在搜尋欄輸入S3,前往該頁面
點擊建立儲存貯體
命名儲存貯體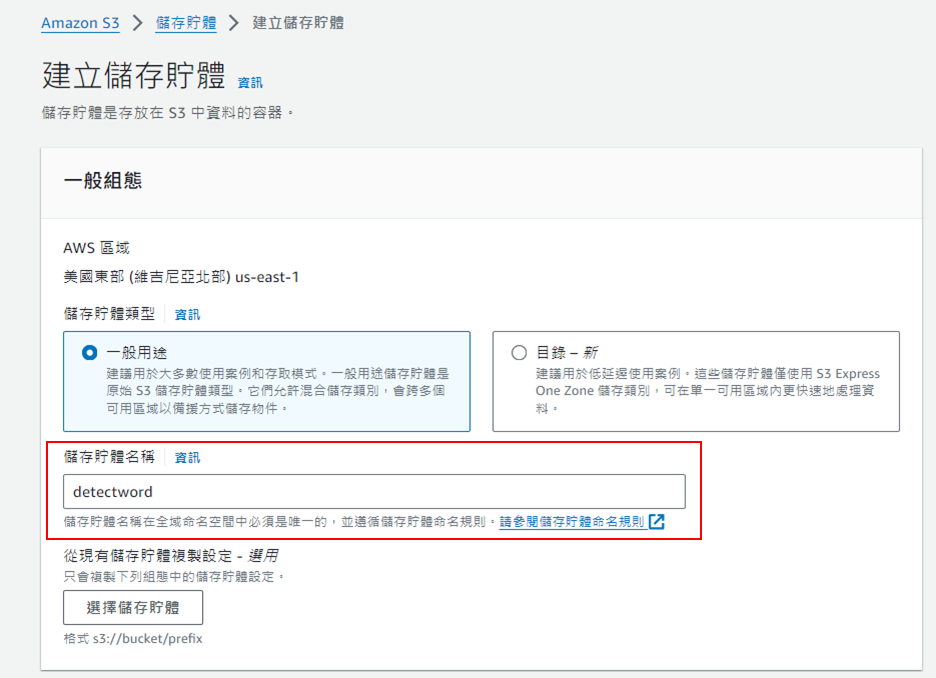
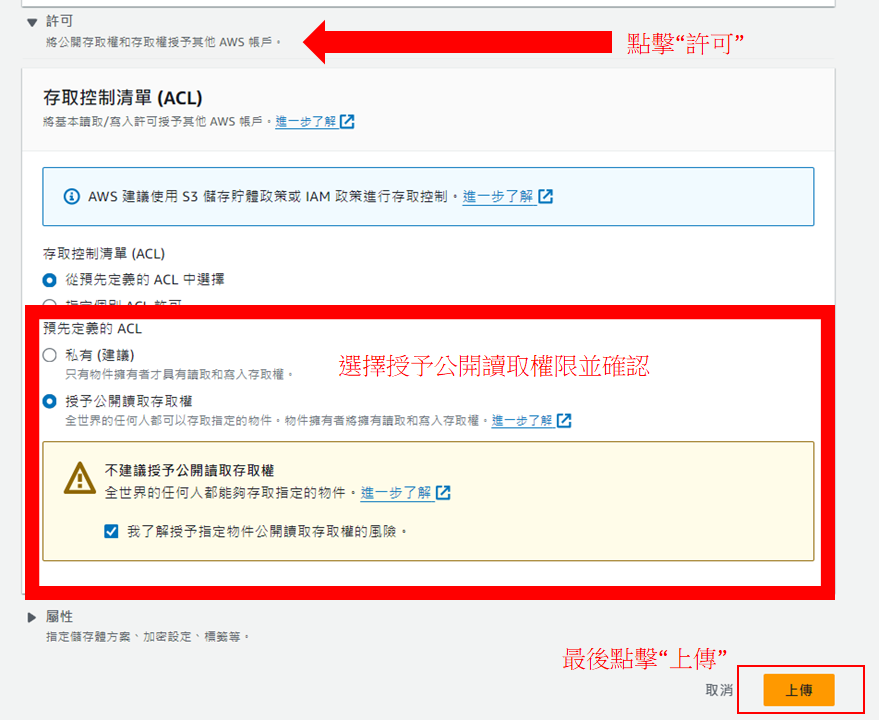
啟用ACL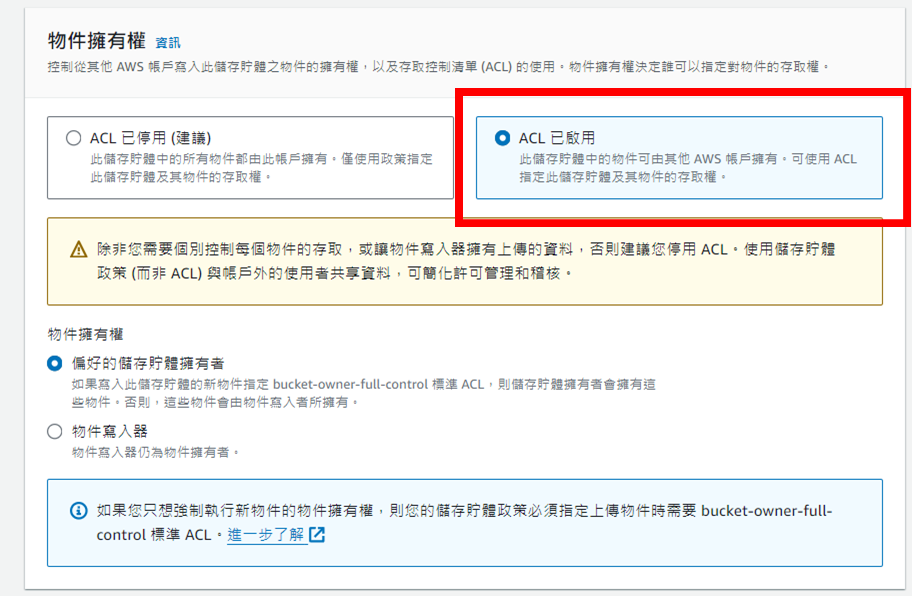
解除存取權限的封鎖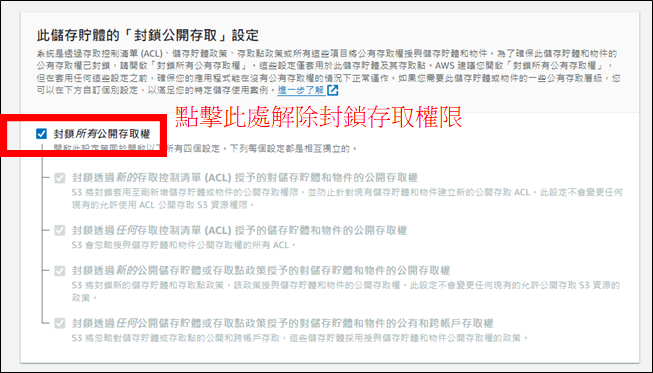
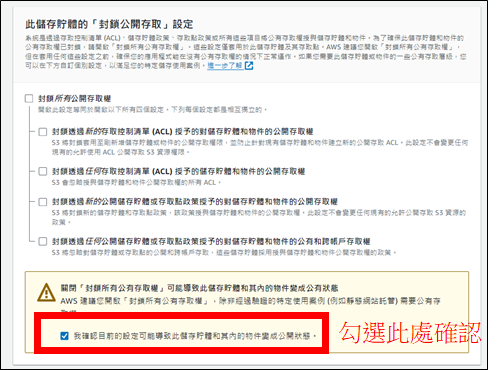
接著點擊"建立儲存貯體",便可看到剛剛創建的儲存貯體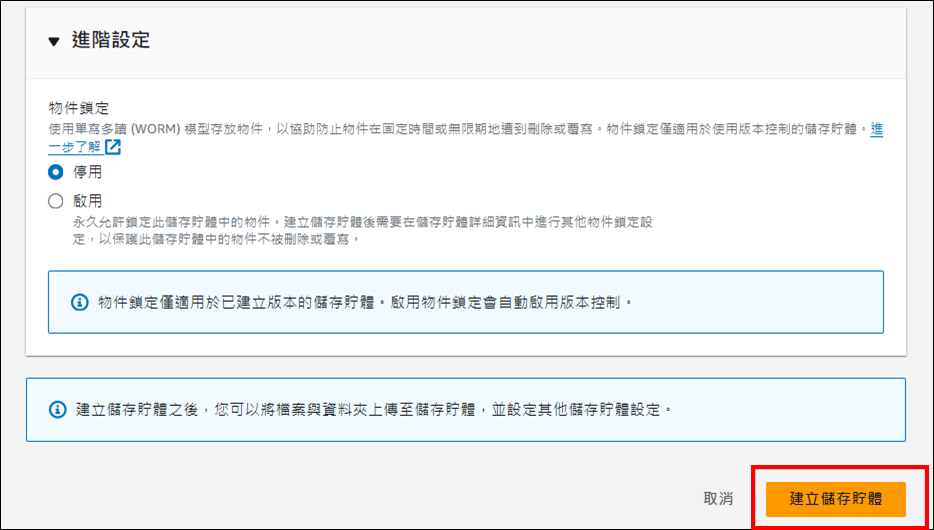
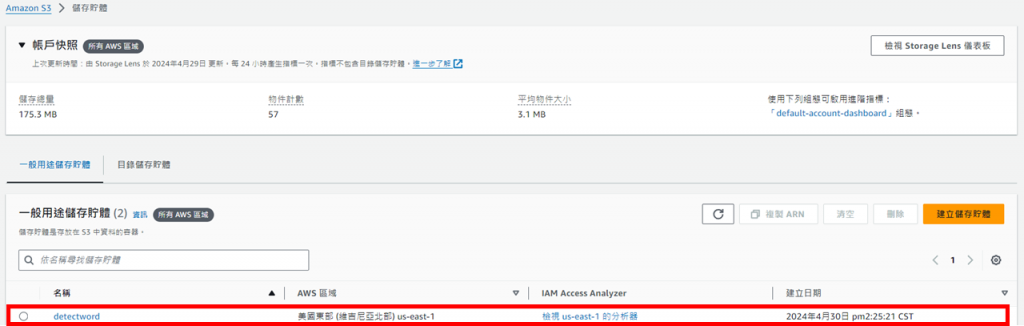
進入儲存貯體內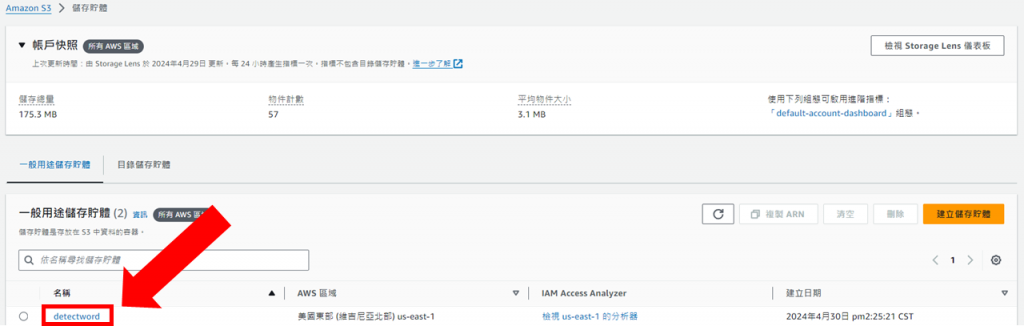
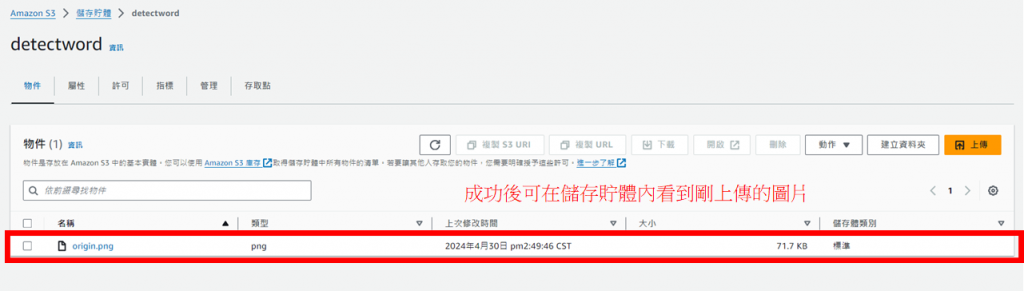
