
本章節,我們將深入探索 Kube-Prometheus-Stack 的實際運作。雖然在前一階段,我們順利、迅速地按照指引建立了一套完善的 Prometheus 監控系統,但在感嘆其便捷性的同時,我猜想許多人的心中或許和當初的我一樣,滿腹疑惑:「到底發生了什麼?我剛做了什麼?」經驗老道的工程師們都知道,無論部署哪一套環境敏感、結構複雜的系統,總會有一些調皮的的小臭蟲跟錯誤,悄悄地等待著,時機成熟就跳出來給你一個意外的驚喜。
所以,在這一章,我們將一探 Kube-Prometheus-Stack 在幕後的核心運作機制,這不僅是我們調整各式環境設定的重要基石,也是解決未來問題的關鍵。接下來,讓我們一同探索、挑戰,並努力從錯誤中學習。
在前個章節中,我們使用精簡的設定短短時間內,產生了開箱及用的 Prometheus 監控系統,現在就讓我們一探究竟其中的奧妙吧。
完整 Helm Values 參數設定檔,請查看前面章節,以下將拆分區塊講解。
fullnameOverride: "prometheus-stack"
fullnameOverride、nameOverride 以及 namespaceOverride 在 Helm Values 參數設定檔中都是一些常見的不成文命名參數。它們通常被用於提供自定義的名稱或命名空間,以覆蓋 chart 中的預設配置。當用戶希望在部署 Helm chart 時使用特定的資源名稱或命名空間,而不是 chart 預設提供的那些時,這些選項變得非常有用。透過這些參數,用戶可以更有彈性地控制其 Kubernetes 資源的命名,以符合其部署或組織的特定標準和需求。
在這裡我個人習慣將 fullnameOverride 保持被設定的狀態,這樣可以確保 Helm Chart 建立出來的眾多資源,不會被我的 Release Name 套用到。
kubeScheduler:
enabled: true
kubeControllerManager:
enabled: true
kubeEtcd:
enabled: true
kubeProxy:
enabled: true
kubeApiServer:
enabled: true
在 Kube-Prometheus-Stack 你可以很輕易的看到好幾個有關 Kubernetes 叢集運作所需的核心組件設定:
這些設定都是有關於是否建立抓取(scraping)這些核心組件的指標的 CRD - ServiceMonitor 以及建立相關 Grafana 圖表。
某些 Kubernetes 叢集環境中的主節點由雲端平台託管,或是因為預設底層設定限制,導致我們無法如預期中,正常抓取到主節點核心元件指標,但通常平台供應商都有對應的解決方案完成這個需求。
kube-state-metrics:
prometheus:
monitor:
enabled: true
selfMonitor:
enabled: true
kubelet:
enabled: true
serviceMonitor:
cAdvisor: true
nodeExporter:
enabled: true
hostRootfs: true
prometheus-node-exporter:
hostRootFsMount:
enabled: true
以上相關設定主要在於,取得 Kubernetes 叢集中的資源使用情況和其他系統指標,是眾多預先建立的實用 Grafana 圖表中的指標來源:
由於各種運行 Kubernetes 叢集環境不同,很多人會遇到 nodeExporter 發生不斷重啟的現象,這些多半是因為當前運行環境並不允許讀取根目錄,而這時將 hostRootFsMount 設定為 false ,可以解決大部分重啟的問題。
ref: https://github.com/prometheus-community/helm-charts/issues/467
alertmanager:
enabled: true
在這裡如果開啟了 Alertmanager,代表我們的 Prometheus 將預設與內建的 Alertmanager 串接,並且藉由以下 Kube-Prometheus-Stack 的 Helm Values 參數設定檔,提供上百條 Prometheus Rules 供我們作為 Kubernetes 叢集最基本的告警。
## Create default rules for monitoring the cluster
##
defaultRules:
create: true
rules:
alertmanager: true
etcd: true
configReloaders: true
general: true
k8s: true
kubeApiserverAvailability: true
kubeApiserverBurnrate: true
kubeApiserverHistogram: true
kubeApiserverSlos: true
kubeControllerManager: true
kubelet: true
kubeProxy: true
kubePrometheusGeneral: true
kubePrometheusNodeRecording: true
kubernetesApps: true
kubernetesResources: true
kubernetesStorage: true
