UnitY模型由四個模組組成:語音編碼器、第一階段文本解碼器、文字轉語音單元 (T2U) 編碼器和第二階段單元解碼器。UnityY 不只承襲Translatotron2模型,同時也做了五項修改:(1) 在第一階段文本解碼器生成子詞(subwords,如forest含有子詞rest)而不是生成音素(phoneme),(2)在第二階段單元解碼器生成離散語音單元而不是頻譜圖,如此可以繞過該語音事件的時間建模(duration modeling),(3) 用Transformer層取代兩個解碼器中的長短期記憶模型(Long Short-Term Memory, LSTM), (4) 在兩r解碼器之間導入T2U(Text-to-Unit)編碼器,(5) 分配更多容量給第一階段解碼器。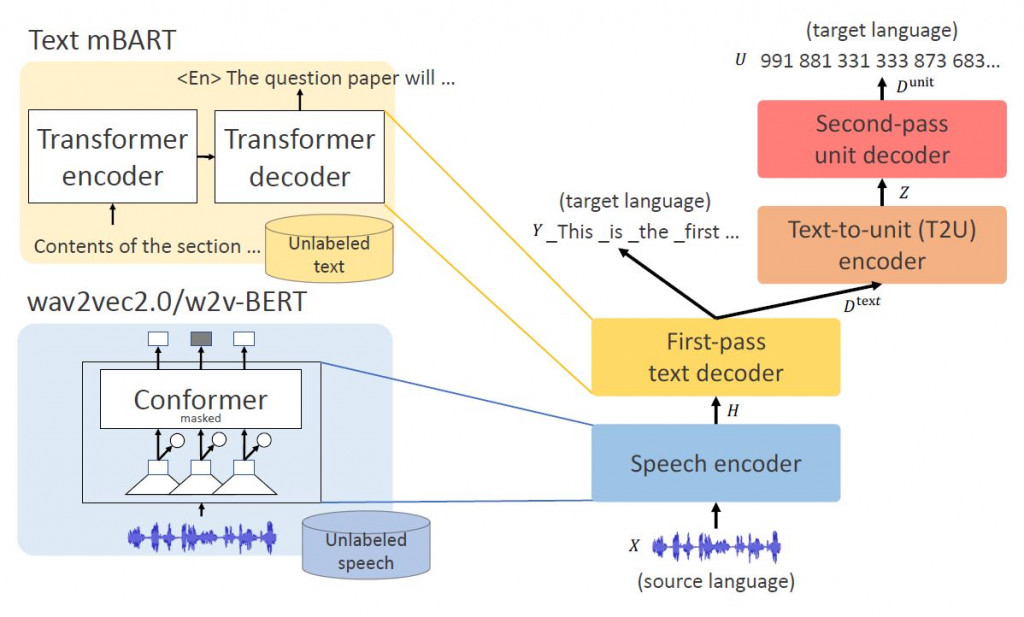
*FAIR, Meta AI♡, Carnegie Mellon University, “UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units”, arXiv:2212.08055v2, 2023
Speech encoder本質上是一個Conformer(Convolution-augmented Transformer),結合CNN模型與Transformer,有效率地對語音序列局部及全局編碼。
第一階段文本解碼器,透過speech encoder的輸出結果生成子詞(subwords)序列。生成子詞而非音素的五大優點:(1) 序列長度大幅減少,提升訓練推理效率;(2) 在第一階段文本解碼使用大量詞彙可以改善翻譯品質;(3) 文本輸出幫助聽者邊聽邊理解翻譯內容;(4) 不需要準備目標語言的字素轉音素集合,所以可以更容易擴展到更多語言;(5) 不需要複雜的後處理(如WFST,基於HMM模型中最複雜的語音辨識解碼器)就能產生易讀的文本。
T2U(Text-to-Unit) encoder作為文本及語音單元解碼器之間的橋樑,且這轉換不需要改變序列長度。
第二階段語音單元解碼器,透過T2U encoder的輸出結果生成離散序列單元(Unit)。只要單元生成,就可以送入後級Vocoder,將離散的語音單元轉為聲波訊號。
SeamlessM4T中最重要的模型UnitY Model主要組成有四個部分:(1) 語音編碼器 (2) 第一階段文本解碼器 (3) T2U編碼器 (4) 第二階段單元語音解碼器,四個部分彼此連貫一氣呵成,將語音訊號轉譯為另一個語言的語音單元,最後送入UnitY Model以外的Vocoder(聲碼器)合成目標語音聲波訊號。