點擊上傳,選擇圖片並修改許可權後上傳,成功後即可看到儲存貯體內存在剛上傳的圖片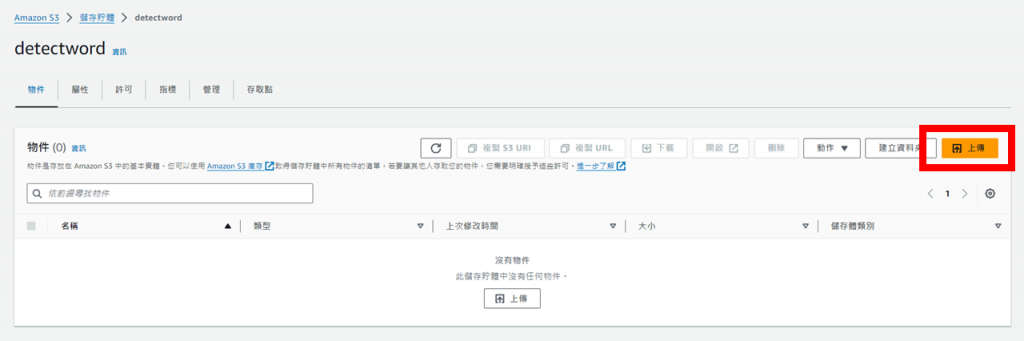
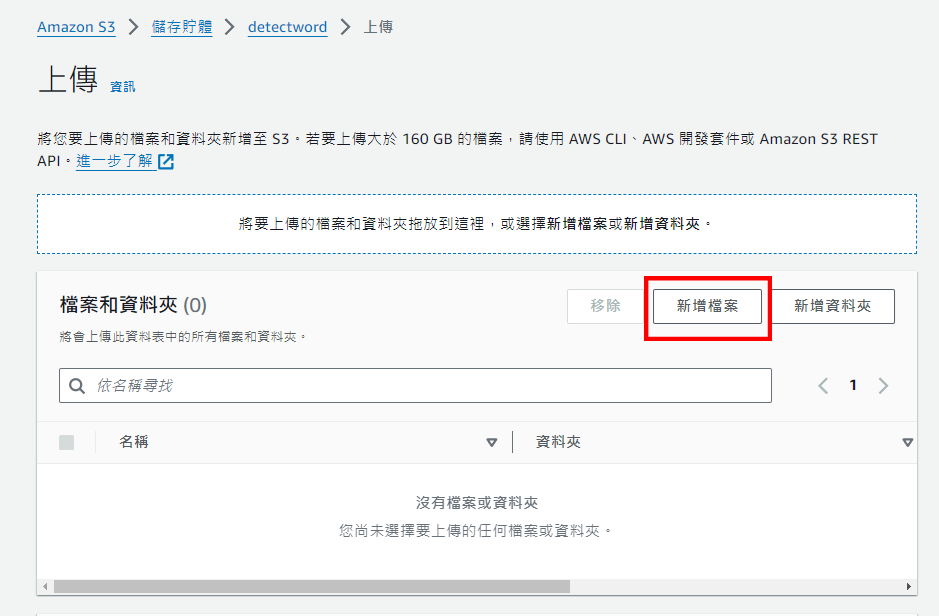

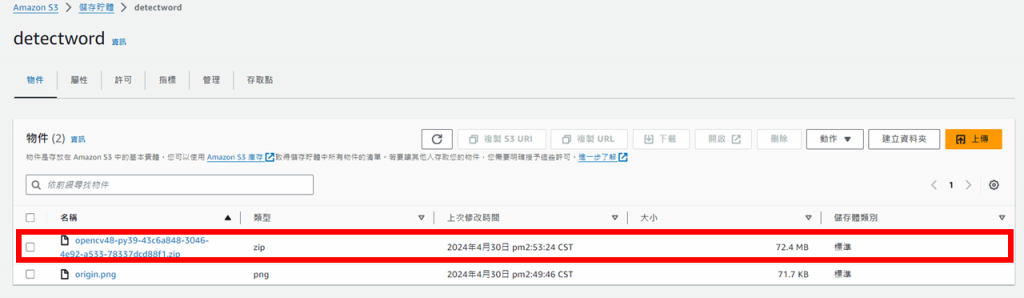
用同樣的步驟上傳opencv函式庫(為了之後Lambda能使用opencv)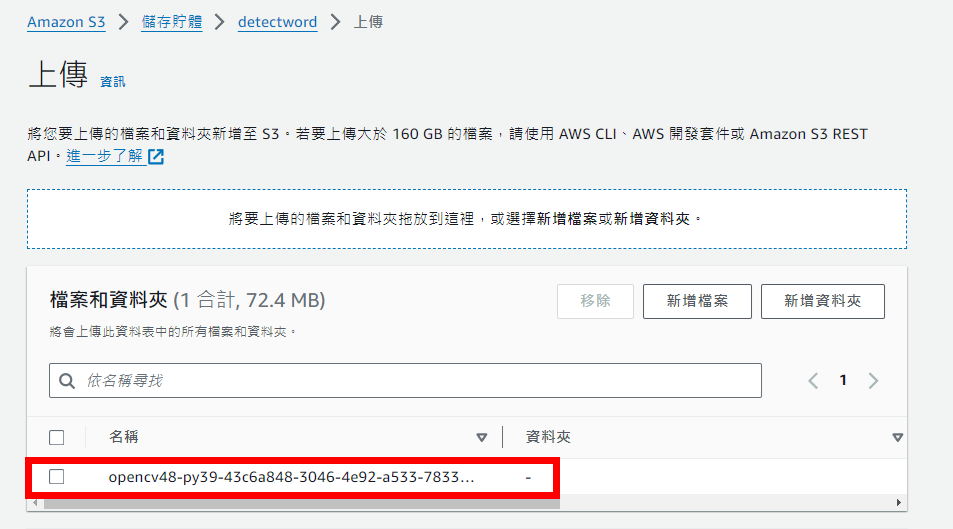
建立Lambda
在搜尋欄裡輸入Lambda,前往該頁面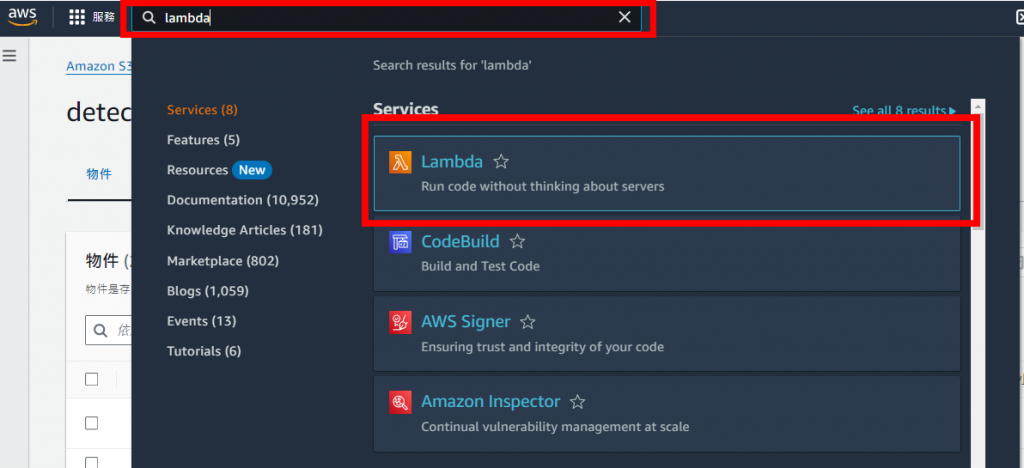
點擊建立函式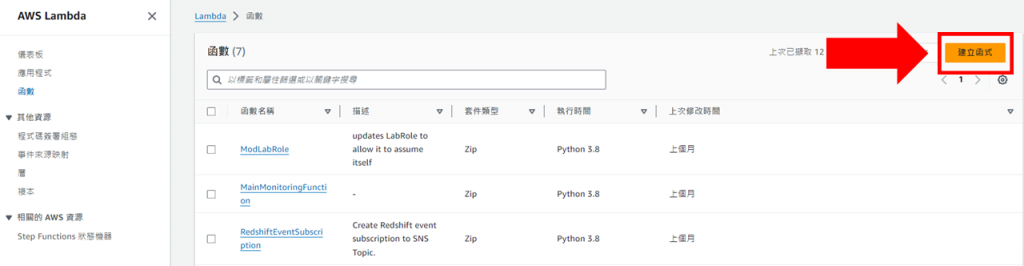
命名此函式,並修改要使用的程式語言(對應到opencv的版本)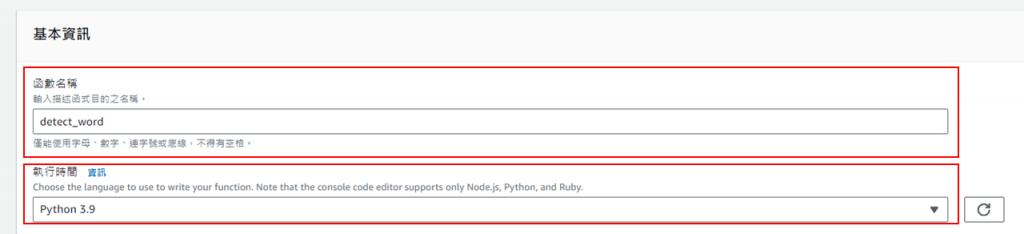
修改執行角色為LabRole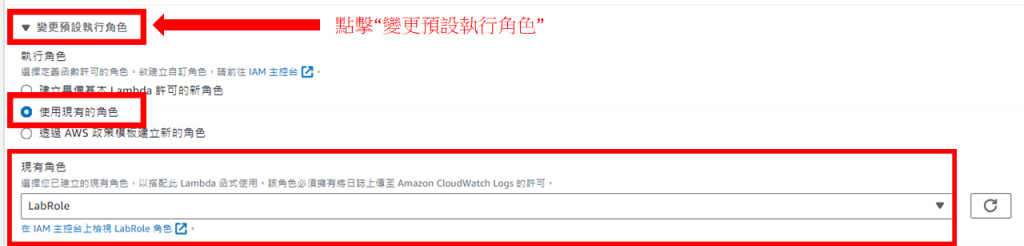