kubernetesSystem: true
kubeSchedulerAlerting: true
kubeSchedulerRecording: true
kubeStateMetrics: true
network: true
node: true
nodeExporterAlerting: true
nodeExporterRecording: true
prometheus: true
prometheusOperator: true
windows: true
grafana:
enabled: true
adminUser: admin
adminPassword: admin
defaultDashboardsEnabled: true
defaultDashboardsTimezone: Asia/Taipei
grafana.ini:
users:
viewers_can_edit: true
persistence:
accessModes:
- ReadWriteOnce
enabled: true
size: 10Gi
type: pvc
這裡我們透過簡單明瞭的設定,建立出了預設就與 Prometheus 串接好的 Grafana 服務:
而我們在 Grafana Setting 也可以看到更多目前設定狀態。
prometheusOperator:
enabled: true
crds:
enabled: true
PrometheusOperator 的主要功能是監控 Kubernetes 服務以及用於 Prometheus 本身的管理操作,如版本升級和配置變更。透過監聽相應的 CRD 物件,Operator 可以自動化地創建、配置和管理 Prometheus 實例和其相關組件。
Prometheus Operator 結合了 Kubernetes 的 Custom Resource Definitions (CRDs) 功能,極大地提高了在 Kubernetes 叢集中部署和管理 Prometheus 的便利性。這種整合不僅使得 Prometheus 的設定和擴展變得更為直觀,而且還能更好地與 Kubernetes 原生的服務和工作負載整合,實現自動服務發現和指標抓取。此外,通過 Prometheus Operator 提供的 CRDs,使用者可以更方便地定義監控目標、警報規則和其他相關設定,而不需要直接修改 Prometheus 的配置文件。
以下為現有的 CRDs:
Prometheus Operator 團隊到目前依然不斷的新增更多實用的 CRDs,使得 Prometheus 在 Kubernetes 環境中的整合更加深入和靈活。這些新的 CRDs 不僅提供了更多的配置選項和功能,還允許開發者和運維團隊更精細地控制和調整監控策略。隨著時間的推進,我們可以預見 Prometheus Operator 會持續提供更加完善的解決方案,滿足現代雲原生應用的多樣化和持續變化的監控需求。
prometheus:
enabled: true
agentMode: false
prometheusSpec:
enableFeatures: []
enableRemoteWriteReceiver: false
remoteWriteDashboards: false
retention: 10d
remoteWrite: []
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: hostpath
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi
additionalScrapeConfigs: []
在這裡我們進行了對 Prometheus 實體的相關設定,基本上有關於 Prometheus 本身的設定,都可以在此區塊進行設定調整,像是 Scrape、Rule、Alert 等等相關功能:
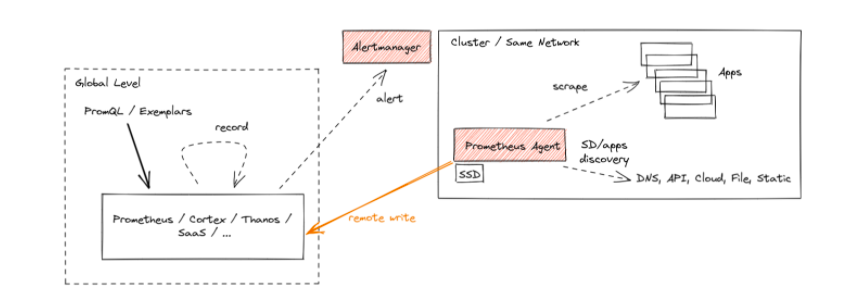
hostpath 的存儲類,其他環境中需要依情況指定存儲類名稱。在上述設定中,一個值得關注的特點是 Prometheus 的 Agent 代理模式。從 v2.32.0 版本開始,此模式被視為實驗功能,主要針對遠端寫入的需求設計。在代理模式下,Prometheus 禁用了查詢和警報功能,並將本地存儲轉變為自訂的時序資料庫(TSDB)的預寫式日誌(WAL)。儘管如此,抓取策略、服務探索及其相關配置都維持原狀。
若用戶的主要需求是將數據轉送到遠端的 Prometheus 伺服器或其他支援遠端寫入的專案,且無需在本地執行查詢、發出警報或向外部串流指標,則代理模式便十分適合。此模式不僅提高了效率,還易於擴展。
在這章節裡,我們詳細地解構了 Kube-Prometheus-Stack 的設定參數。每一個參數都有其特定的角色和目的。但更重要的是,我們必須深入理解即將使用的服務。儘管面對繁多、如同劉姥姥進大觀園的設定參數,只要我們細心地分區與拆解,都能夠構建一套完全符合自己應用需求的監控世界。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day14
References
Prometheus - Monitoring system & time series database

 iThome鐵人賽
iThome鐵人賽