馬可夫決策過程( Markov Decision Process ,簡稱 MDP )
用來描述強化學習問題的數學框架,是建模智能代理在與環境互動的情境下如何做出決策的工具
-
狀態空間(State Space): S 是一個有限集合,代表所有可能的狀態
例如 S = {s1, s2, s3, ...},其中 s1、s2、s3 是不同的狀態
-
動作空間(Action Space): A 是一個有限集合,代表在每個狀態下代理可以執行的動作
例如 A = {a1, a2, a3, ...},其中 a1、a2、a3 是不同的動作
-
轉換機制(Transition Model): P( s' | s, a) 是轉換機制,它表示在狀態 s 下執行動作 a 後轉移到狀態 s' 的機率
P(s' | s, a),其中 s 和 s' 分別代表當前狀態和下一個狀態,a 代表執行的動作
-
獎勵函數(Reward Function): R( s ) 是獎勵函數,表示在狀態 s 下獲得的即時獎勵
-
策略(Policy): 策略 π 是從狀態到動作的映射,指定代理在每個狀態下應該選擇的動作
形式上表示為 π( a | s ),表示在狀態 s 下選擇動作 a 的概率
-
回報(Return): 回報 G( t ) 是代理在時間 t 開始後獲得的累積總獎勵
定義為 G( t ) = R( t ) + γ * R( t + 1 ) + γ ^ 2 * R( t + 2 ) + ... = Σ(γ ^ k * R( t + k )), k = 0 到 ∞
γ 是折扣因子,衡量未來獎勵的重要性,並確保收斂
-
值函數(Value Function): 值函數 V( s ) 表示代理從狀態 s 開始,按照策略 π 繼續執行下去,預期獲得的期望回報
用遞迴的方式定義為 V( s ) = Σπ( a | s ) * ΣP( s' | s, a ) * [R( s ) + γ * V( s' )]
意思是代理在狀態 s 下根據策略 π 選擇動作 a,然後根據轉換機制 P( s' | s, a ) 轉移到狀態 s',獲得即時獎勵 R( s ),然後預期繼續根據策略 π 繼續執行,計算期望值
《人工智能:一種現代的方法》《 Artificial Intelligence: A Modern Approach 》第 17.1 節序列式決策出現的玩具問題
世界
機器人可以向四個方向移動:上、下、左、右
是一個地圖大小 3x4 的平面
右上角的綠色鑽石代表終點線( +1 )
如果進入有紅色墳墓的方格,我們就會輸掉比賽並受到懲罰( -1 )
中間灰色格子是一面牆不可走( nan )
其他所有白色方塊都是正常的方塊,每次進入其中一個時,都會失去少量點數( -0.04 )
機器人從左下角開始
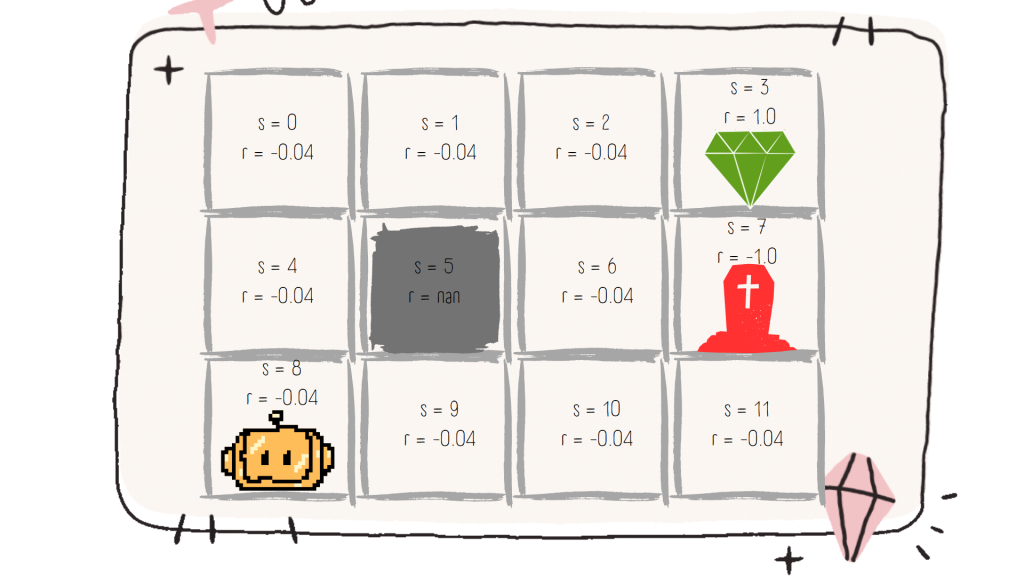
因此我們希望一路上走最少的方格來抵達終點,並且要避免紅色墳墓直接結束遊戲
代理
是放在這個世界中的機器人,它會四處尋找可能的移動,考慮可能移動的利弊,來做出下一步往哪移動,並執行移動
環境
環境就是上面的世界設置,所有東西的設置跟得分扣分
動作
對每個狀態 s,有四個可能的動作 A( s ) = { up, down, left, right },用 a 來表示動作
獎勵
對於不同的狀態,有 +1 、 -1 或 -0.04,獎勵依賴於狀態,而從狀態到獎勵的函式表示為
例如當 s = 4 時,r = R(s) = R(4)= -0.04
不管從上下左右進入這個方格,都會得到相同的( -0.04 )獎勵
累加獎勵
最終積分(總獎勵)是從鑽石或墳墓的積分和沿途方塊的積分相加,在 MDP 中,假設可以將這些獎勵加在一起
轉換模型
假設我們的世界是確定性的,那預期的移動方向總是會實現
參考資料
https://communeit.medium.com/%E4%BA%BA%E5%B7%A5%E6%99%BA%E6%85%A7-%E9%A6%AC%E5%8F%AF%E5%A4%AB%E6%B1%BA%E7%AD%96mdp%E9%81%8E%E7%A8%8B%E5%9F%BA%E6%9C%AC%E6%A6%82%E5%BF%B5%E8%A9%B3%E8%A7%A3-f24cf2a1a622
https://www.tinytsunami.info/markov-decision-process/
https://zh.wikipedia.org/zh-tw/%E9%A6%AC%E5%8F%AF%E5%A4%AB%E6%B1%BA%E7%AD%96%E9%81%8E%E7%A8%8B


 iThome鐵人賽
iThome鐵人賽