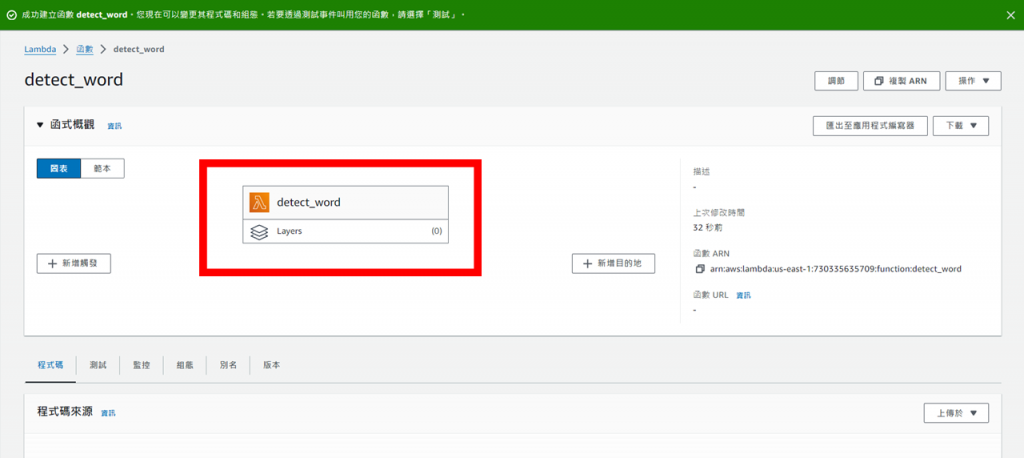
完成上述步驟後點擊建立函式,成功後便可看到剛建立的函式
import json
import base64
import boto3
from datetime import datetime
import numpy as np
import cv2
import os
import time
def lambda_handler(event, context):
s3 = boto3.client('s3')
#bucket_name要改為自己儲存貯體的名稱
#file_name則是要從儲存貯體拿來辨識的圖片名稱
bucket_name = 'detectword'
file_name = "origin.png"
img_data = s3.get_object(Bucket=bucket_name, Key=file_name)
image_data = img_data['Body'].read()
