匯入需要套件
import re
import requests
import json
import MySQLdb
from bs4 import BeautifulSoup
from sqlalchemy import create_engine
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
設定headers模擬人為操作
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
如何找到headers?
在目標網頁下按F12進入開發者模式,隨選一個頁面(下方選擇名稱為all的頁面),接著在User-Agent項目可找到headers,如此就可以偽裝人為正常登入。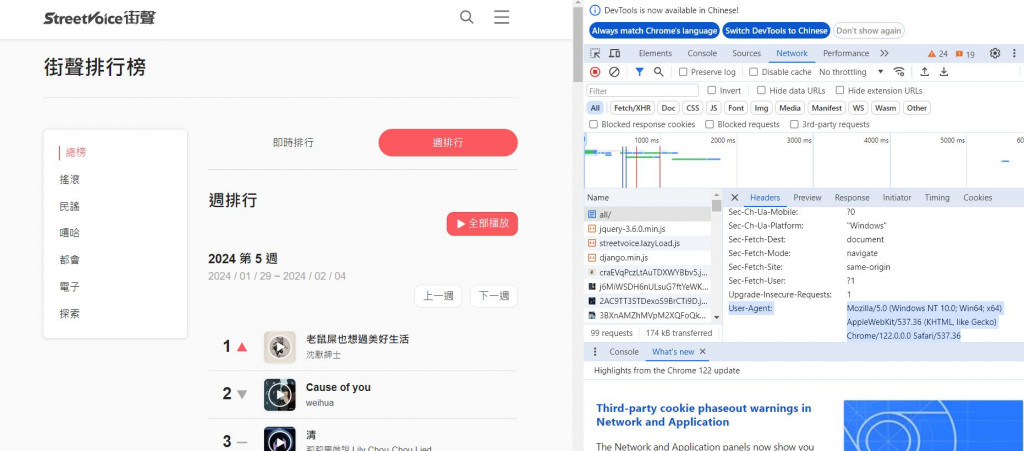
爬取週排行前50名歌曲清單
連結MySQL,以便後續裝取的資料直接存入MySQL中。
# Credentials to database connection
hostname="localhost"
dbname="street_rank"
uname="OOO"
pwd="XXXXXX"
# Create SQLAlchemy engine to connect to MySQL Database
engine = create_engine("mysql://{user}:{pw}@{host}/{db}"
.format(host=hostname, db=dbname, user=uname, pw=pwd)).connect()
針對要抓取數據頁面的網址,設定GET的request。
url = 'https://streetvoice.com/music/charts/weekly/2024/'+str(period)+'/all/'
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
# use beautifulsoup to analyze html
soup = BeautifulSoup(response.text, 'html.parser')
爬取前50名的名次、作品名稱、作品連結網址、曲風類別、作曲者及作曲者連結網址。
在F12開發者模式中,知道上述內容被歸類在標籤”div”與級別”work-item-info”中。
# scrap the Top 50 work and their link
rank_work = soup.find_all('div', {'class':'work-item-info'})
儲存至MySQL中
# Convert dataframe to sql table
df.to_sql(date, engine, index=False, if_exists='replace')
列出部分歌曲(前五名)資訊如下: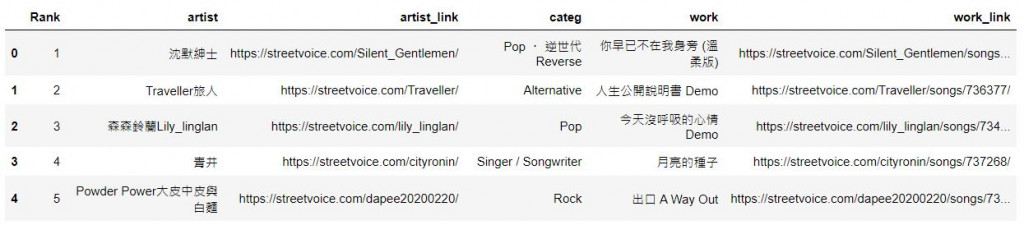
 AlbertShiu
AlbertShiu

 iThome鐵人賽
iThome鐵人賽