API,也就是明天準備要介紹的 SparkSQL、DataFrame、DataSet。
RDD Programming Guide
RDD vs. DataFrame vs. DataSet
Apache Spark - RDD
说下spark的RDD
Spark RDD 之间的依赖关系


 iThome鐵人賽
iThome鐵人賽