nparr = np.frombuffer(image_data, np.uint8)
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
print('Bucket name: {}'.format(bucket_name))
print('Upload file name: {}'.format(file_name))
#get current unix time
created = int(datetime.now().timestamp())
#OCR
client=boto3.client('rekognition')
response=client.detect_text(Image={'S3Object':{'Bucket':bucket_name,'Name':file_name}})
print(json.dumps(response))
# 获取文本区域的信息
text_detections = response["TextDetections"]
# 绘制矩形
for detection in text_detections:
# 检查是否检测到了文本
if "Geometry" in detection and "BoundingBox" in detection["Geometry"]:
box = detection["Geometry"]["BoundingBox"]
x = int(box["Left"] * image.shape[1])
y = int(box["Top"] * image.shape[0])
w = int(box["Width"] * image.shape[1])
h = int(box["Height"] * image.shape[0])
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imwrite('/tmp/image.jpg', image)
s3.upload_file('/tmp/image.jpg', bucket_name, f"result.png")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
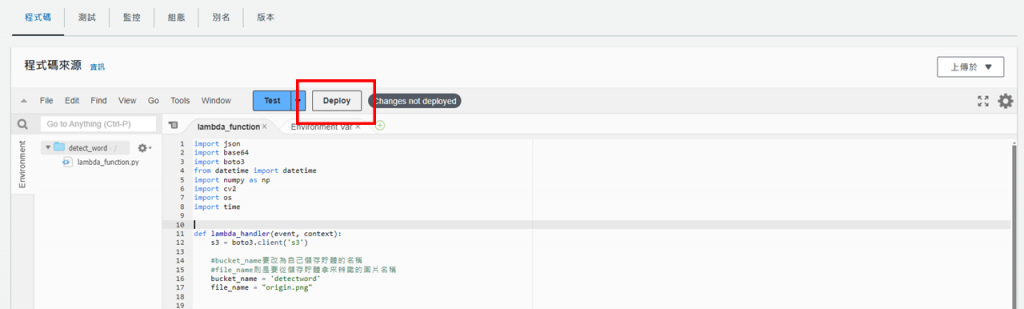
接著,先回到S3創建的儲存貯體內複製opencv的物件URL,在下一步會用到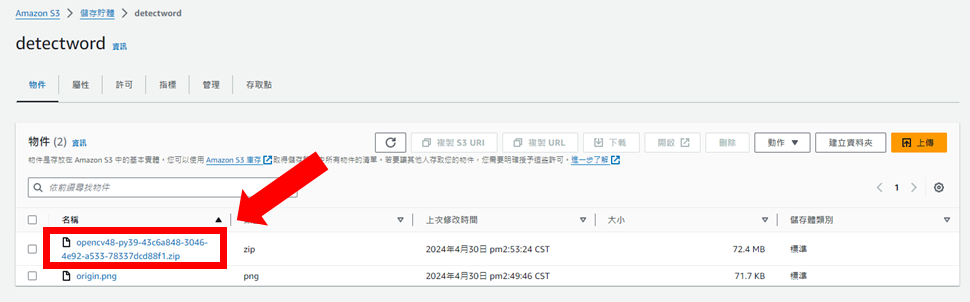
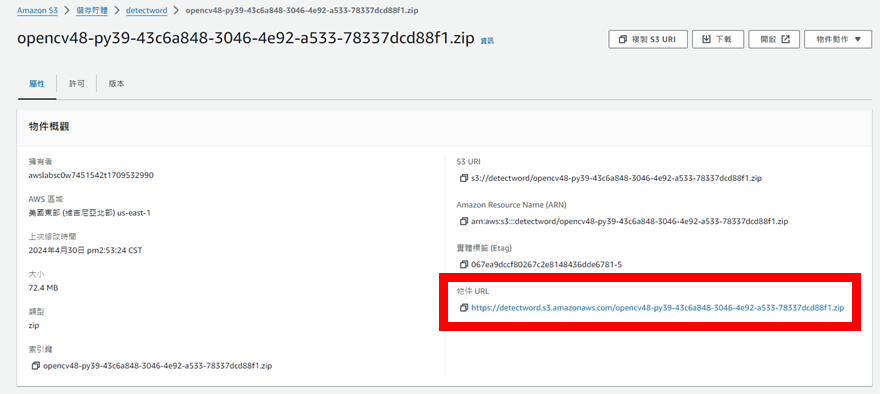
完成後回到Lambda,點擊左上角的這個圖標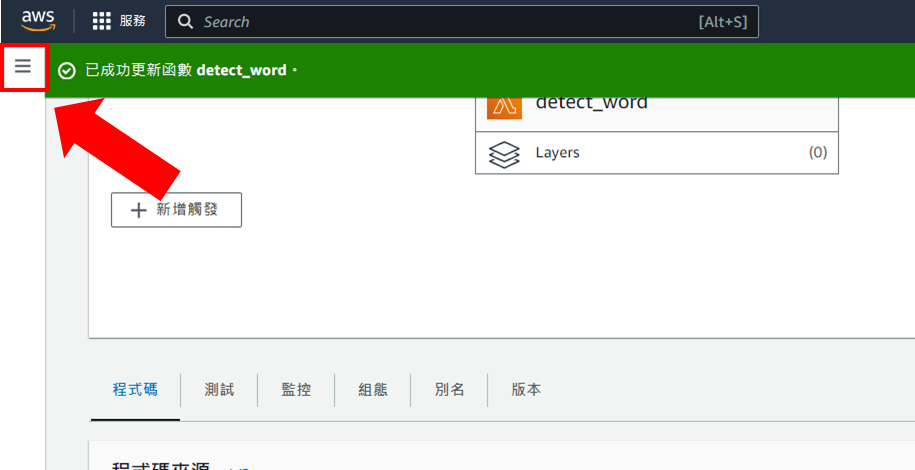
點擊"層",並開始建立Layer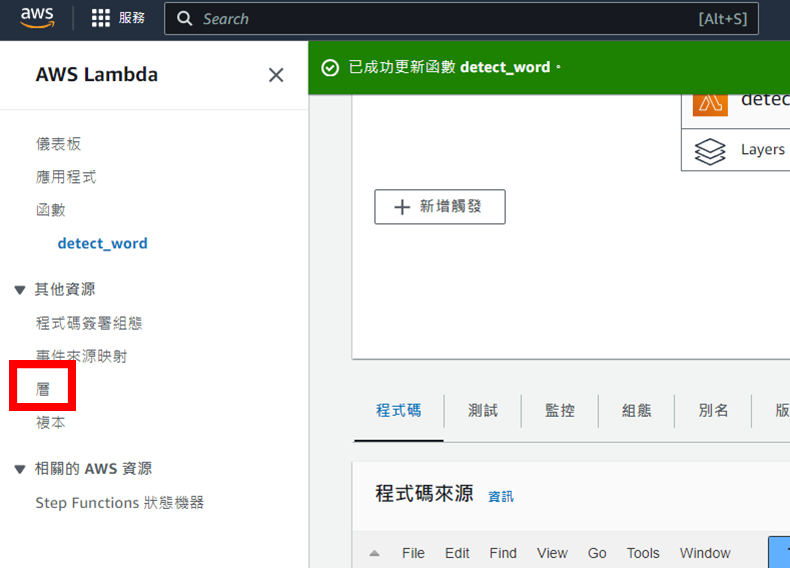

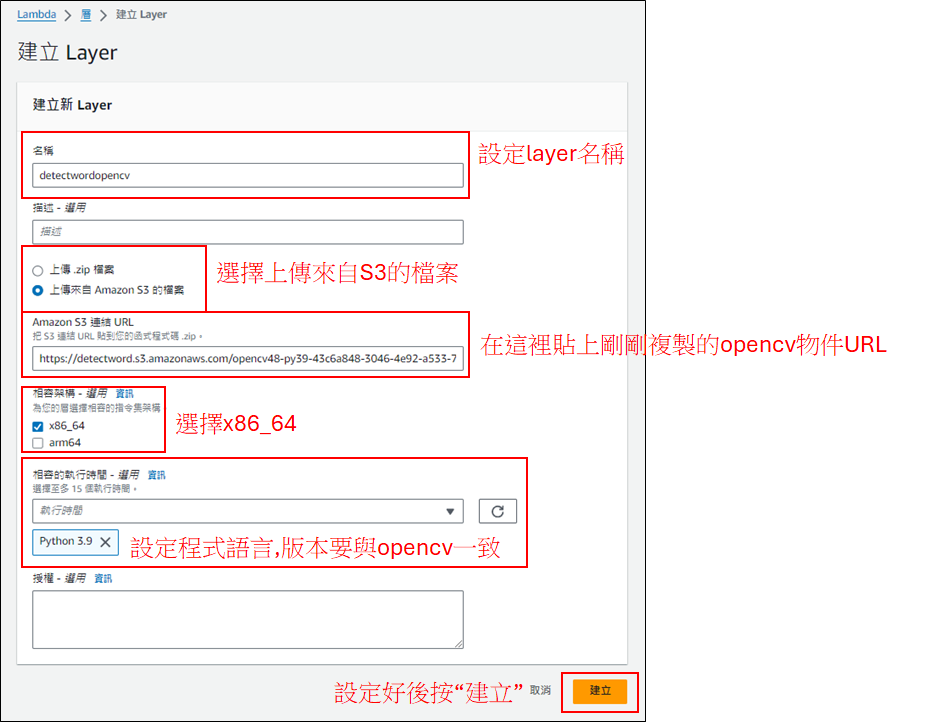
建立成功後回到Lambda的程式設計頁面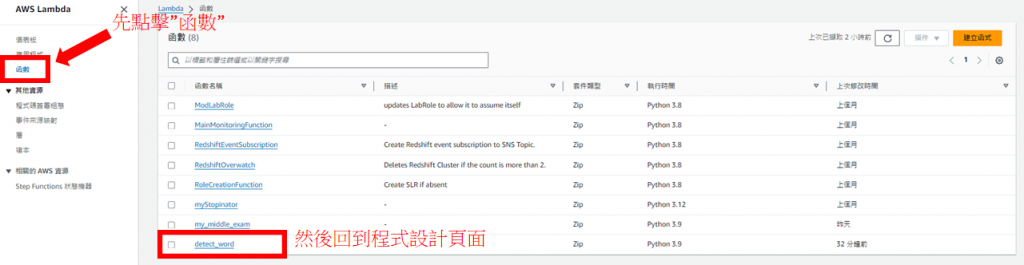
