訓練好AI模型之後,我們可以從不同的觀點來去驗證AI模型。以下針對分類模型的幾種驗證方法,分別跟大家介紹。
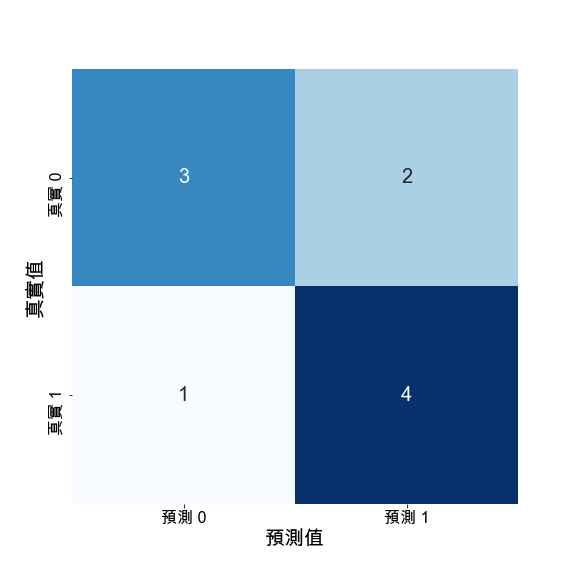
以二元分類來說明Confusion Matrix。模型分別預測0與1,這時候,就會有四種排列組合:
如下圖,Confusion Matrix就是去呈現實際答案跟模型預測的相對關係。透過這種方式,我們可以直觀觀察模型今天預測錯誤,主要問題發生在哪,是False Positive呢?或是False Negative的問題呢?如果是多元分類,還可以進一步觀察是哪一些類別導致模型特別容易預測錯誤,可以依此對症下藥,去調整資料前處理或者模型訓練權重的調整。
Precision的公式是TP/(TP+FP)。這個指標特別關注在FP的問題上,當FP越大,Precision越差。實際案例來看的話,例如冤獄,抓錯人會讓這個人白白坐牢很久。
Recall的公式是TP/(TP+FN)。這個指標特別關注FN的問題,如果FN越大,則Recall數值越小。實際應用案例的話,例如詐騙偵測、重大疾病檢查、防毒軟體檢測。換言之,寧可錯殺,也不放過。
F1 Score同時考量到Precision與Recall,其公式是= 2*(Precision*Recall)/(Precision + Recall)
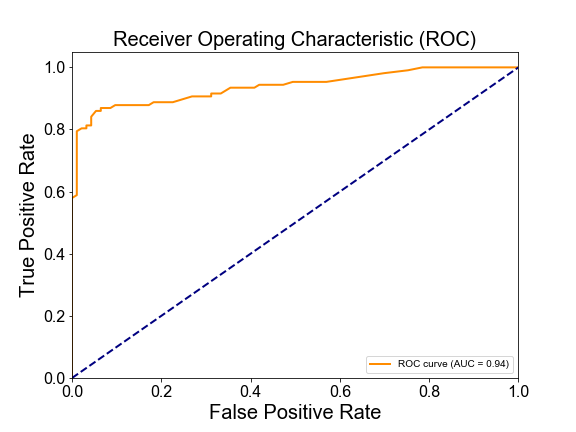
ROC(Receiver Operating Characteristic Curve)的橫軸是False Positive Rate,縱軸是True Positive Rate。相當而然,False Positive Rate越小,並且True Positive Rate越大,模型的表現就越好,因此我們期待看到曲線落在左上方的角落。圖中的對角線表示隨機去猜測的結果,因此,模型表現只要高於這條對角線,就表示已經表現得比隨機猜選來的好。
而AUC(Area Under Curve),則是表示ROC曲線下的面積。因此,當這個面積越大,就表示模型表現越好。面積如果是0.5,則是隨機猜測的表現。因此,只要AUC大於0.5,就表示表現優於隨機猜測。
ChatGPT出題時間到了:
問題1:
您正在開發一個垃圾郵件分類器,該分類器的目標是確保不會將合法郵件誤判為垃圾郵件。您的分類器設置了一個高的閾值,以確保只有非常確定的情況下才會將郵件標記為垃圾郵件。在這種情況下,以下哪個評估指標最重要?
A) Precision
B) Recall
C) F1 Score
D) ROC曲線
答案:A) Precision
解釋: 在這種情境下,Precision(精確率)最重要,因為您更關心的是不要將合法郵件錯誤標記為垃圾郵件。高Precision表示當模型認為郵件是垃圾郵件時,它很有把握是垃圾郵件。
問題2:
您正在比較兩個機器學習模型的性能,這些模型用於區分惡性腫瘤和良性腫瘤。在分類時,您希望找到一個平衡點,使模型既能夠識別盡可能多的惡性腫瘤,又能夠保持低偽陽性率。在這種情況下,以下哪個評估指標最有用?
A) Precision
B) Recall
C) F1 Score
D) ROC曲線
答案:D) ROC曲線
解釋: 在這種情境下,您需要評估模型在不同閾值下的性能,找到一個平衡點。ROC曲線可用於視覺化這種平衡,並根據需要調整閾值。
問題3:
您正在開發一個網絡入侵檢測系統,用於檢測可能的惡意網絡活動。在這個情境下,您更關心的是網絡攻擊中未被檢測到的情況,希望最大程度地捕獲真正的攻擊。在這種情況下,以下哪個評估指標最重要?
A) Precision
B) Recall
C) F1 Score
D) AUC
答案:B) Recall
解釋: 在這種情境下,Recall(召回率)最重要,因為您希望盡可能多地檢測到真正的攻擊,即使這意味著有些偽警報(低Precision)

 iThome鐵人賽
iThome鐵人賽