將頁面滑到最下面,開始將剛剛創立的Layer新增到此函式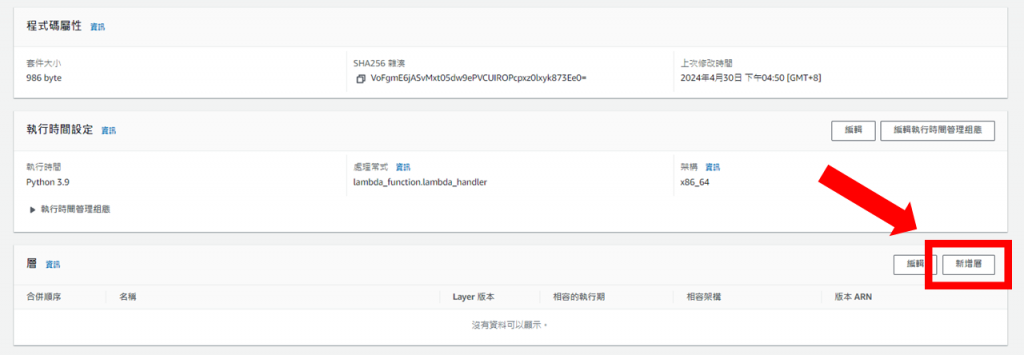
點擊"自訂Layer",並選擇剛剛建立的Layer和版本,接著點擊"新增"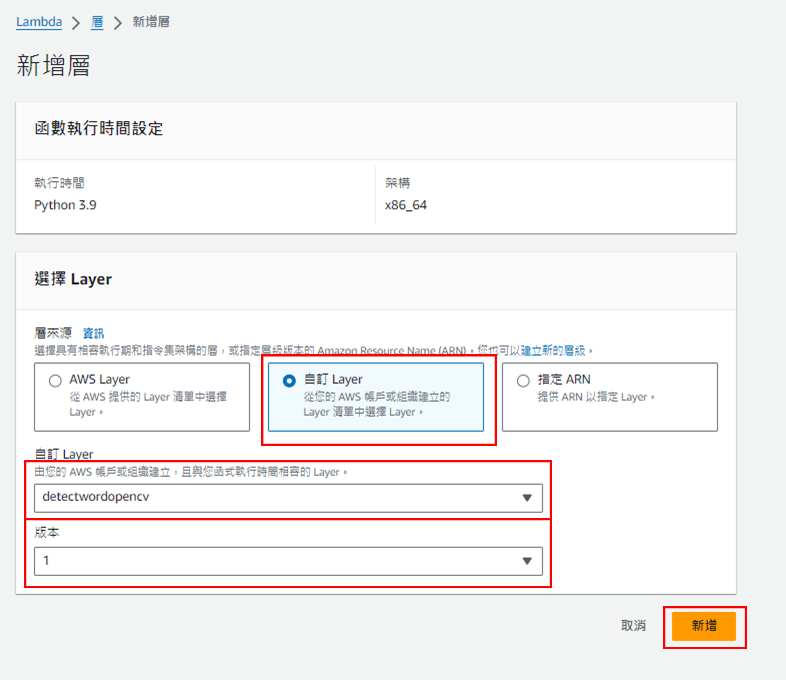
完成後會回到程式設計頁面,接著點擊"TEST"建立測試用事件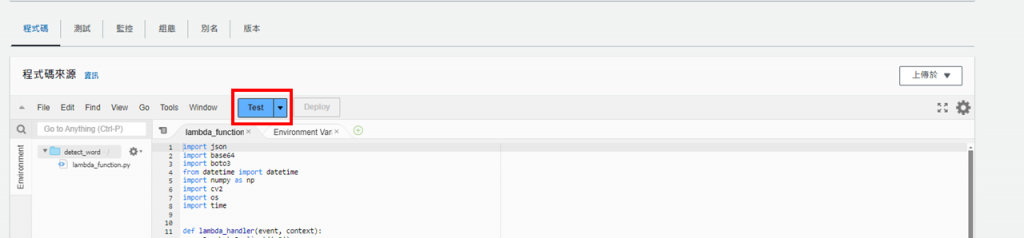
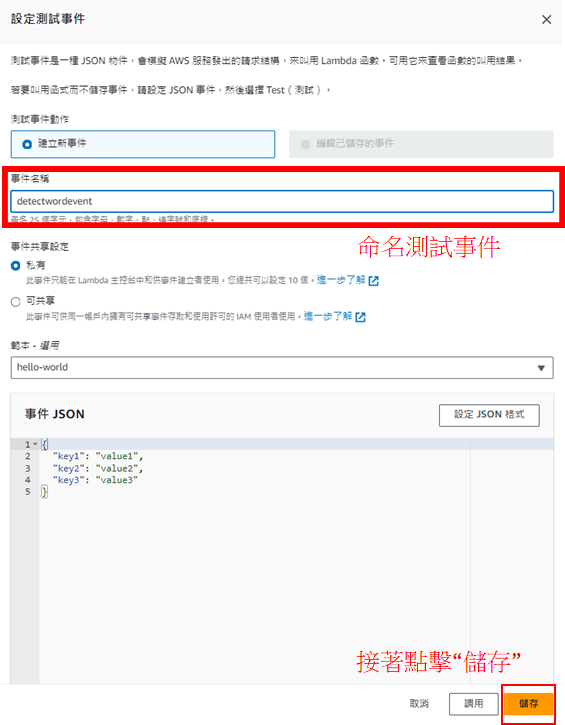
接著,為了預防程式運作時長過久而報錯,要先修改程式運作時間
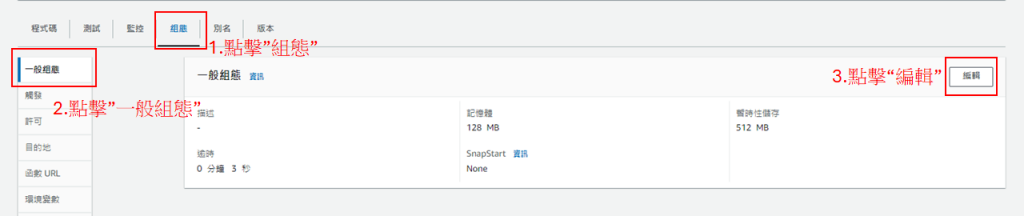
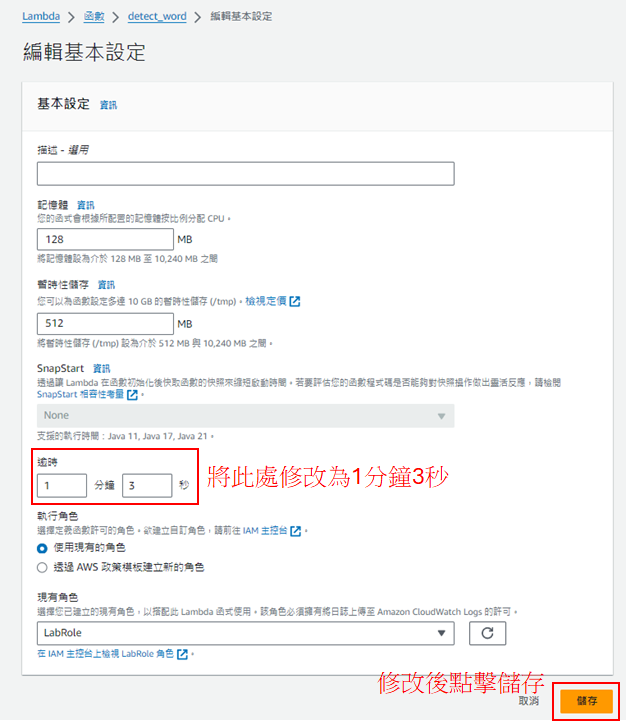
完成後回到"程式碼",點擊"TEST",若成功運作則會回傳'Hello from Lambda!',否則會出現error
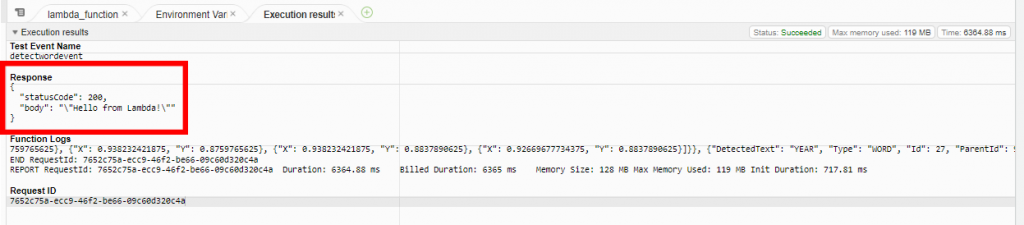
若成功運作的話,回到S3的儲存貯體內會看到處理後的圖(result.png)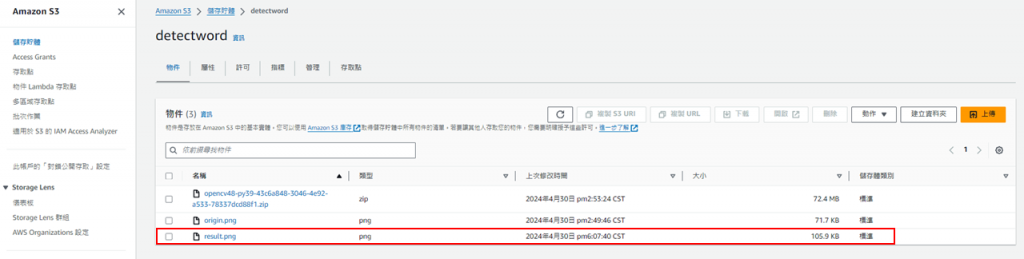
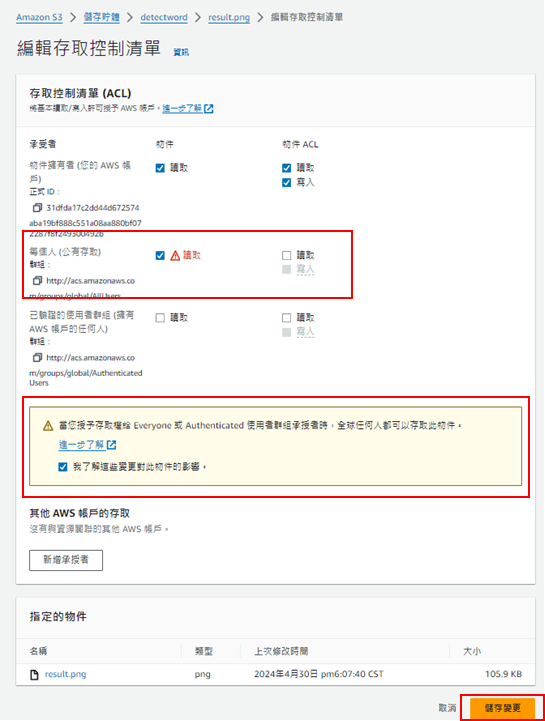
點進去後要先到"許可"編輯物件的讀取權,修改好後儲存變更(若沒修改則無法下載結果圖)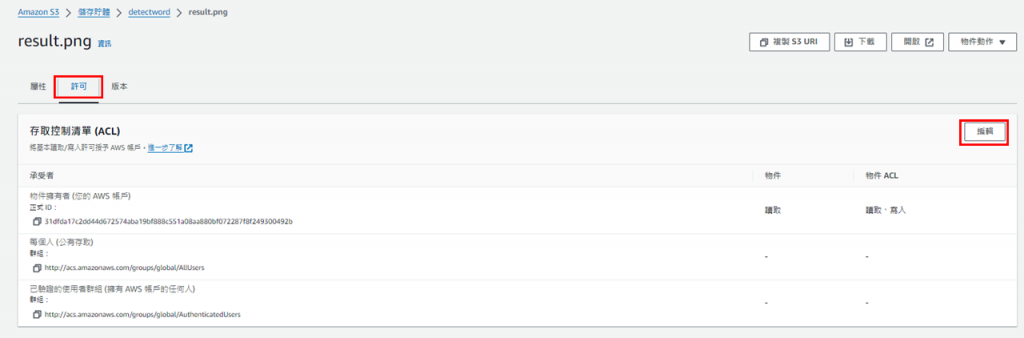
接著點擊"物件URL",便能下載結果圖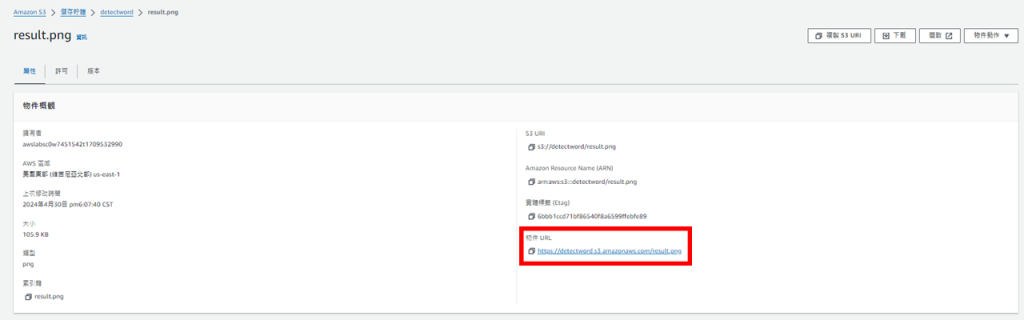

文字辨識: https://aws.amazon.com/tw/rekognition/
Lambda: https://docs.aws.amazon.com/zh_tw/lambda/latest/dg/lambda-python.html
框出文字: https://blog.csdn.net/weixin_38145317/article/details/89497616
 bob103
bob103
